
NUMA架構的CPU -- 你真的用好了麼?
from: http://cenalulu.github.io/linux/numa/
本文從NUMA的介紹引出常見的NUMA使用中的陷阱,繼而討論對於NUMA系統的優化方法和一些值得關注的方向。
NUMA簡介
這部分將簡要介紹下NUMA架構的成因和具體原理,已經瞭解的讀者可以直接跳到第二節。
為什麼要有NUMA
在NUMA架構出現前,CPU歡快的朝著頻率越來越高的方向發展。受到物理極限的挑戰,又轉為核數越來越多的方向發展。如果每個core的工作性質都是share-nothing(類似於map-reduce的node節點的作業屬性),那麼也許就不會有NUMA。由於所有CPU Core都是通過共享一個北橋來讀取記憶體,隨著核數如何的發展,北橋在響應時間上的效能瓶頸越來越明顯。於是,聰明的硬體設計師們,先到了把記憶體控制器(原本北橋中讀取記憶體的部分)也做個拆分,平分到了每個die上。於是NUMA就出現了!
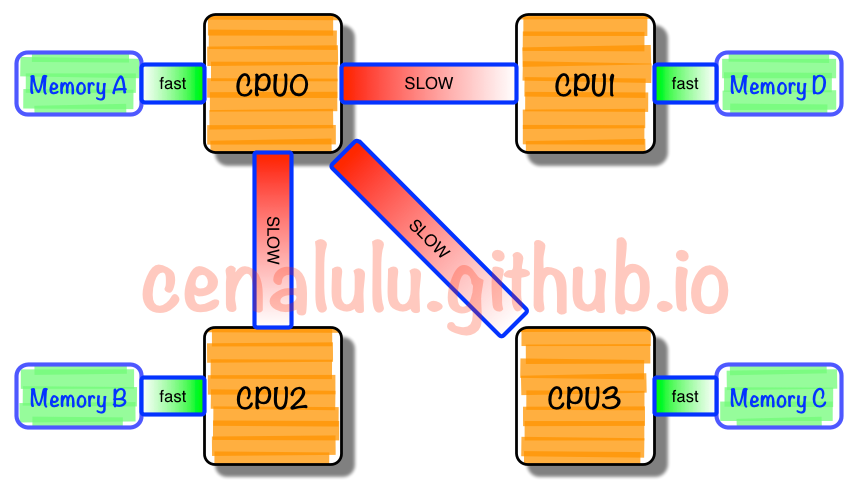
NUMA是什麼
NUMA中,雖然記憶體直接attach在CPU上,但是由於記憶體被平均分配在了各個die上。只有當CPU訪問自身直接attach記憶體對應的實體地址時,才會有較短的響應時間(後稱Local
Access)。而如果需要訪問其他CPU attach的記憶體的資料時,就需要通過inter-connect通道訪問,響應時間就相比之前變慢了(後稱Remote
Access)。所以NUMA(Non-Uniform Memory Access)就此得名。
我們需要為NUMA做什麼
假設你是Linux教父Linus,對於NUMA架構你會做哪些優化?下面這點是顯而易見的:
既然CPU只有在Local-Access時響應時間才能有保障,那麼我們就儘量把該CPU所要的資料集中在他local的記憶體中就OK啦~
沒錯,事實上Linux識別到NUMA架構後,預設的記憶體分配方案就是:優先嚐試在請求執行緒當前所處的CPU的Local記憶體上分配空間。如果local記憶體不足,優先淘汰local記憶體中無用的Page(Inactive,Unmapped)。
那麼,問題來了。。。
NUMA的“七宗罪”
幾乎所有的運維都會多多少少被NUMA坑害過,讓我們看看究竟有多少種在NUMA上栽的方式:
究其原因幾乎都和:“因為CPU親和策略導致的記憶體分配不平均”及“NUMA Zone Claim記憶體回收”有關,而和資料庫種類並沒有直接聯絡。所以下文我們就拿MySQL為例,來看看重記憶體操作應用在NUMA架構下到底會出現什麼問題。
MySQL在NUMA架構上會出現的問題
幾乎所有NUMA + MySQL關鍵字的搜尋結果都會指向:Jeremy Cole大神的兩篇文章
大神解釋的非常詳盡,有興趣的讀者可以直接看原文。博主這裡做一個簡單的總結:
- CPU規模因摩爾定律指數級發展,而匯流排發展緩慢,導致多核CPU通過一條匯流排共享記憶體成為瓶頸
- 於是NUMA出現了,CPU平均劃分為若干個Chip(不多於4個),每個Chip有自己的記憶體控制器及記憶體插槽
- CPU訪問自己Chip上所插的記憶體時速度快,而訪問其他CPU所關聯的記憶體(下文稱Remote Access)的速度相較慢三倍左右
- 於是Linux核心預設使用CPU親和的記憶體分配策略,使記憶體頁儘可能的和呼叫執行緒處在同一個Core/Chip中
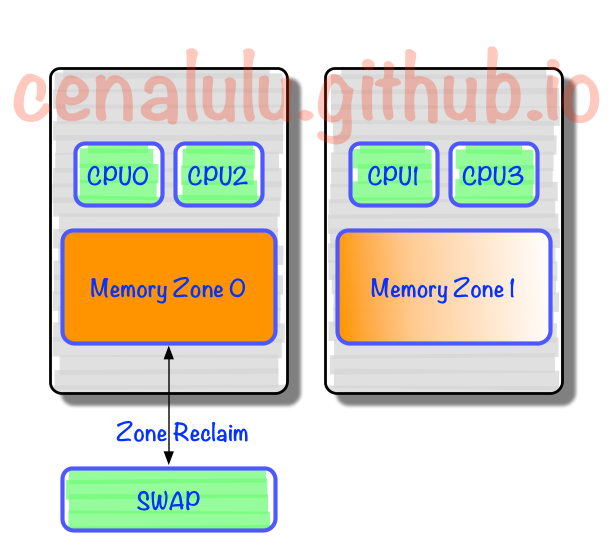
- 由於記憶體頁沒有動態調整策略,使得大部分記憶體頁都集中在
CPU 0上 - 又因為
Reclaim預設策略優先淘汰/Swap本Chip上的記憶體,使得大量有用記憶體被換出 - 當被換出頁被訪問時問題就以資料庫響應時間飆高甚至阻塞的形式出現了
解決方案
Jeremy Cole大神推薦的三個方案如下,如果想詳細瞭解可以閱讀 原文
numactl --interleave=all- 在MySQL程序啟動前,使用
sysctl -q -w vm.drop_caches=3清空檔案快取所佔用的空間 - Innodb在啟動時,就完成整個
Innodb_buffer_pool_size的記憶體分配
不過這種三合一的解決方案只是減少了NUMA記憶體分配不均,導致的MySQL SWAP問題出現的可能性。如果當系統上其他程序,或者MySQL本身需要大量記憶體時,Innodb Buffer Pool的那些Page同樣還是會被Swap到儲存上。於是又在這基礎上出現了另外幾個進階方案
- 配置
vm.zone_reclaim_mode = 0使得記憶體不足時去remote memory分配優先於swap out local page echo -15 > /proc/<pid_of_mysqld>/oom_adj調低MySQL程序被OOM_killer強制Kill的可能- 對MySQL使用Huge Page(黑魔法,巧用了Huge Page不會被swap的特性)
重新審視問題
如果本文寫到這裡就這麼結束了,那和搜尋引擎結果中大量的Step-by-Step科普帖沒什麼差別。雖然我們用了各種引數調整減少了問題發生概率,那麼真的就徹底解決了這個問題麼?問題根源究竟是什麼?讓我們回過頭來重新審視下這個問題:
NUMA Interleave真的好麼?
為什麼Interleave的策略就解決了問題?
借用兩張 Carrefour效能測試 的結果圖,可以看到幾乎所有情況下Interleave模式下的程式效能都要比預設的親和模式要高,有時甚至能高達30%。究其根本原因是Linux伺服器的大多數workload分佈都是隨機的:即每個執行緒在處理各個外部請求對應的邏輯時,所需要訪問的記憶體是在物理上隨機分佈的。而Interleave模式就恰恰是針對這種特性將記憶體page隨機打散到各個CPU
Core上,使得每個CPU的負載和Remote Access的出現頻率都均勻分佈。相較NUMA預設的記憶體分配模式,死板的把記憶體都優先分配線上程所在Core上的做法,顯然普遍適用性要強很多。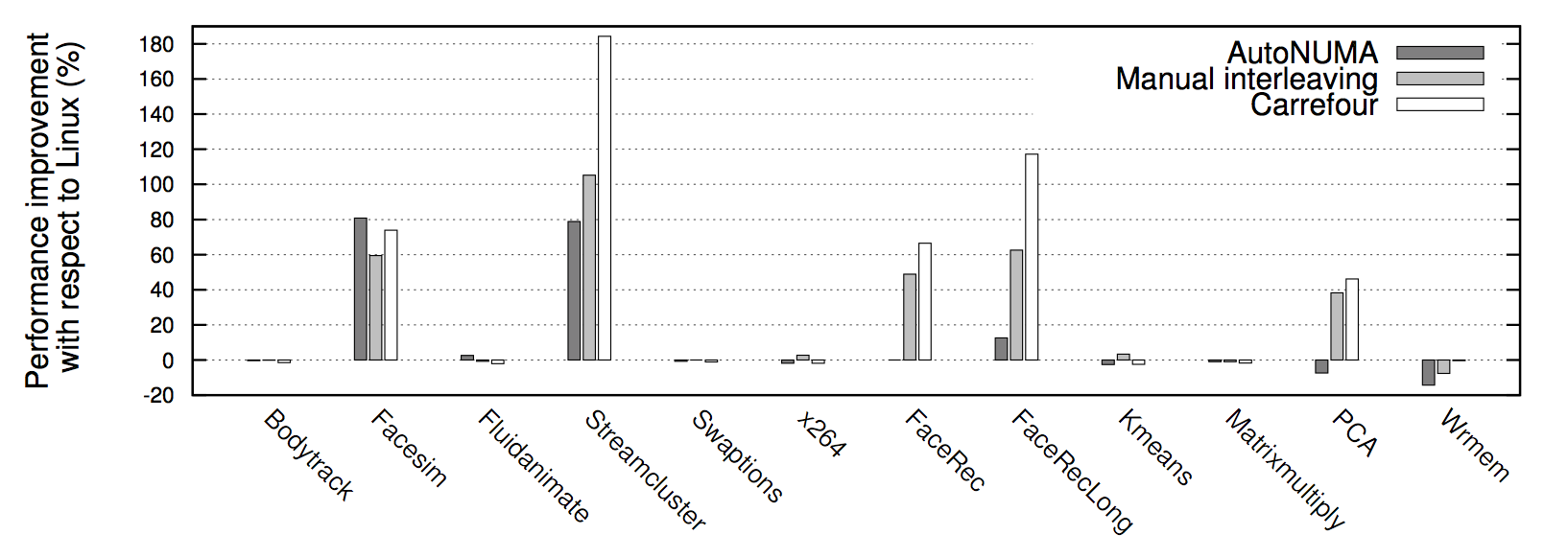
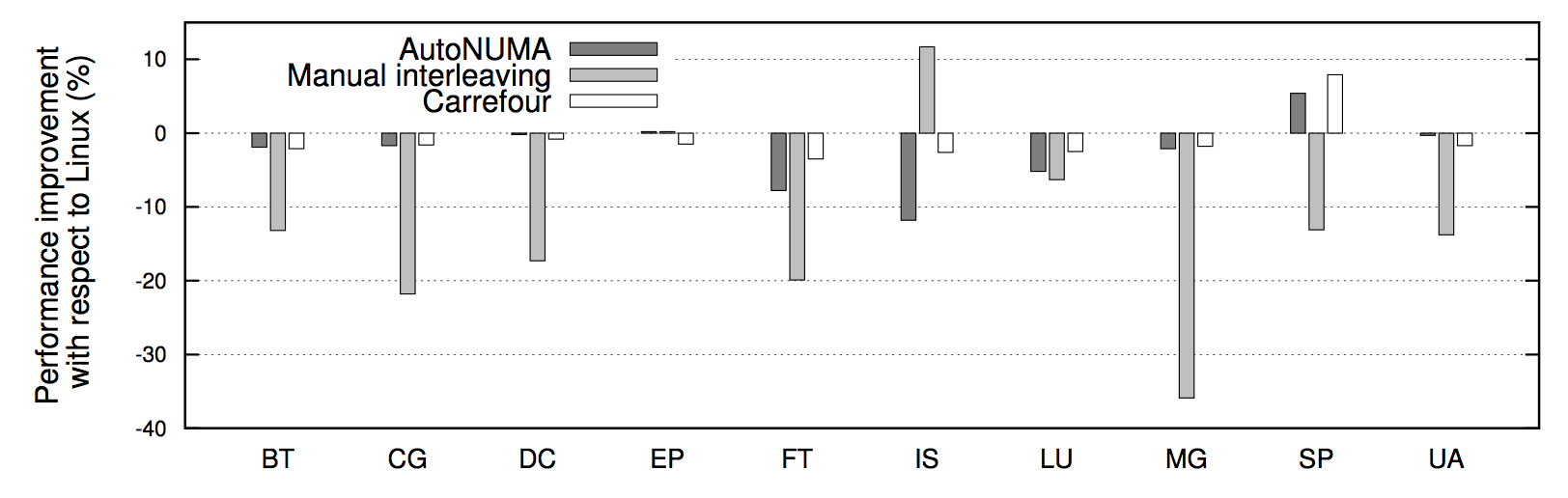
也就是說,像MySQL這種外部請求隨機性強,各個執行緒訪問記憶體在地址上平均分佈的這種應用,Interleave的記憶體分配模式相較預設模式可以帶來一定程度的效能提升。
此外 各種 論文 中也都通過實驗證實,真正造成程式在NUMA系統上效能瓶頸的並不是Remote
Acess帶來的響應時間損耗,而是記憶體的不合理分佈導致Remote Access將inter-connect這個小水管塞滿所造成的結果。而Interleave恰好,把這種不合理分佈情況下的Remote
Access請求平均分佈在了各個小水管中。所以這也是Interleave效果奇佳的一個原因。
那是不是簡簡單單的配置個Interleave就已經把NUMA的特性和效能發揮到了極致呢?
答案是否定的,目前Linux的記憶體分配機制在NUMA架構的CPU上還有一定的改進空間。例如:Dynamic Memory Loaction, Page Replication。
Dynamic Memory Relocation
我們來想一下這個情況:MySQL的執行緒分為兩種,使用者執行緒(SQL執行執行緒)和內部執行緒(內部功能,如:flush,io,master等)。對於使用者執行緒來說隨機性相當的強,但對於內部執行緒來說他們的行為以及所要訪問的記憶體區域其實是相對固定且可以預測的。如果能對於這把這部分記憶體集中到這些記憶體執行緒所在的core上的時候,就能減少大量Remote
Access,潛在的提升例如Page Flush,Purge等功能的吞吐量,甚至可以提高MySQL Crash後Recovery的速度(由於recovery是單執行緒)。
那是否能在Interleave模式下,把那些明顯應該聚集在一個CPU上的記憶體集中在一起呢?
很可惜,Dynamic Memory Relocation這種技術目前只停留在理論和實驗階段。我們來看下難點:要做到按照執行緒的行為動態的調整page在memory的分佈,就勢必需要做執行緒和記憶體的實時監控(profile)。對於Memory Access這種非常異常頻繁的底層操作來說增加profile入口的效能損耗是極大的。在 關於CPU
Cache程式應該知道的那些事的評論中我也提到過,這個道理和為什麼Linux沒有全域性監控CPU L1/L2 Cache命中率工具的原因是一樣的。當然優化不會就此停步。上文提到的Carrefour演算法和Linux社群的Auto
NUMA patch都是積極的嘗試。什麼時候記憶體profile出現硬體級別,類似於CPU中PMU 的功能時,動態記憶體規劃就會展現很大的價值,甚至會作為Linux Kernel的一個內部功能來實現。到那時我們再回過頭來審視這個方案的實際價值。
Page Replication
再來看一下這些情況:一些動態載入的庫,把他們放在任何一個執行緒所在的CPU都會導致其他CPU上執行緒的執行效率下降。而這些共享資料往往讀寫比非常高,如果能把這些資料的副本在每個Memory Zone內都放置一份,理論上會帶來較大的效能提升,同時也減少在inter-connect上出現的瓶頸。實時上,仍然是上文提到的Carrefour也做了這樣的嘗試。由於缺乏硬體級別(如MESI協議的硬體支援)和作業系統原生級別的支援,Page
Replication在資料一致性上維護的成本顯得比他帶來的提升更多。因此這種嘗試也僅僅停留在理論階段。當然,如果能得到底層的大力支援,相信這個方案還是有極大的實際價值的。
究竟是哪裡出了問題
NUMA的問題?
NUMA本身沒有錯,是CPU發展的一種必然趨勢。但是NUMA的出現使得作業系統不得不關注記憶體訪問速度不平均的問題。
Linux Kernel記憶體分配策略的問題?
分配策略的初衷是好的,為了記憶體更接近需要他的執行緒,但是沒有考慮到資料庫這種大規模記憶體使用的應用場景。同時缺乏動態調整的功能,使得這種悲劇在記憶體分配的那一刻就被買下了伏筆。
資料庫設計者不懂NUMA?
資料庫設計者也許從一開始就不會意識到NUMA的流行,或者甚至說提供一個透明穩定的記憶體訪問是作業系統最基本的職責。那麼在現狀改變非常困難的情況下(下文會提到為什麼困難)是不是作為記憶體使用者有義務更好的去理解使用NUMA?
總結
其實無論是NUMA還是Linux Kernel,亦或是程式開發他們都沒有錯,只是還做得不夠極致。如果NUMA在硬體級別可以提供更多低成本的profile介面;如果Linux Kernel可以使用更科學的動態調整策略;如果程式開發人員更懂NUMA,那麼我們完全可以更好的發揮NUMA的效能,使得無限橫向擴充套件CPU核數不再是一個夢想。