
CTPN/CRNN的OCR自然場景文字識別理解(二)
CRNN
1) 端到端可訓練(把CNN和RNN聯合訓練)
2) 任意長度的輸入(影象寬度任意,單詞長度任意)
3) 訓練集無需有字元的標定
4) 帶字典和不帶字典的庫(樣本)都可以使用
5) 效能好,而且模型小(引數少)
網路結構
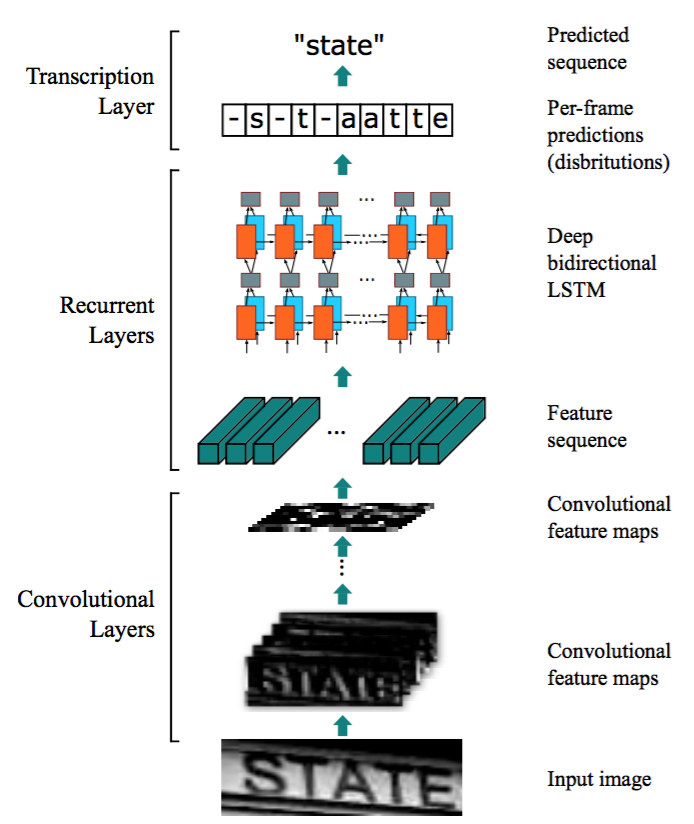
架構包括三部分:
1) 卷積層,從輸入影象中提取特徵序列;
2) 迴圈層,預測每一幀的標籤分佈;
3) 轉錄層,將每一幀的預測變為最終的標籤序列。
在CRNN的底部,卷積層自動從每個輸入影象中提取特徵序列。在卷積網路之上,構建了一個迴圈網路,用於對卷積層輸出的特徵序列的每一幀進行預測。採用CRNN頂部的轉錄層將迴圈層的每幀預測轉化為標籤序列。雖然CRNN由不同型別的網路架構(如CNN和RNN)組成,但可以通過一個損失函式進行聯合訓練。
2.1. 特徵序列提取
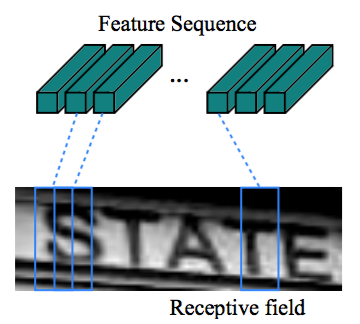
在CRNN模型中,通過採用標準CNN模型(去除全連線層)中的卷積層和最大池化層來構造卷積層的元件。這樣的元件用於從輸入影象中提取序列特徵表示。在進入網路之前,所有的影象需要縮放到相同的高度。然後從卷積層元件產生的特徵圖中提取特徵向量序列,這些特徵向量序列作為迴圈層的輸入。具體地,特徵序列的每一個特徵向量在特徵圖上按列從左到右生成。這意味著第i個特徵向量是所有特徵圖第i列的連線。在我們的設定中每列的寬度固定為單個畫素。
由於卷積層,最大池化層和元素啟用函式在區域性區域上執行,因此它們是平移不變的。因此,特徵圖的每列對應於原始影象的一個矩形區域(稱為感受野),並且這些矩形區域與特徵圖上從左到右的相應列具有相同的順序。
2.2. 序列標註
一個深度雙向迴圈神經網路是建立在卷積層的頂部,作為迴圈層。迴圈層預測特徵序列x=x1,…,xT中每一幀xt的標籤分佈yt。迴圈層的優點是三重的。首先,RNN具有很強的捕獲序列內上下文資訊的能力。對於基於影象的序列識別使用上下文提示比獨立處理每個符號更穩定且更有幫助。以場景文字識別為例,寬字元可能需要一些連續的幀來完全描述(參見圖2)。此外,一些模糊的字元在觀察其上下文時更容易區分,例如,通過對比字元高度更容易識別“il”而不是分別識別它們中的每一個。其次,RNN可以將誤差差值反向傳播到其輸入,即卷積層,從而允許我們在統一的網路中共同訓練迴圈層和卷積層。第三,RNN能夠從頭到尾對任意長度的序列進行操作。
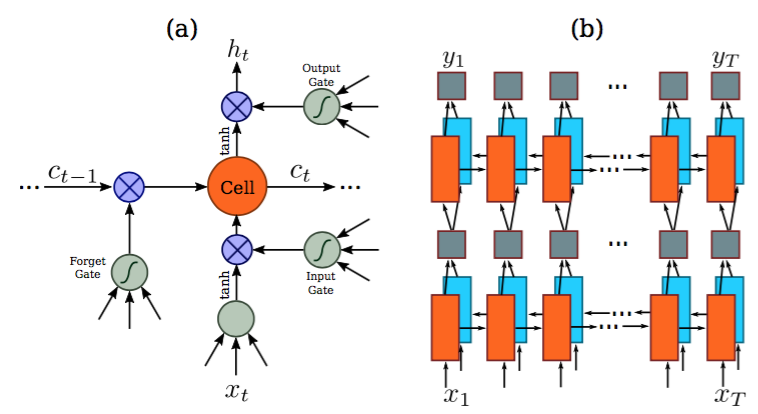
傳統的RNN單元在其輸入和輸出層之間具有自連線的隱藏層。每次接收到序列中的幀xt時,它將使用非線性函式來更新其內部狀態ht,該非線性函式同時接收當前輸入xt和過去狀態ht−1作為其輸入:ht=g(xt,ht−1)。那麼預測yt是基於ht的。以這種方式,過去的上下文{{xt′}t′