
從上下文無關文法(CFG)到語法分析樹——SLR(1)分析法
LR方法
LR parsing是一種相對於LL更通用的方法,LR parser是高效的、自底向上的用於上下文無關文法的語法分析技術。
LR(k)方法中的L、R、K分別代表:
- L: left-to-right scan從左向右掃描
- R:construct a rightmost derivation in reverse最右推導
- k:the number of input symbols of look ahead每次掃描的字元數
LR方法分為三種:
- SLR: simple LR 簡單LR方法,本文介紹的就是簡單LR(1)方法
- LR(1): canonical LR 規範LR方法
- LALR: look ahead LR
更多關於LL語法的分析方法,如預測分析法,可以檢視這裡。
本文例:
E => E + T
E => T
T => T * F
T => F
F => ( E )
F => i
構造自動機
首先為每個產生式構造自己的狀態機。
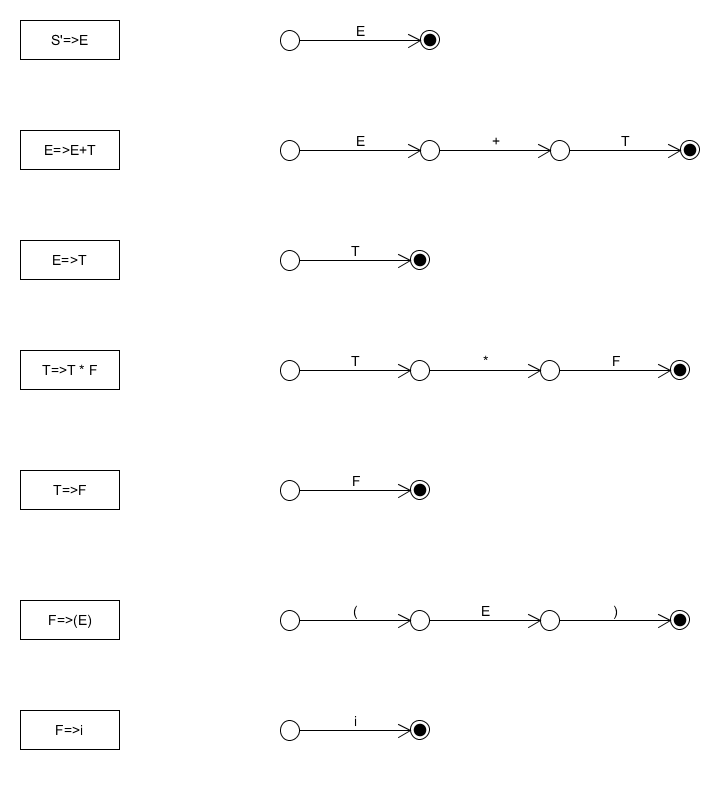
首先,我們需要理解這些狀態機的含義。每個狀態機都描述了每個產生式推導過程需要的狀態轉換。這樣的轉換是分層的。比如T=>T+F這個狀態轉換,當進行到最後F那一步時,可以直接通過i來轉換,也可以通過(E)來轉換,就是最後的那兩個表示式,每個以非終結符為發出邊的狀態轉換,如E、F等,都意味這樣的轉換需要分解為更細化的轉換,而這些“更細化的轉換”,都在後面定義了,如對於F有F=>(E)和F=>i。
因此,我們連出具體的分解狀態。

(注:空白邊都是指
我們完全不需要去細看圖中的每條線(其實可以不畫這張圖),但是我們需要理解的是狀態間的分層關係,即每個非終止符構成的發出邊一定可以分解,分解的方式就是以這個非終止符為左邊的推導式。因為每個推導式都被轉化為狀態機,這就意味著它可以分解為對應的更細化的狀態。
Q:為什麼有S’=>E這個狀態存在?
A:
為了有一個共同的起點。因為一開始E => E + T,E => T是並列的一層,需要定義一個公共的起點。
生成DFA
Step1:State naming 命名狀態
在之前我們直接把狀態命名為1、2、3、4等,在這裡這樣簡單的命名不能體現分層
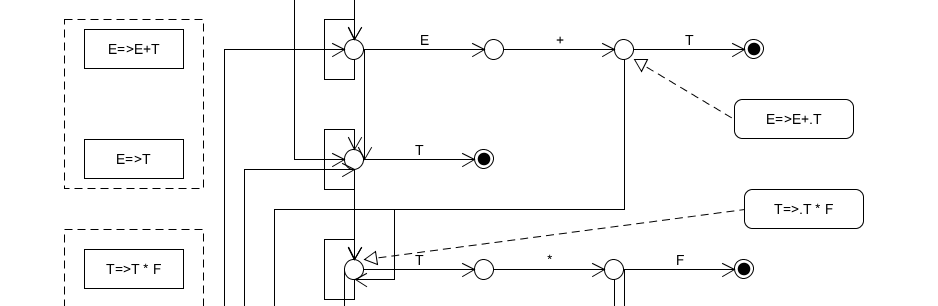
兩個命名示例如上圖所示。
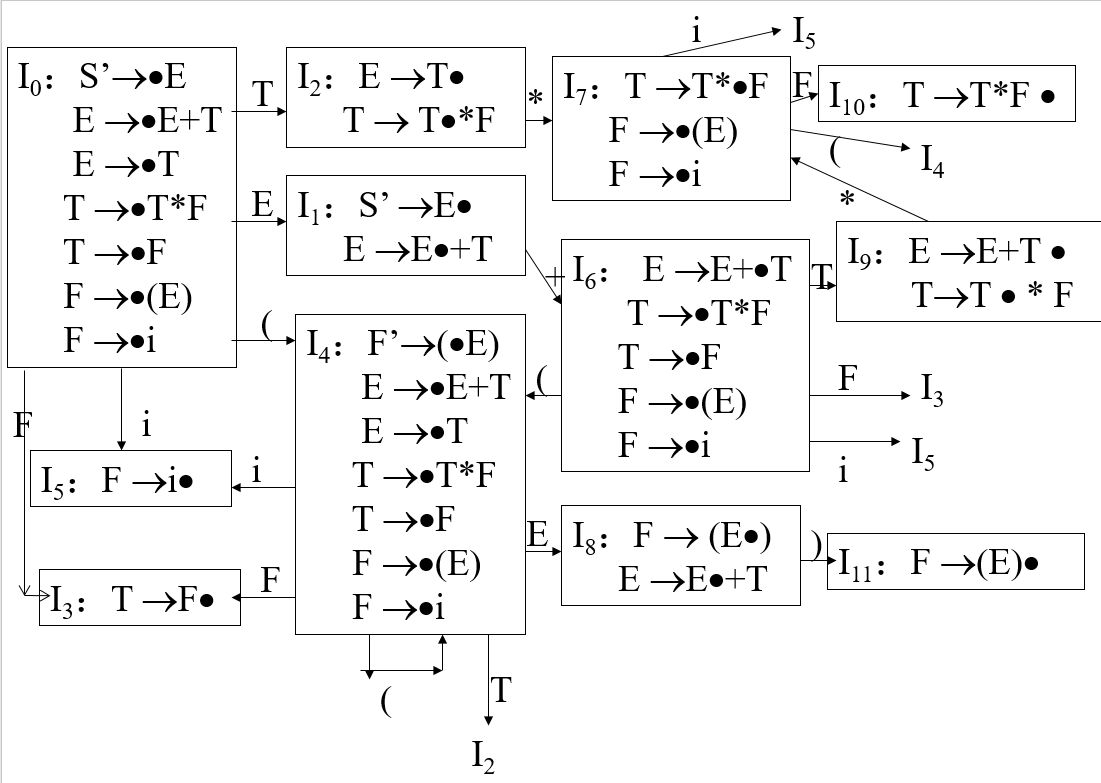
Step2:Determination 將NFA轉化為LRDFA
在之前的文章中,我們提到了如何將NFA轉化為DFA,使用的是表驅動法,當時提到了兩個概念:
ϵ 閉包->狀態內擴充套件
如何尋找開始狀態S’=>.E的“ϵ 閉包”?方法是如果有一個點在非終結符的前面,那麼該非終結符為左邊的產生式對應的第一個狀態也要加入這個新的狀態。說人話就是,對於S’=>.E,點在E的前面,則E=>.E+T和E=>.T就加入S’=>.E的ϵ 閉包,這是一個遞迴的過程,E=>.T裡點在T的前面,則T=>.T*F和T=>.F也加入S’=>.E的ϵ 閉包,然後再找F…我們為這種方法找一個新的名字叫做狀態內擴充套件,當然這只是更簡便的做法,用之前ϵ 閉包的方法完全可以找到相同的結果。子集構造法->狀態間擴充套件
與之前不同的是,這裡非終結符構成的發出邊也要考慮。而尋找子集的方法更簡單,只要將對應的點右移即可。如T=>.T*F從T發出的狀態就是T=>T.*F,同樣,這裡用之前子集構造法一樣可以解決,只是這種命名方法為轉化DFA提供了很大的便利。
下圖是完整的LRDFA圖:
構造LR分析表
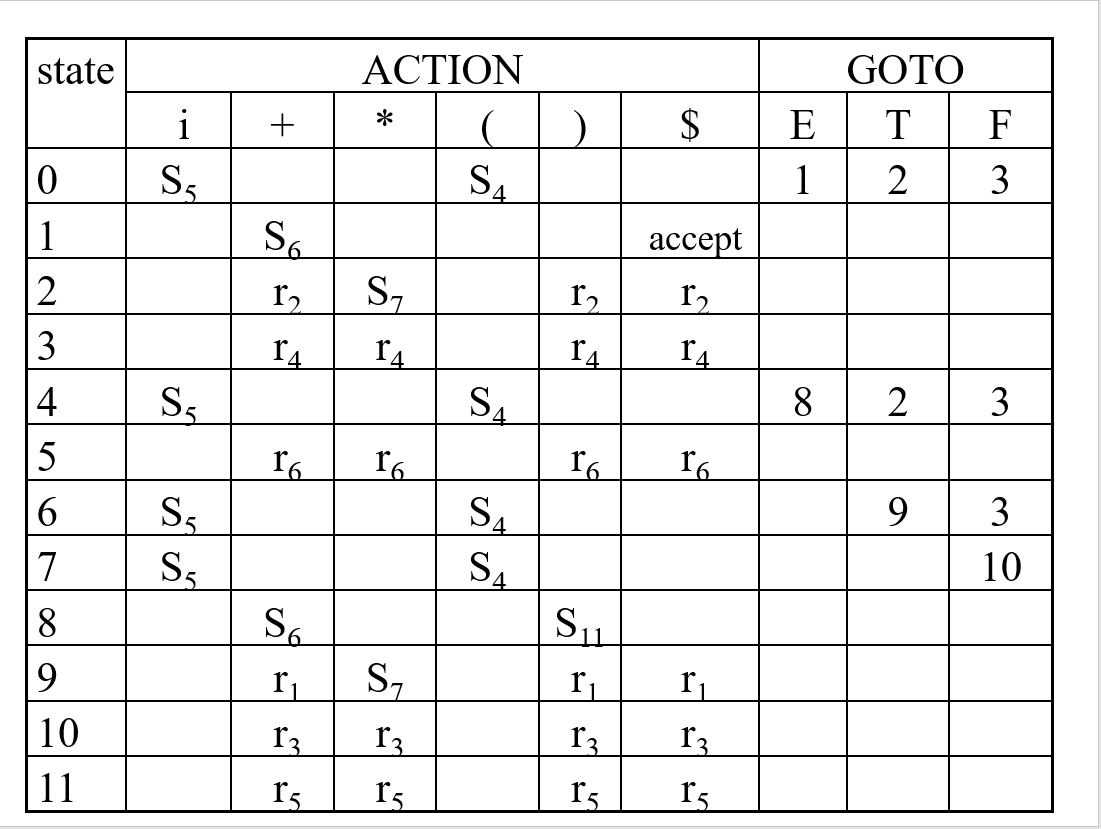
Action裡的S和GOTO裡的數字都很好填,直接按照上面生成的狀態轉換填寫即可,如I0通過發出邊T到I2,則在state0行T列寫2,I0通過發出邊i到I5,則在state0行i列寫S5(Shift5)。這裡要解釋的是r(Reduce)的填寫。
REDUCE
首先為所有產生式標號:
(0)S’=>E
(1)E => E + T
(2)E => T
(3)T => T * F
(4)T => F
(5)F => ( E )
(6)F => i
隨後,觀察每一個具體的狀態。如果有一個狀態中包含終止狀態(即點在最右邊),意味著這個子狀態分析完畢,需要進行規約。我們就需要對這個推導求Follow(Follow是什麼見上一篇文章)。
比如說,對於I2, 有E=>T.這個狀態,這裡點在T後面,也就是最後,我們需要對E求Follow,可以知道E的Follow為+和(和$,所以我們在state2的+、(、$列填上r2,這裡的2的意思是產生規約的是第二個產生式E=>T。
分析過程
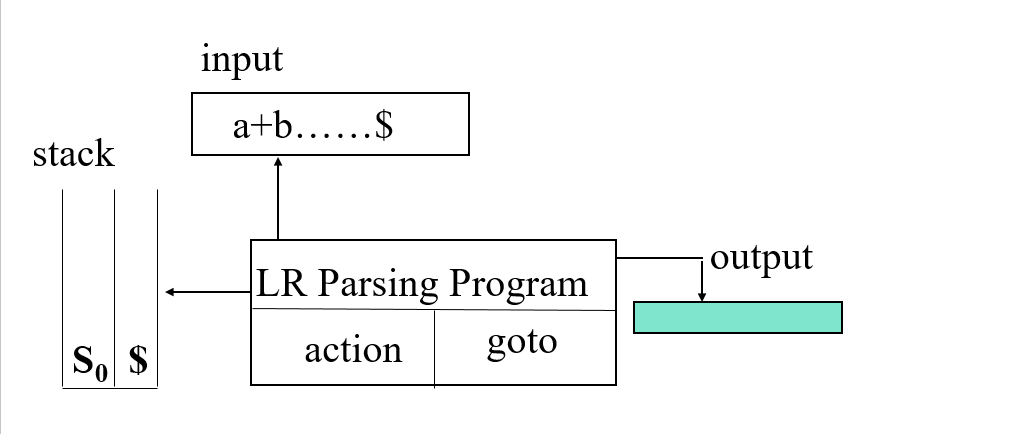
LR Parsing模型和之前的有一點區別,最大區別就是左邊的棧有兩列,最左邊一列用於存放當前的狀態,右邊一列用來存放臨時的字元和狀態。
- 若當前狀態與字元指標所指字元在LR表中對應一個ACTION的Shift(就是Si,狀態轉換),則把這個字元壓棧,因為每次壓棧時要同時壓入字元和狀態,此時壓入的對應的狀態就是ACTION裡標明的狀態,同時字元指標右移。
- 關鍵:若當前狀態與字元指標所指字元在LR表中對應一個ACTION的Reduce(即Ri),首先檢視Ri對應的產生式,比如說F=>E+F,此時則需要彈出棧中的E+F(如果步驟順利,那此時棧中已經有了E,+和F),把F壓棧,與F同時壓棧的狀態為當前的狀態(都彈出以後下面一行的狀態)與F在LR表中對應的GOTO,如果當前狀態為0,那麼與F一起壓棧的狀態就是(0,F)對應的GOTO狀態。
- 彈棧時字元要與狀態一起彈出。
- R0的意思是Accept,即分析成功結束。
PS:有空會畫出每一步的棧圖
PS:寫這個花的時間實在太長了,真的是從週一寫到週五,還有三節課不一定每節課都更啦!