
SSD(Single Shot MultiBox Detector)演算法理解
1、演算法概述
SSD(Single Shot MultiBox Detector)是ECCV2016的一篇文章,屬於one - stage套路。在保證了精度的同時,又提高了檢測速度,相比當時的Yolo和Faster R-CNN是最好的目標檢測演算法了,可以達到實時檢測的要求。在Titan X上,SSD在VOC2007資料集上的mAP值為74.3%,檢測速度為59fps。
SSD演算法在傳統的基礎網路(比如VGG)後添加了5個特徵圖尺寸依次減小的卷積層,對5個特徵圖的輸入分別採用2個不同的3*3的卷積核進行卷積,一個輸出分類用給的confidence,每個default box生成21個類別的confidence;一個輸出迴歸用的localization,每個default box生成4個座標值,最後將5個特徵圖上的結果合併(Contact),送入loss層。
多說一句:SSD演算法是我平常用的最多的檢測演算法,但有一個問題是對小目標,尤其是密集小目標的檢測效果不好,而且有時檢測結果中會出現重疊框。但是對於一般的檢測目標,比如車牌、行人和驗證碼什麼的,檢測準確率還是很高的。而且其檢測速度達59FPS比Faster R-CNN系列高了很多,對檢測速度有要求的任務場景首選SSD演算法。
2、SSD演算法特色
(1)在基礎網路(VGG)後添加了輔助性的層進行多尺度卷積圖的預測結果融合;
(2)提出了類似Anchor的Default boxes,解決了輸入影象目標大小尺寸不同的問題,同時提高了精度,可以理解為一種特徵金字塔;
(3)相比於Faster R-CNN,SSD提出了一個徹底的end to end的訓練網路,保證了精度的同時大幅度提高了檢測速度,且對低解析度的輸入影象的效果很好;
3、具體細節
3.1 新增輔助層結構
具體結構圖如下圖所示:

將VGG19的FC6和FC7改成卷積層,又在後面添加了三個尺寸大小逐級減小的卷積層和一個平均池化層。具體用於分類迴歸的層有:Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2和Pool11。最後contact後傳給loss層。利用不同層次的特徵圖來預測offset和confidence,可以檢測不同尺寸的物體。
3.2 Default box
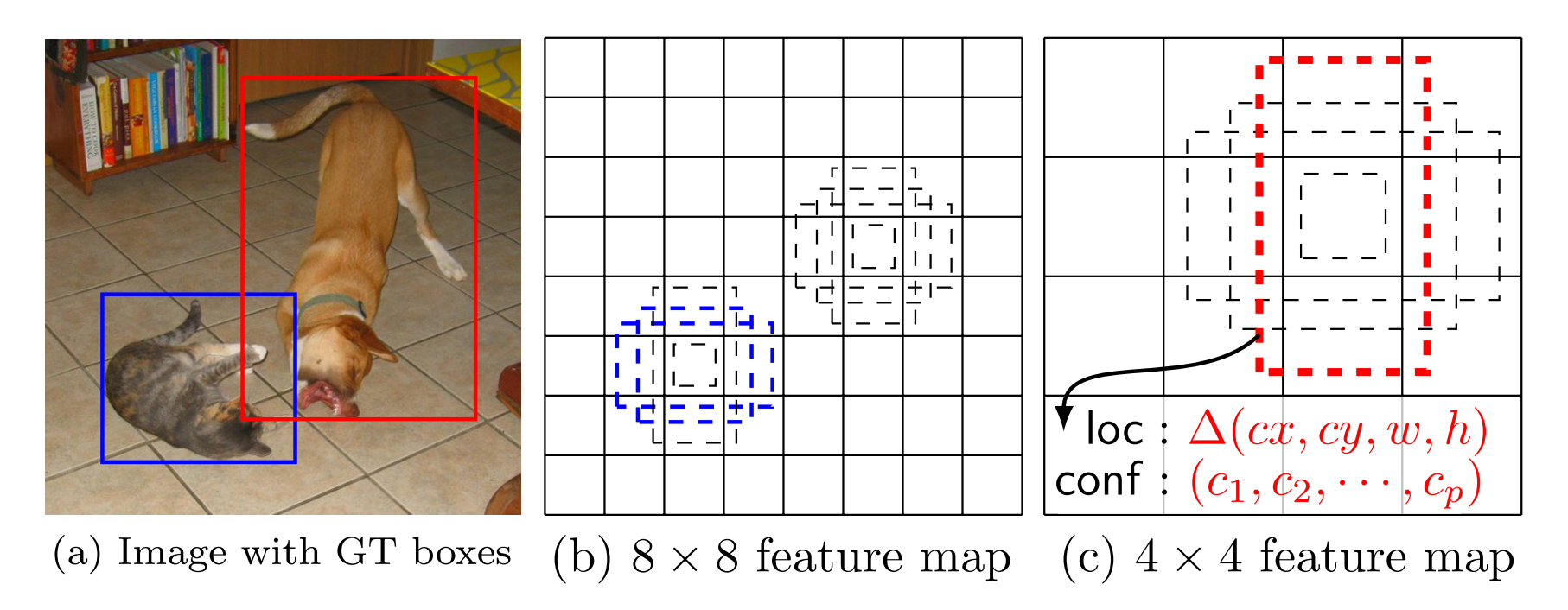
feature map被分成了許多小格子,如4*4、8*8等,每一個格子是feature map的一個cell。每一個feature map的cell上都有一系列固定大小的不同尺寸的box,叫default box,上圖中虛線的矩形框就是default box。座標的類別的預測都是基於default box(程式碼中似乎在default box的基礎上進行了處理程式設計了prior box)預測的。假設每個feature map的大小是m*n,即feature map的cell為m*n個,每一個default box都要預測C個類別的score和4個offset,假設每個feature map對應K個default box,則這張m*n大小的feature map上要產生m*n*K*(4+c)個輸出,這也意味著在這張m*n大小的特徵圖上需要用m*n*k*(c+4)個3*3的卷積核去卷積得到最後的m*n*K*(4+c)個輸出。當然這些feature map是3.1中提到的參與最終迴歸預測的5個層。每一個m*n*K*(4+c)個輸出都對應一個3*3的卷積核,對上面的5個層的輸出全部都執行上述3*3的卷積操作後,將得到的特徵圖合併(採用類似Inception模組裡的Contact,是通道合併而不是卷積圖對應的數值相加)。

3.3 Matching Strategy
這一步是說訓練需要的default box如何與GT框匹配的問題。MultiBox中用的是best jaccard overlap來配對,jaccard overlap跟IOU的概念類似,都是交集比上並集。MultiBox中採用jaccard overlap最大值的default box與GT(Ground Truth)配對。SSD中只要jaccard overlap大於0.5的default box都可以看做是正樣本,因此一個GT可以與多個default box配對。當然,小於0.5的default box就看做是負例了。
3.4 Hard Negative Mining
經過上述的Matching Strategy可能產生多個與GT匹配的正樣例的和數量更多的負例。負樣例的數目遠遠多於正樣例的數目,使正負樣例數目不平衡,導致訓練難以收斂。解決方法是:選取負樣例的default box,將他們的得分從大大小進行排序,選取的得分最高的前幾個負樣例的default box,最終使正負樣例比例為1:3。
3.5 損失函式
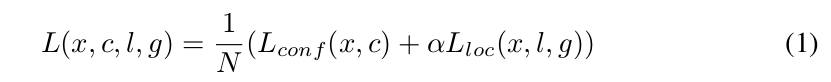
引數解釋:
(1)x: 令i表示第i個預設框,j表示第j個真實框,p表示第p個類,xi,j p={0,1}表示第i個prior box與類別p的第j個GT相匹配的jaccard overlap係數,若不匹配,則係數為0;
(2)c: 類別分類的置信值;
(3)l: 預測框引數,即box的中心座標位置和box的寬和高;
(4)g:GT框的引數,同上;
(5)N:與閾值大於0.5的GT框相匹配的default box(prior box)的個數;
(6)a(阿爾法):權重項,在prototxt中設定loc_weight對應權重項,預設為1。實際問題中檢查對於你的樣本,迴歸和分類問題哪個更難,調整loc_weight來訓練。Lloc是Faster R-CNN中的Smooth L1 loss,Lconf是Softmax Loss。
3.6 Data Augmentation
對每張訓練影象做如下的資料增廣:
(1)採用原始影象;
(2)在原圖的基礎上隨機取樣一個patch, jaccard overlap的值隨機為{0.1, 0.3, 0.5, 0.7, 0.9};
(3)在原圖的基礎上隨機取樣一個patch,取樣的patch的scale隨機在【0.1, 1】中取,aspect ratio隨機在【1/2, 2】之間取;
這樣一個樣本被上面3個batch_sampler取樣器取樣後會生成多個候選樣本,然後從中隨機選一個樣本送入網路中訓練。
測試時由於會產生大量的Bounding boxes,採用NMS(非極大值抑制),閾值設定為0.01。
具體的實驗結果請看論文,需要注意的是,論文在最後關於小目標的識別也做了對應的Data Augmentation。
參考部落格:
推薦一篇SSD使用的教學部落格: