
Keras上實現AutoEncoder自編碼器
阿新 • • 發佈:2019-01-23
一、自編碼器簡介
無監督特徵學習(Unsupervised Feature Learning)是一種仿人腦的對特徵逐層抽象提取的過程,學習過程中有兩點:一是無監督學習,即對訓練資料不需要進行標籤化標註,這種學習是對資料內容的組織形式的學習,提取的是頻繁出現的特徵;二是逐層抽象,特徵是需要不斷抽象的。
自編碼器(AutoEncoder),即可以使用自身的高階特徵自我編碼,自編碼器其實也是一種神經網路,其輸入和輸出是一致的,藉助了稀疏編碼的思想,目標是使用稀疏的高階特徵重新組合來重構自己。
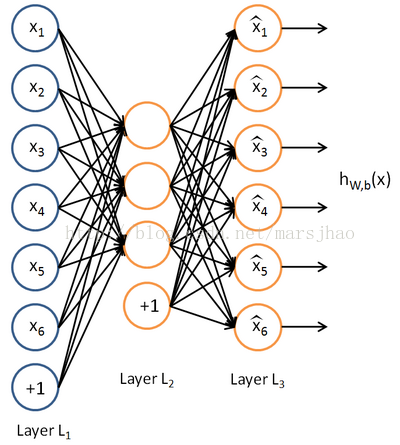
二、完整程式碼
import numpy as np np.random.seed(1337) # for reproducibility from keras.datasets import mnist from keras.models import Model #泛型模型 from keras.layers import Dense, Input import matplotlib.pyplot as plt # X shape (60,000 28x28), y shape (10,000, ) (x_train, _), (x_test, y_test) = mnist.load_data() # 資料預處理 x_train = x_train.astype('float32') / 255. - 0.5 # minmax_normalized x_test = x_test.astype('float32') / 255. - 0.5 # minmax_normalized x_train = x_train.reshape((x_train.shape[0], -1)) x_test = x_test.reshape((x_test.shape[0], -1)) print(x_train.shape) print(x_test.shape) # 壓縮特徵維度至2維 encoding_dim = 2 # this is our input placeholder input_img = Input(shape=(784,)) # 編碼層 encoded = Dense(128, activation='relu')(input_img) encoded = Dense(64, activation='relu')(encoded) encoded = Dense(10, activation='relu')(encoded) encoder_output = Dense(encoding_dim)(encoded) # 解碼層 decoded = Dense(10, activation='relu')(encoder_output) decoded = Dense(64, activation='relu')(decoded) decoded = Dense(128, activation='relu')(decoded) decoded = Dense(784, activation='tanh')(decoded) # 構建自編碼模型 autoencoder = Model(inputs=input_img, outputs=decoded) # 構建編碼模型 encoder = Model(inputs=input_img, outputs=encoder_output) # compile autoencoder autoencoder.compile(optimizer='adam', loss='mse') # training autoencoder.fit(x_train, x_train, epochs=20, batch_size=256, shuffle=True) # plotting encoded_imgs = encoder.predict(x_test) plt.scatter(encoded_imgs[:, 0], encoded_imgs[:, 1], c=y_test, s=3) plt.colorbar() plt.show()
三、程式解讀
自編碼,簡單來說就是把輸入資料進行一個壓縮和解壓縮的過程。原來有很多特徵,壓縮成幾個來代表原來的資料,解壓之後恢復成原來的維度,再和原資料進行比較。它是一種非監督演算法,只需要輸入資料,解壓縮之後的結果與原資料本身進行比較。程式的主要功能是把 datasets.mnist 資料的 28*28=784 維的資料,壓縮成 2 維的資料,然後在一個二維空間中可視化出分類的效果。
首先,匯入資料並進行資料預處理,本例使用Model模組的Keras的泛化模型來進行模型搭建,便於我們從模型中間匯出資料並進行視覺化。進行模型搭建的時候,注意要進行逐層特徵提取,最終壓縮至2維,解碼的過程要跟編碼過程一致相反。隨後對Autoencoder和encoder分別建模,編譯、訓練。將編碼模型的預測結果通過Matplotlib可視化出來,就可以看到原資料的二維編碼結果在二維平面上的聚類效果,還是很明顯的。
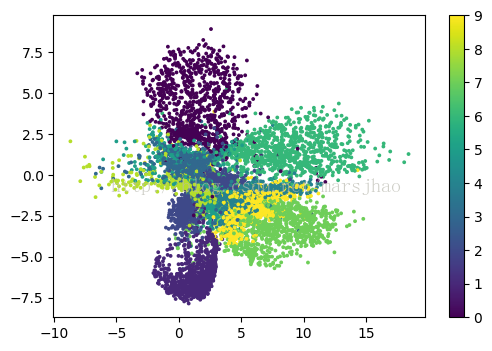
最後看到視覺化的結果,自編碼模型可以把這幾個數字給區分開來,我們可以用自編碼這個過程來作為一個特徵壓縮的方法,和PCA的功能一樣,效果要比它好一些,因為它是非線性的結構。