
window下連線hadoop叢集基礎超詳細版
1、Hadoop開發環境簡介
1.1 Hadoop叢集簡介
Java版本:jdk-6u31-linux-i586.bin
Linux系統:CentOS6.0
Hadoop版本:hadoop-1.0.0.tar.gz
1.2 Windows開發簡介
Java版本:jdk-6u31-windows-i586.exe
Win系統:Windows 7 旗艦版
Eclipse軟體:eclipse-jee-indigo-SR1-win32.zip | eclipse-jee-helios-SR2-win32.zip
Hadoop軟體:hadoop-1.0.0.tar.gz
Hadoop Eclipse 外掛:hadoop-eclipse-plugin-1.0.0.jar
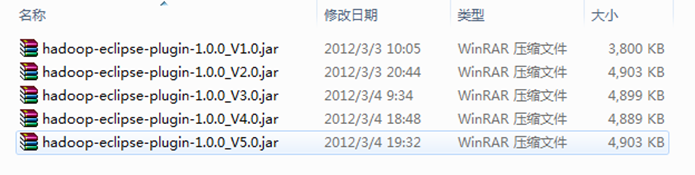
備註:下面是網上收集的收集的"hadoop-eclipse-plugin-1.0.0.jar",除"版本2.0"是根據"V1.0"按照"常見問題FAQ_1"改的之外,剩餘的"V3.0"、"V4.0"和"V5.0"和"V2.0"一樣是別人已經弄好的,而且我已經都測試過,沒有任何問題,可以放心使用。我們這裡選擇第"V5.0"使用。記得在使用時重新命名為"hadoop-eclipse-plugin-1.0.0.jar"。
2、Hadoop Eclipse簡介和使用
2.1 Eclipse外掛介紹
Hadoop是一個強大的並行框架,它允許任務在其分散式叢集上並行處理。但是編寫、除錯Hadoop程式都有很大難度。正因為如此,Hadoop的開發者開發出了Hadoop Eclipse外掛,它在Hadoop的開發環境中嵌入了Eclipse,從而實現了開發環境的圖形化,降低了程式設計難度。在安裝外掛,配置Hadoop的相關資訊之後,如果使用者建立Hadoop程式,外掛會自動匯入Hadoop程式設計介面的JAR檔案,這樣使用者就可以在Eclipse的圖形化介面中編寫、除錯、執行Hadoop程式(包括單機程式和分散式程式),也可以在其中檢視自己程式的實時狀態、錯誤資訊和執行結果,還可以檢視、管理HDFS以及檔案。總地來說,Hadoop Eclipse外掛安裝簡單,使用方便,功能強大,尤其是在Hadoop程式設計方面,是Hadoop入門和Hadoop程式設計必不可少的工具。
2.2 Hadoop工作目錄簡介
為了以後方便開發,我們按照下面把開發中用到的軟體安裝在此目錄中,JDK安裝除外,我這裡把JDK安裝在C盤的預設安裝路徑下,下面是我的工作目錄:
系統磁碟(E:)
|---HadoopWorkPlat
|--- eclipse
|--- hadoop-1.0.0
|--- workplace
|---……
按照上面目錄把Eclipse和Hadoop解壓到"E:\HadoopWorkPlat"下面,並建立"workplace"作為Eclipse的工作空間。
備註:大家可以按照自己的情況,不一定按照我的結構來設計。
2.3 修改系統管理員名字
經過兩天多次探索,為了使Eclipse能正常對Hadoop叢集的HDFS上的檔案能進行修改和刪除,所以修改你工作時所用的Win7系統管理員名字,預設一般為"Administrator",把它修改為"hadoop",此使用者名稱與Hadoop叢集普通使用者一致,大家應該記得我們Hadoop叢集中所有的機器都有一個普通使用者——hadoop,而且Hadoop執行也是用這個使用者進行的。為了不至於為許可權苦惱,我們可以修改Win7上系統管理員的姓名,這樣就避免出現該使用者在Hadoop叢集上沒有許可權等都疼問題,會導致在Eclipse中對Hadoop叢集的HDFS建立和刪除檔案受影響。
你可以做一下實驗,檢視Master.Hadoop機器上"/usr/hadoop/logs"下面的日誌。發現許可權不夠,不能進行"Write"操作,網上有幾種解決方案,但是對Hadoop1.0不起作用,詳情見"常見問題FAQ_2"。下面我們進行修改管理員名字。
首先"右擊"桌面上圖示"我的電腦",選擇"管理",彈出介面如下:
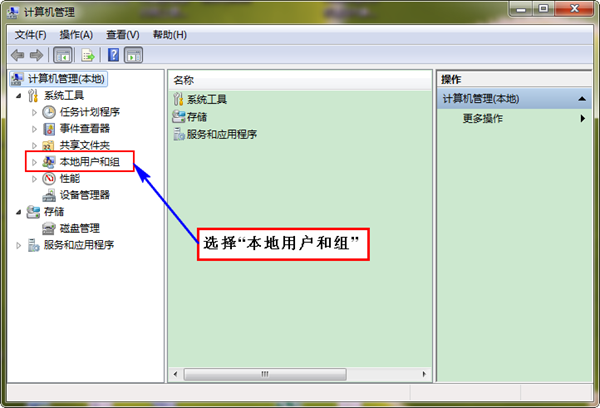
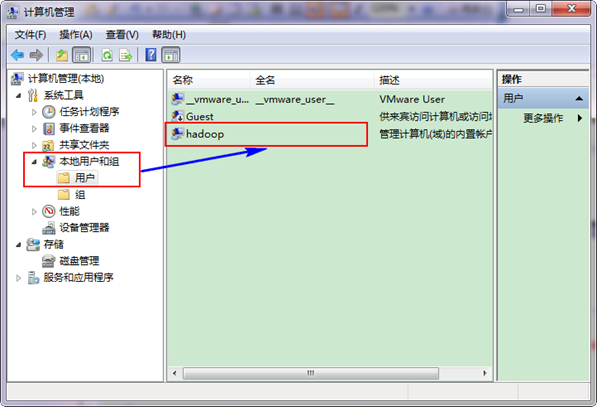
接著選擇"本地使用者和組",展開"使用者",找到系統管理員"Administrator",修改其為"hadoop",操作結果如下圖:
最後,把電腦進行"登出"或者"重啟電腦",這樣才能使管理員才能用這個名字。
2.4 Eclipse外掛開發配置
第一步:把我們的"hadoop-eclipse-plugin-1.0.0.jar"放到Eclipse的目錄的"plugins"中,然後重新Eclipse即可生效。
系統磁碟(E:)
|---HadoopWorkPlat
|--- eclipse
|--- plugins
|--- hadoop-eclipse-plugin-1.0.0.jar
上面是我的"hadoop-eclipse-plugin"外掛放置的地方。重啟Eclipse如下圖:
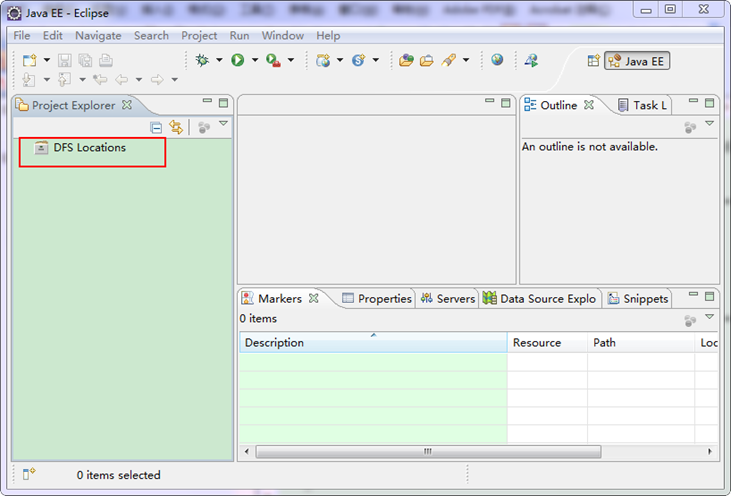
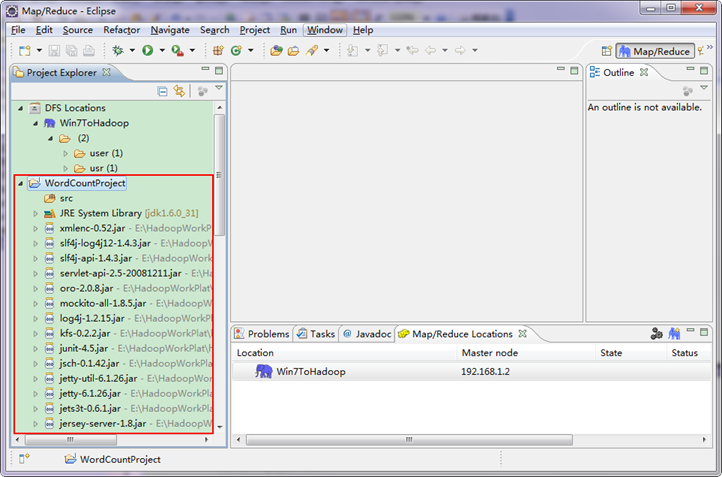
細心的你從上圖中左側"Project Explorer"下面發現"DFS Locations",說明Eclipse已經識別剛才放入的Hadoop Eclipse外掛了。
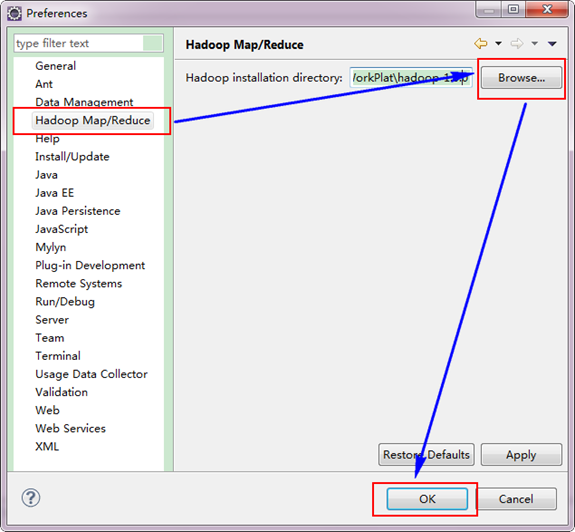
第二步:選擇"Window"選單下的"Preference",然後彈出一個窗體,在窗體的左側,有一列選項,裡面會多出"Hadoop Map/Reduce"選項,點選此選項,選擇Hadoop的安裝目錄(如我的Hadoop目錄:E:\HadoopWorkPlat\hadoop-1.0.0)。結果如下圖:
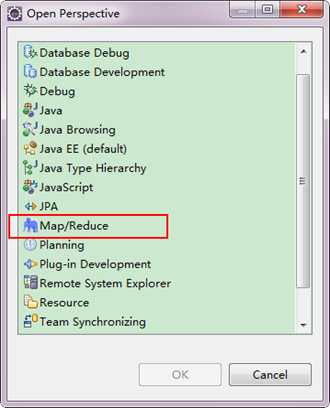
第三步:切換"Map/Reduce"工作目錄,有兩種方法:
1)選擇"Window"選單下選擇"Open Perspective",彈出一個窗體,從中選擇"Map/Reduce"選項即可進行切換。
2)在Eclipse軟體的右上角,點選圖示" "中的"
"中的" ",點選"Other"選項,也可以彈出上圖,從中選擇"Map/Reduce",然後點選"OK"即可確定。
",點選"Other"選項,也可以彈出上圖,從中選擇"Map/Reduce",然後點選"OK"即可確定。
切換到"Map/Reduce"工作目錄下的介面如下圖所示。
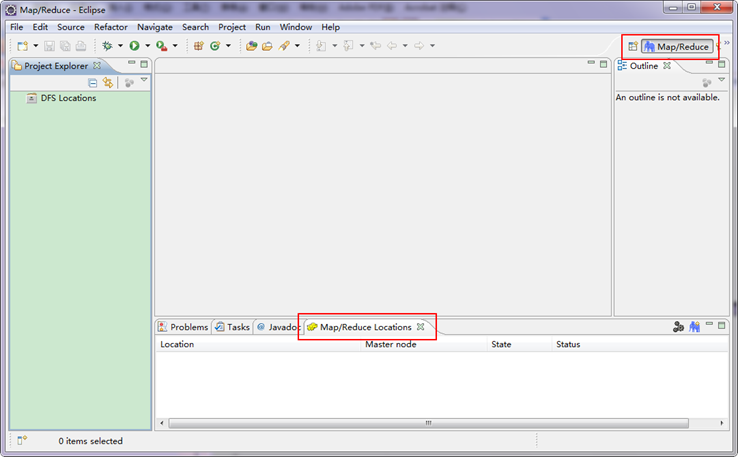
第四步:建立與Hadoop叢集的連線,在Eclipse軟體下面的"Map/Reduce Locations"進行右擊,彈出一個選項,選擇"New Hadoop Location",然後彈出一個窗體。

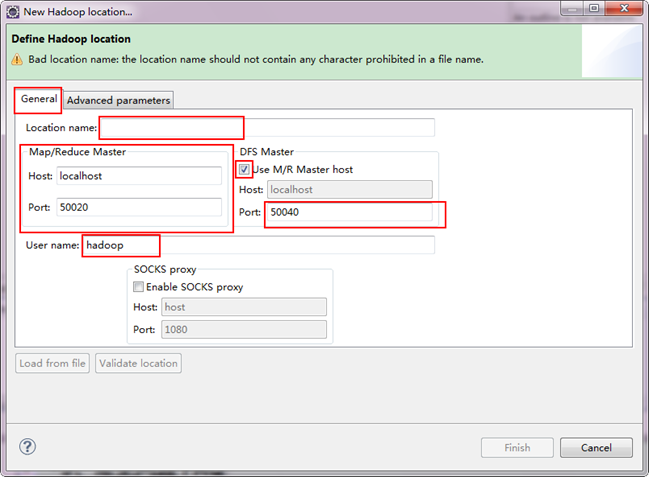
注意上圖中的紅色標註的地方,是需要我們關注的地方。
- Location Name:可以任意其,標識一個"Map/Reduce Location"
-
Map/Reduce Master
Host:192.168.1.2(Master.Hadoop的IP地址)
Port:9001
-
DFS Master
Use M/R Master host:前面的勾上。(因為我們的NameNode和JobTracker都在一個機器上。)
Port:9000
- User name:hadoop(預設為Win系統管理員名字,因為我們之前改了所以這裡就變成了hadoop。)
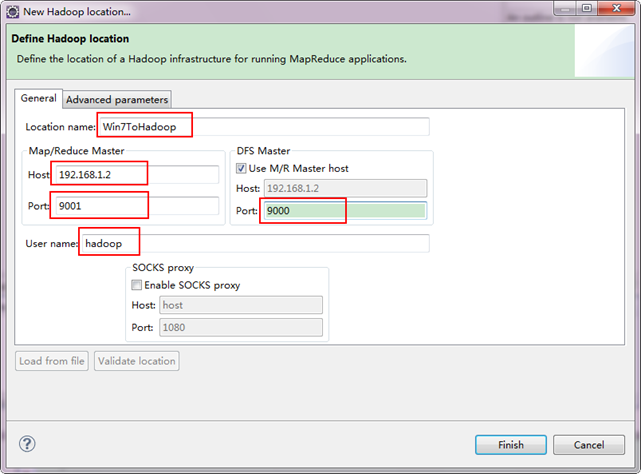
備註:這裡面的Host、Port分別為你在mapred-site.xml、core-site.xml中配置的地址及埠。不清楚的可以參考"Hadoop叢集_第5期_Hadoop安裝配置_V1.0"進行檢視。
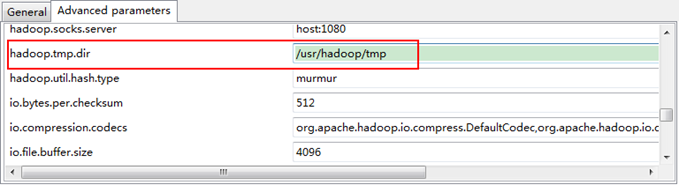
接著點選"Advanced parameters"從中找見"hadoop.tmp.dir",修改成為我們Hadoop叢集中設定的地址,我們的Hadoop叢集是"/usr/hadoop/tmp",這個引數在"core-site.xml"進行了配置。
點選"finish"之後,會發現Eclipse軟體下面的"Map/Reduce Locations"出現一條資訊,就是我們剛才建立的"Map/Reduce Location"。

第五步:檢視HDFS檔案系統,並嘗試建立資料夾和上傳檔案。點選Eclipse軟體左側的"DFS Locations"下面的"Win7ToHadoop",就會展示出HDFS上的檔案結構。
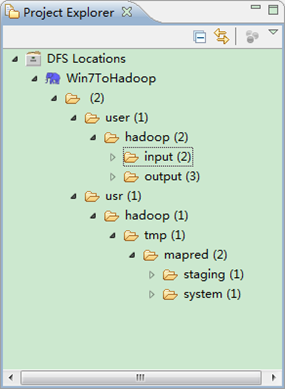
右擊"Win7ToHadoopàuseràhadoop"可以嘗試建立一個"資料夾--xiapi",然後右擊重新整理就能檢視我們剛才建立的資料夾。
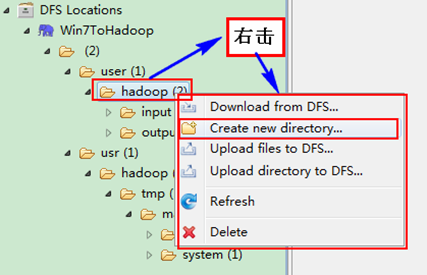
建立完之後,並重新整理,顯示結果如下:
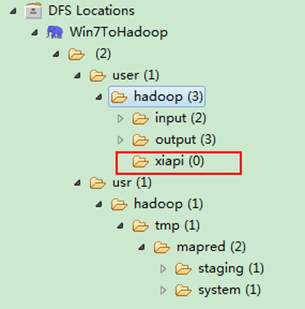
用SecureCRT遠端登入"Master.Hadoop"伺服器,用下面命令檢視是否已經建立一個"xiapi"的資料夾。
hadoop fs -ls

到此為止,我們的Hadoop Eclipse開發環境已經配置完畢,不盡興的同學可以上傳點本地檔案到HDFS分散式檔案上,可以互相對比意見檔案是否已經上傳成功。
3、Eclipse執行WordCount程式
3.1 配置Eclipse的JDK
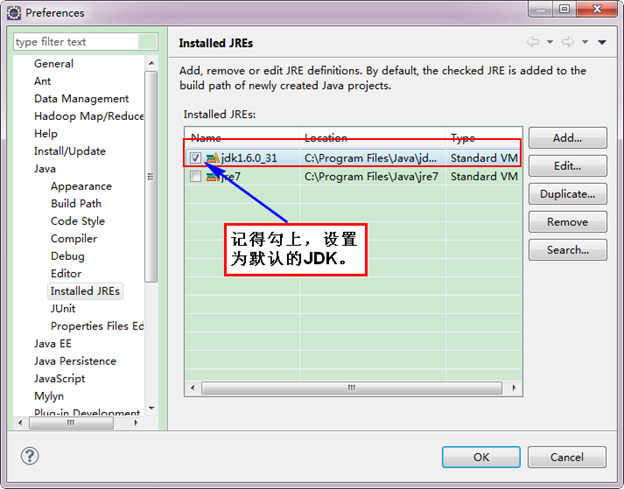
如果電腦上不僅僅安裝的JDK6.0,那麼要確定一下Eclipse的平臺的預設JDK是否6.0。從"Window"選單下選擇"Preference",彈出一個窗體,從窗體的左側找見"Java",選擇"Installed JREs",然後新增JDK6.0。下面是我的預設選擇JRE。
下面是沒有新增之前的設定如下:
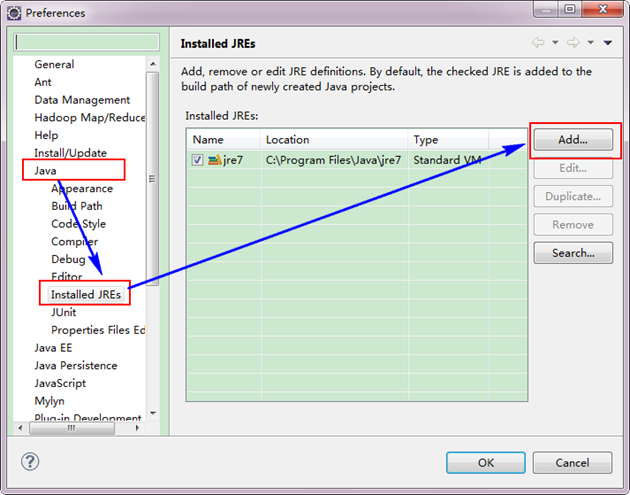
下面是新增完JDK6.0之後結果如下:
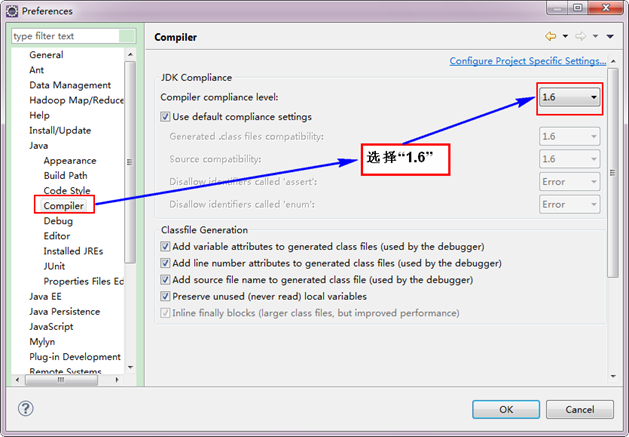
接著設定Complier。
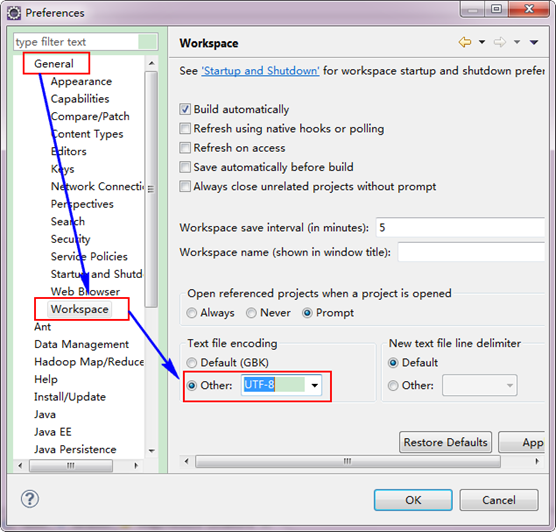
3.2 設定Eclipse的編碼為UTF-8
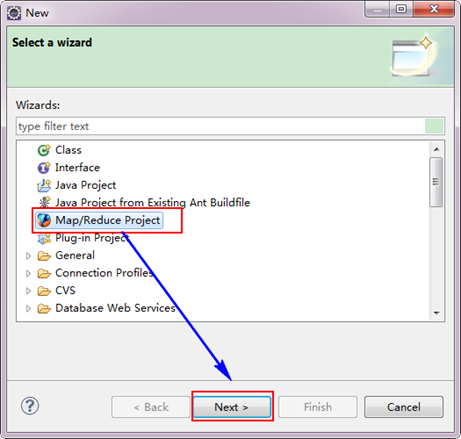
3.3 建立MapReduce專案
從"File"選單,選擇"Other",找到"Map/Reduce Project",然後選擇它。
接著,填寫MapReduce工程的名字為"WordCountProject",點選"finish"完成。
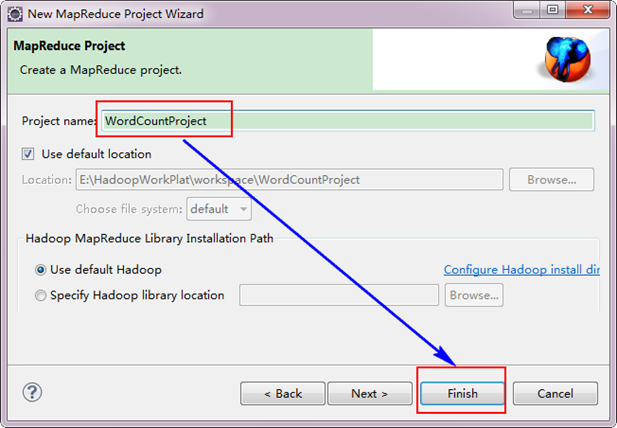
目前為止我們已經成功建立了MapReduce專案,我們發現在Eclipse軟體的左側多了我們的剛才建立的專案。
3.4 建立WordCount類
選擇"WordCountProject"工程,右擊彈出選單,然後選擇"New",接著選擇"Class",然後填寫如下資訊:
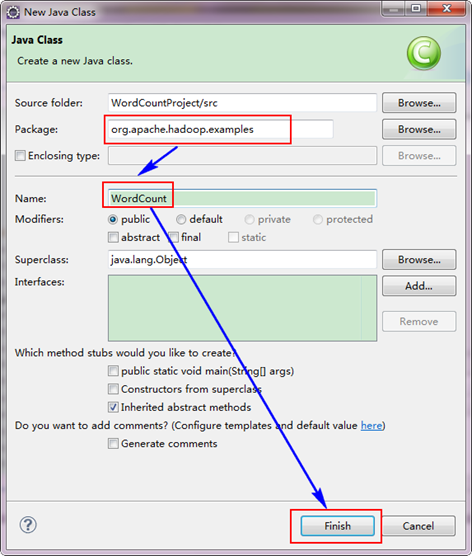
因為我們直接用Hadoop1.0.0自帶的WordCount程式,所以報名需要和程式碼中的一致為"org.apache.hadoop.examples",類名也必須一致為"WordCount"。這個程式碼放在如下的結構中。
hadoop-1.0.0
|---src
|---examples
|---org
|---apache
|---hadoop
|---examples
從上面目錄中找見"WordCount.java"檔案,用記事本開啟,然後把程式碼複製到剛才建立的java檔案中。當然原始碼有些變動,變動的紅色已經標記出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
相關推薦window下連線hadoop叢集基礎超詳細版1、Hadoop開發環境簡介 1.1 Hadoop叢集簡介 Java版本:jdk-6u31-linux-i586.bin Linux系統:CentOS6.0 Hadoop版本:hadoop-1.0.0.tar.gz Windows 下 Redis叢集的搭建 ——(超詳細版)1、下載並安裝Redis 本人安裝到C盤了,在C:\Redis 下建立Logs資料夾 , 然後在C:\Redis 建立 3個不同的Redis例項 ①、 redis.6380.co hadoop叢集搭建(超詳細版)1.準備好需要安裝的軟體虛擬機器VMware12.pro作業系統CentOS 6.5遠端控制虛擬機器的終端SecureCRT8.12.在虛擬機器中安裝CentOS作業系統安裝好虛擬機器,圖形介面如下圖建立新的虛擬機器,選擇自定義(高階),點選下一步虛擬機器硬體相容性預設,瀏覽 Linux下Hadoop2.7.1叢集環境的搭建(超詳細版)1 <?xml version="1.0"?> 2 <!-- 3 Licensed under the Apache License, Version 2.0 (the "License"); 4 you may not use this file except in c hadoop學習之HDFS(2.5):windows下eclipse遠端連線linux下的hadoop叢集並測試wordcount例子windows下eclipse遠端連線linux下的hadoop叢集不像在linux下直接配置eclipse一樣方便,會出現各種各樣的問題,處處是坑,連線hadoop和執行例子時都會出現問題,而網上的 Linux下Hadoop2.7.1集群環境的搭建(超詳細版)目錄 hdfs cp命令 manage war 替代 share logs hadoop 本文旨在提供最基本的,可以用於在生產環境進行Hadoop、HDFS分布式環境的搭建,對自己是個總結和整理,也能方便新人學習使用。 一、基礎環境 在Linux上安裝Hadoop之前 hadoop window下安裝 hadoop-2.6.0all art ice dfs- win 技術 per atan 分享圖片 一、官網下載hadoop http://hadoop.apache.orghttps://archive.apache.org/dist/hadoop/common/hadoop-2.6.0 管理員 Linux-CentOS7下安裝Elasticsearch6.3.0超詳細步驟檢測是否安裝了Elasticsearch ps aux|grep elasticsearch 1、安裝JDK Elastic 需要 Java 8 環境 安裝JDK具體操作,請點選連結 2、下載Elasticsearch wget https://artifacts.elast Hadoop叢集配置安裝,詳細步驟及講解**涉及linux命令一定要注意大小寫和空格,linux系統對此敏感** **hadoop叢集的安裝一定要靜下心一步一步來** 1、關閉防火牆(防火牆最好關閉,不然以後linux操作會有很多麻煩) 1)輸入命令: vi etc/selinux/config 其中改為 SELINU windows下idea編寫WordCount程式,並打jar包上傳到hadoop叢集執行(傻瓜版)通常會在IDE中編制程式,然後打成jar包,然後提交到叢集,最常用的是建立一個Maven專案,利用Maven來管理jar包的依賴。 一、生成WordCount的jar包 1. 開啟IDEA,File→New→Project→Maven→Next→填寫Groupld和Artifactld→Ne python3.基礎爬取網易雲音樂【超詳細版】簡單學習了python爬蟲之後,我們就可以嘿咻嘿咻了...因為平時就是用網易雲聽的歌,也喜歡看歌裡的評論,所以就爬網易雲音樂評論吧! 正式進入主題 首先還是去找目標網頁並開始分析網頁結構,如下 上面的三個箭頭都是所要找的資料,分別是評論使用者,評論和點贊數,都可以用正則表示式找出來,接下來繼續找怎樣 vmware centOS7.0環境下配置hadoop叢集+spark叢集從開始玩linux,配置hadoop和spark叢集的過程用了二十多個小時,後面也是進行得越來越順利。 在安裝和配置過程中學習和用到的一些網站和部落格,在此分享一下。 一、vmware centOS7.0 hadoop jdk hadoop scala spark 安裝包百度網盤分享 window下eclipse執行叢集mr時錯誤總結1.叢集提交修改項 a.確保JobAPP提交至叢集 解決方案:修改mapred-site.xml windows下連線hadoop執行eclipse報錯Permission denied:這是許可權問題,試了一下同時也不能在hdfs建立資料夾。 解決: 修改如下hadoop的配置檔案:etc/hadoop/hdfs-site.xml,如沒有的話可以新增上。 <property> <name>dfs.permissi docker環境下搭建hadoop叢集(ubuntu16.04 LTS系統)我的思路是這樣: 安裝ubuntu系統---->下載docker---->在docker里拉取hadoop映象---->在此映象裡建立三個容器(Master、Slave1、Slave2)---->完成完全分散式 1. 安裝ubuntu系統(無論你 HBase安裝 - 聯邦機制下的hadoop叢集老師的聯邦機制的hadoop叢集的分佈 : master1 : namenode zkfc master1ha : namenode zkfc zookeeper journalnode master2: namenode zkfc zookeeper journalnode mas 從VMware虛擬機器安裝到hadoop叢集環境配置詳細說明虛擬機器安裝 我安裝的虛擬機器版本是VMware Workstation 8.04,自己電腦上安裝的有的話直接在虛擬機器安裝Linux作業系統,沒有的話這裡有我的一個百度雲網盤虛擬機器安裝共享檔案 虛擬機器的具體安裝不再詳細說明了。 Linux作業系統安裝除錯 hadoop 叢集搭建(詳細)hadoop 叢集搭建 一 、 前提準備 (多圖)CentOS下安裝NVIDIA driver的超詳細教程NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and runnin 在window下搭建redis 叢集下載window版本的redis 下載地址:https://github.com/MSOpenTech/redis/releases 解壓並複製生成6份redis檔案,分別用即將分配的埠進行檔案命名 3. 配置每份Redis中的配置檔案 修改redis.window |