
簡單的解釋一下查準率和召回率
查準率和召回率(查全率),這兩個指標是搜尋引擎中經典的度量方法。
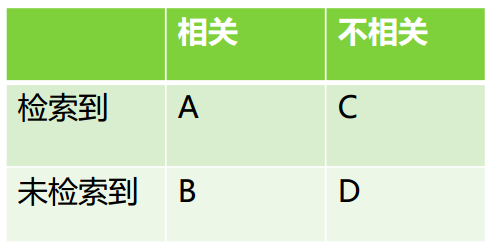
A:檢索到的,相關的 (搜到的也想要的)
B:未檢索到的,但是相關的 (沒搜到,然而實際上想要的)
C:檢索到的,但是不相關的 (搜到的但沒用的)
D:未檢索到的,也不相關的 (沒搜到也沒用的)
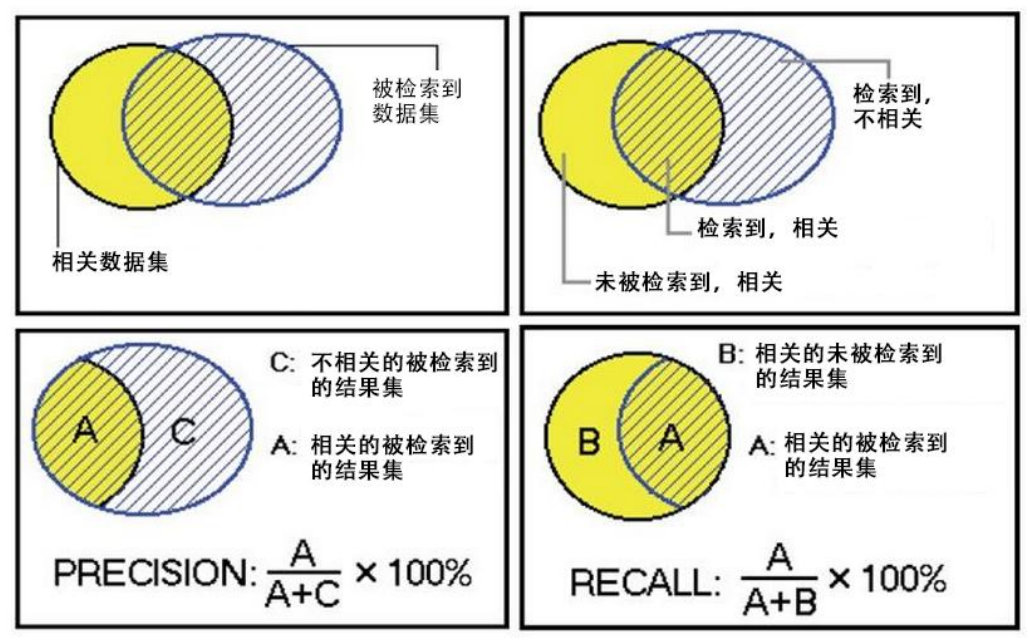
被檢索到的越多越好,這是追求“查全率”(召回率),即A/(A+B),越大越好。
被檢索到的,越相關的越多越好,不相關的越少越好,這是追求“查準率”,即A/(A+C),越大越好。
在大規模資料集合中,這兩個指標是相互制約的。當希望索引出更多的資料的時候,查準率就會下降,當希望索引更準確的時候,會索引更少的資料。
相關推薦
簡單的解釋一下查準率和召回率
查準率和召回率(查全率),這兩個指標是搜尋引擎中經典的度量方法。 A:檢索到的,相關的 (搜到的也想要的) B:未檢索到的,但是相關的 (沒搜到,然而實際上想要的) C:檢索到的,但是不相關的 (搜到的但沒用的) D:未檢索到的,也不相關的 (沒搜到
斯坦福大學公開課機器學習:machine learning system design | trading off precision and recall(F score公式的提出:學習算法中如何平衡(取舍)查準率和召回率的數值)
ron 需要 color 不可 關系 machine 同時 機器學習 pos 一般來說,召回率和查準率的關系如下:1、如果需要很高的置信度的話,查準率會很高,相應的召回率很低;2、如果需要避免假陰性的話,召回率會很高,查準率會很低。下圖右邊顯示的是召回率和查準率在一個學習算
準確率(Precision查準率)召回率(Recall查全率)和F-Meansure、mAP
某池塘有1400條鯉魚,300只蝦,300只鱉。現在以捕鯉魚為目的。撒一大網,逮著了700條鯉魚,200只蝦,100只鱉。那麼,這些指標分別如下: 正確率 = 700 / (700 + 200 + 100) = 70% 召回率 = 700 / 1400 = 50% F值 = 70% * 50% * 2 /
資料分析,資訊檢索,分類體系中常用指標簡明解釋——關於準確率、召回率、F1、AP、mAP、ROC和AUC
在資訊檢索、分類體系中,有一系列的指標,搞清楚這些指標對於評價檢索和分類效能非常重要,因此最近根據網友的部落格做了一個彙總。 準確率、召回率、F1 資訊檢索、分類、識別、翻譯等領域兩個最基本指標是召回率(Recall Rate)和準確率(Precision Rate),召回率也叫查全率,準確率也叫查準
簡單解釋一下正則化
等高線 稀疏 相交 出現 貝葉斯 最優 他還 lac 分享 解釋之前,先說明這樣做的目的:如果一個模型我們只打算對現有數據用一次就不再用了,那麽正則化沒必要了,因為我們沒打算在將來他還有用,正則化的目的是為了讓模型的生命更長久,把它扔到現實的數據海洋中活得好,活得久。
準確率accuracy、精確率precision和召回率recall
cal rac ive precision bsp trie true ron 所有 準確率:在所有樣本中,準確分類的數目所占的比例。(分對的正和分對的負占總樣本的比例) 精確率:分類為正確的樣本數,占所有被分類為正確的樣本數的比例。(分為正的中,分對的有多少) 召回率:分
分類--精確率和召回率
定義 post 做出 dev devel 模型 class evel AR 精確率 精確率指標嘗試回答以下問題: 在被識別為正類別的樣本中,確實為正類別的比例是多少? 精確率的定義如下: $$\text{Precision} = \frac{TP}{TP+FP}$$
衡量機器學習模型的三大指標:準確率、精度和召回率。
美國 ext 另一個 IE blank 進行 style 監測 最好 連接來源:http://mp.weixin.qq.com/s/rXX0Edo8jU3kjUUfJhnyGw 傾向於使用準確率,是因為熟悉它的定義,而不是因為它是評估模型的最佳工具! 精度(查準率)和
精確率和召回率
str 檢索 其中 tro 多少 自己 AS ping rac 我自己通俗的解釋: 查全率=召回率=集合裏面一共有多少個A,我們正確識別出多少個A,兩個比一下 查準率=精確率=在識別出的結果A集合裏面,有多少是真正的A,兩個比一下 p.p1 { margin: 0.
基於混淆矩陣計算多分類的準確率和召回率
定義 TP-將正類預測為正類 FN-將正類預測為負類 FP-將負類預測位正類 TN-將負類預測位負類 準確率(正確率)=所有預測正確的樣本/總的樣本 (TP+TN)/總 精確率= 將正類預測為正類 / 所有預測為正類 TP/(TP+FP) 召回率 = 將正類預
精確率,查準率,召回率
精確率(Precision),又稱為“查準率”。 召回率(Recall),又稱為“查全率”。 召回率和精確率是廣泛用於資訊檢索和統計學分類領域的兩個度量值,用來評價結果的質量。其中召回率是是檢索出的相關文件數和文件庫中所有的相關文件數的比率,衡量的是檢索系統的查全率。精確率是檢索出的相關文件數與檢索
二元分類中精確度precision和召回率recall的理解
精確度(precision) 是二元分類問題中一個常用的指標。二元分類問題中的目標類 別隻有兩個可能的取值, 而不是多個取值,其中一個類代表正,另一類代表負,精確度就 是被標記為“正”而且確實是“正”的樣本佔所有標記為“正”的樣本的比例。和精確度 一起出現的還有另一個指標召回率(r
推薦系統中準確率和召回率的理解
最近讀到推薦系統中的TopN推薦,它的預測準確率一般是通過準確率和召回率來進行評估的,那麼我們就要理解,什麼是準確率,什麼是召回率! 準確率,顧名思義,就是準確程度。通過正確數/總數得
Spark隨機森林演算法對資料分類(一)——計算準確率和召回率
1.召回率和正確率計算 對於一個K元的分類結果,我們可以得到一個K∗K的混淆矩陣,得到的舉證結果如下圖所示。 從上圖所示的結果中不同的元素表示的含義如下: mij :表示實際分類屬於類i,在預測過程中被預測到分類j 對於所有的mij可以概括為四種方式
準確率和召回率,以及評價標準F1 score
一.準確率和召回率 T為相應的情況的個數實際為真實際為假預測為真T1T3預測為假T2T4 準確率(accuracy)的計算公式是:A=(T1+T4)/(T1+T2+T3+T4) 查準率(precision)的計算公式是: P=(T1)/(T1+T3)
機器學習基礎(五十三)—— 精確率與召回率(多分類問題精確率和召回率的計算)
精確率(precision),召回率(recall)由混淆矩陣(confusion matrix)計算得來。 在資訊檢索中,精確率通常用於評價結果的質量,而召回率用來評價結果的完整性。 實際上,精確度(precision)是二元分類問題中一個常用的指
準確率(accuracy),精確率(Precision)和召回率(Recall),AP,mAP的概念
先假定一個具體場景作為例子。假如某個班級有男生80人,女生20人,共計100人.目標是找出所有女生. 某人挑選出50個人,其中20人是女生,另外還錯誤的把30個男生也當作女生挑選出來了. 作為評估者的你需要來評估(evaluation)下他的工作 首先我們可以計算準確率(accuracy),其定
準確率、查準率、召回率
混淆矩陣 True Positive(真正,TP):將正類預測為正類數 True Negative(真負,TN):將負類預測為負類數 False Positive(假正,FP):將負類預測為正類數誤報 False Negative(假負,FN):將正類預測為負類
準確率和召回率(precision&recall)
在機器學習、推薦系統、資訊檢索、自然語言處理、多媒體視覺等領域,經常會用到準確率(precision)、召回率(recall)、F-measure、F1-score 來評價演算法的準確性。 一、準確率和召回率(P&R) 以文字檢索為例,先看下圖 其中,黑框表示檢
【機器學習】正確率(Precision)和召回率(Recall)
在二分類問題中, 如果將一個正例判別為正例,那這就是一個真正例(True Positive, TP); 如果將一個反例判別為反例,那麼這就是一個真反例(True Negative,TN); 如果將