
系統間通訊方式之(Kafka的實際使用場景和使用方案)(二十三)
5、場景應用——電商平臺:瀏覽記錄收集功能
事件/日誌收集系統是大中型軟體不得不面對的話題。目前第三方業務系統對 事件/日誌收集系統 的整合思路主要有兩大類:侵入式收集方案和非侵入式收集方案。侵入式收集方案,是指任何需要使用事件/日誌收集系統的第三方系統,都需要做有針對的編碼工作,這個編碼工作或者是新增程式碼用於呼叫 事件/日誌收集系統 提供的客戶端API,又或者是修改已有的程式碼,以便適應事件/日誌收集系統的呼叫特性。
侵入式方案又分為半侵入式和全侵入式。由於第三方系統的程式碼結構本身存在問題,所以一旦需要整合 事件/日誌收集系統(或者任何其他第三方系統),就會造成業務處理過程改變。相反,由於需求變動導致的業務程式碼變動,也會牽扯到任意的第三方系統整合程式碼的改變。這樣的整合方式就是全侵入式的。出現這種的情況,是第三方系統所選擇的技術方案和業務系統本身的工程結構問題共同造成的。
很顯然,全侵入式的方案是一種錯誤的設計實踐,在日常的設計工作中是要儘量避免。半侵入式方案比全侵入方案要好很多:雖然第三方系統會針對 事件/日誌收集系統 做一定的程式碼改造,但是由於第三方系統的結構清晰,所以這部分程式碼和第三方系統原有的業務程式碼是完全分離的,只需要改造一次就可一直使用。也不會對第三方系統既有的業務處理過程產生任何影響,反之第三方系統由於需求變化產生的業務程式碼變化也不會影響 事件/日誌收集系統 的客戶端整合程式碼變化。
事件/日誌收集系統 另外一種設計方案是非侵入式的。即業務系統在整合 事件/日誌收集系統時,不需要為這件事情專門引入新的程式碼或者修改已有程式碼。業務系統的開發人員甚至完全不知道(也不必知道)自己的系統集成了 事件/日誌收集系統,僅通過配置一些引數檔案的方式就可完成整合工作。
我們將通過包括本文章在內的2-3篇文章的篇幅,利用已經學習過的技術知識向大家介紹事件/日誌收集系統的半侵入方案和非侵入式方案。當然中間還會穿插一些新技術的介紹,比如Apache Flume。
5-1、場景說明
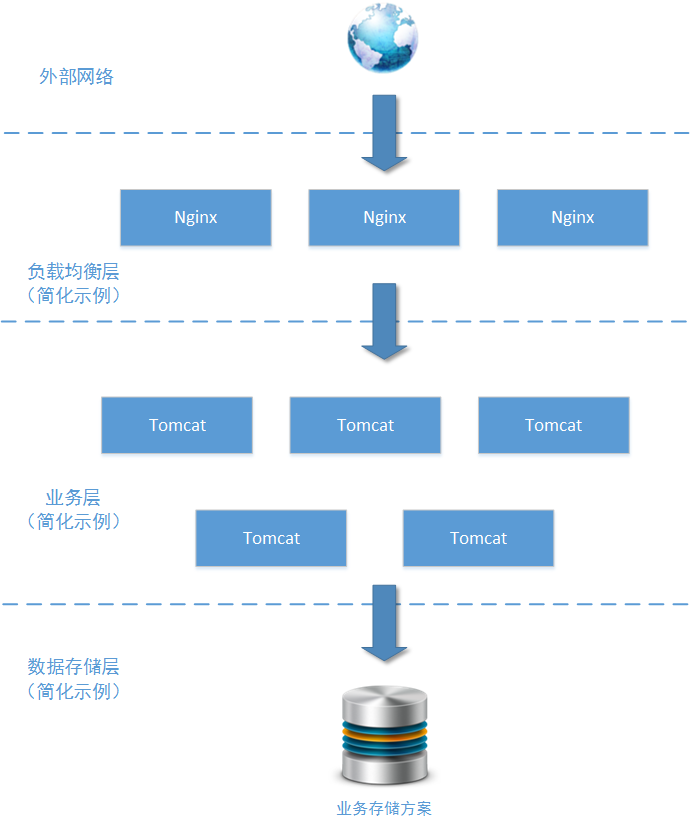
這是一個日均200萬PV的中型電商網站的一個系統模組:商品詳情模組。這個模組用於(且只用於)向用戶展示商品詳情、展示商品價格走勢。上圖所示中,該模組只列舉了使用的主要技術元件,畢竟這個例項場景不是為了討論這些技術元件本身。由於網站業務的發展需要,需要在這個模組加入使用者操作的統計分析功能,對使用者“點選檢視訂單詳情”、“點選檢視商品價格走勢”等操作動作進行事件/日誌收集。
為什麼要對這些操作進行統計呢?因為這些資料能夠說明某一個使用者在一個特定的時間段對哪些商品感興趣,預計對哪些(或哪一類)商品會產生購買訂單。藉助後端的資料分析手段,還能知曉某一類使用者對哪一類商品感興趣的概率配比。所以這些商品詳情檢視的操作日誌特別有商業價值。
日均200萬PV是一個什麼概念呢?這麼說吧,翼支付(bestpay.com.cn)的日均PV在34萬左右,汽車之家(autohome.com.cn)的日均PV在100萬左右,折800(zhe800.com)的日均PV在600萬,攜程線上(ctrip.com)日均PV1200萬,京東(jd.com)日均PV3.7億,淘寶(taobao.com)日均6.4億(以上資料均來自alexa.cn)……
PV是Page View的簡稱,即一次頁面的完整開啟算作一次PV。PV的統計中,這次頁面訪問“是由那個訪問者發起的”並不會對統計結果構成直接影響,也就是說即使是同一個訪問者連續兩次開啟同一個頁面,也會算作PV=2。這裡要注意的另外一個問題是,由於在瀏覽器頁面上會有很多訪問連線(例如:多個圖片連線、多個AJAX請求等),所以一次PV可能會包含多次對服務端的請求。
作為架構師,您的工作職責就是為這個日誌記錄系統設計一個易於業務擴充套件和技術擴充套件的軟體架構。所謂易於業務擴充套件是指:也許在未來的某個日子不只是“商品詳情模組”會整合本系統,使用者中心模組也會整合本系統又或者訂單子系統也會整合本系統,您設計的日誌收集子系統應該可以在未來被這些子系統輕鬆整合,而不需要修改 日誌收集系統 的任何程式碼(目標子系統也只需要修改極少的程式碼,甚至不修改程式碼)。
所謂技術擴充套件主要是說“日誌收集系統”支撐的資料吞吐量可以進行可靠的橫向擴充套件,而不需要停止服務或者要求業務系統進行改動,畢竟要相應考慮以上業務擴充套件中所描述的多種業務系統可可以進行整合的問題。另外,由於未來很多第三方系統都需要進行整合,作為架構師的您不可能知曉這些第三方系統會使用的是什麼程式語言,更不可能限制第三方系統必須使用哪些程式語言。所以在進行 事件/日誌收集系統 的設計時,需要考慮一種相容各種程式語言的設計思路。
5-2、解決方案一:半侵入式方案
我們先來看看此問題的第一種解決方案。如果您確定將要整合 事件/日誌收集系統 的所有第三方業務系統都有良好的程式碼結構(當然實際工作這種情況不太可能),那麼為這些第三方系統提供相應程式語言的客戶端API,就是一個可選擇的方案:
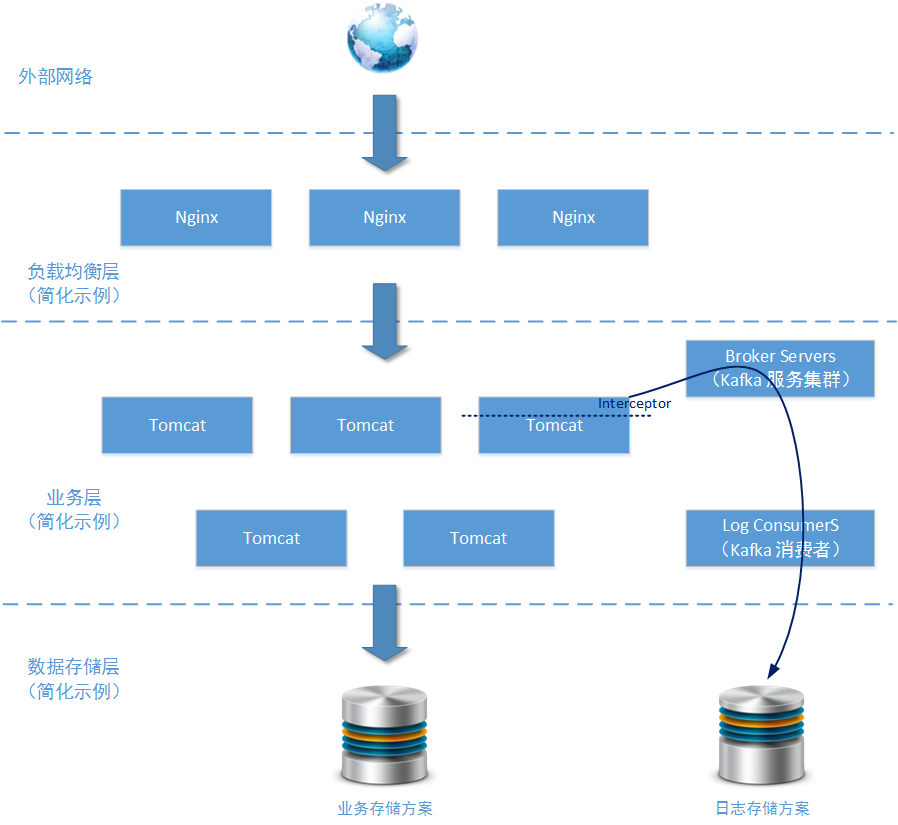
所有操作日誌在業務系統上使用過濾器/攔截器的方式對需要進行收集的訪問請求進行攔截。分離出訪問地址、訪問使用者、訪問時間等重要資訊後,將其作為Kafka訊息傳送給Kafka Brokers 叢集。這些資訊將最終到達由若干Kafka Consumers節點組成的處理服務,並使用適當的儲存方案直接儲存到連續檔案中(儲存到HBase、Cassandra這樣的資料庫中也行,具體看這些日誌資料將會被用於怎樣的分析場景)。
5-2-1、設計重點說明
上圖中,主要的展示目的是事件/日誌收集系統在業務系統端是怎樣被整合的。所以關於事件/日誌收集系統的結構就畫得比較簡單。只給出了兩個區塊“Broker Servers”和“Log Consumers”,下面我們重點分析一下本方案中的 事件/日誌收集系統 的核心結構:
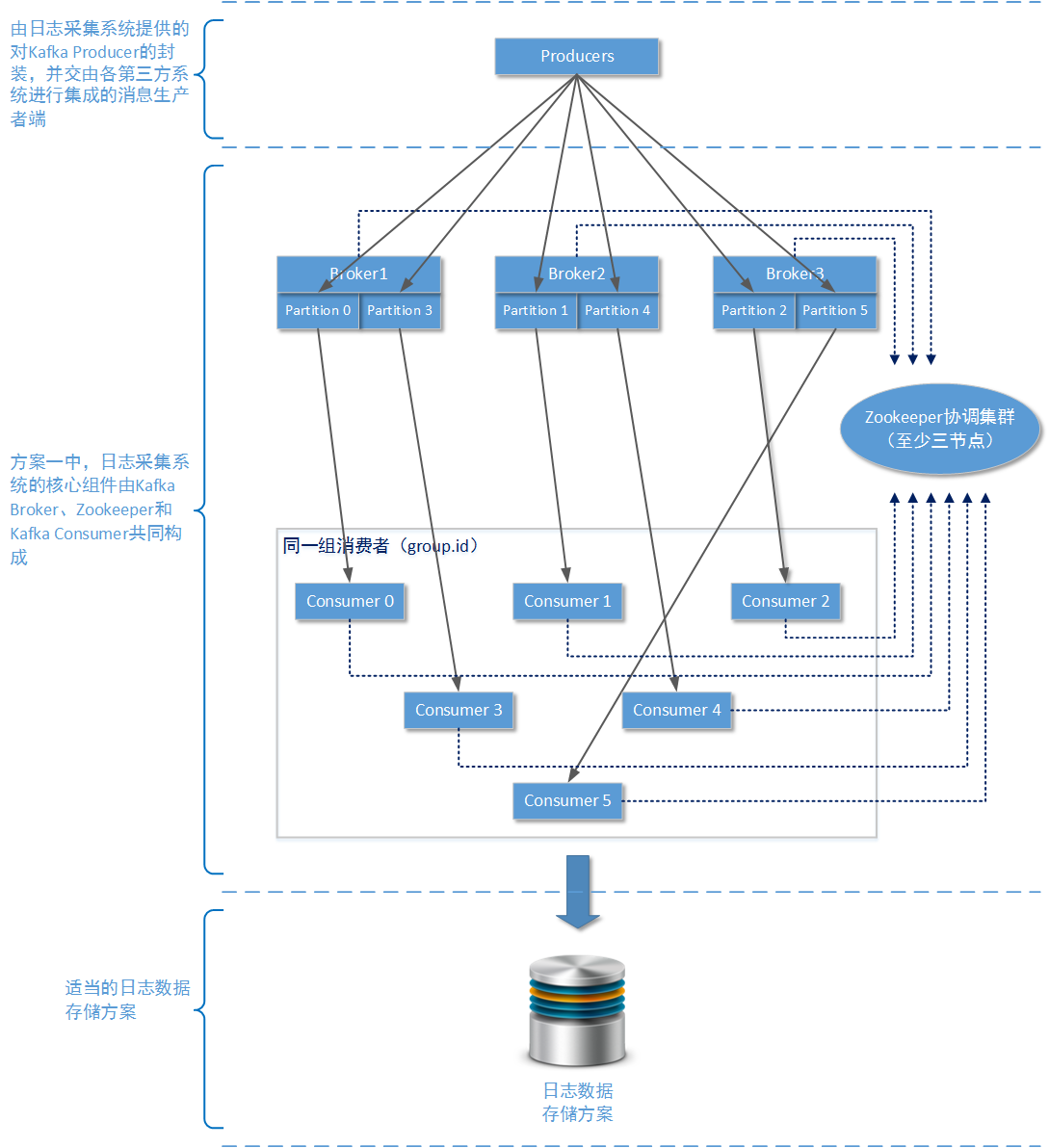
在方案一種,我們主要使用單純以Apache Kafka為核心的訊息佇列解決方案。
- 需要多個zookeeper節點?
使用Apache Kafka時,如果您只是用一個zookeeper服務節點,整個叢集也能正常工作。但是由於單個節點的zookeeper服務基本上沒有容錯能力,一旦單個zookeeper節點由於各種原因宕機,整個Apache Kafka叢集就會崩潰。所以建議在生產環境下,至少為zookeeper服務準備三個服務節點,這樣當某個zookeeper服務節點出現故障整個Apache Kafka服務還可以正常執行(三個節點得zookeeper服務最多允許一個節點發生故障)。
- 多少個Broker?
在生產環境下為了保證整個Kafka叢集的穩定,請至少使用3個Brokers物理節點。考慮到後期多個業務系統可能會使用事件/日誌收集系統,那麼可以在首次設計時將Brokers設定為5個Brokers物理節點。在之前的文章中我們已經詳細介紹過Apache Kafka的工作原理,Brokers越多、Topic的分割槽(partition)越多,整個Apache Kafka叢集的穩定性和吞吐量就越好。
再說明一下其中的複製因子數量設定,複製因子對訊息可靠性有直接影響,並且在設定為強一致性工作模式下也會對訊息吞吐量產生影響。由於我們使用Kafka主要是為了接收/傳送日誌資料,在執行過程中丟失一兩條日誌是可以容忍的錯誤。所以建議設定複製因子數量為 “Brokers數量 / 2 + 1”,並且在生產者端使用“弱一致性”傳送模式,即acks == 1。
- 多少個消費者,分割槽怎麼分配?
為了區分日誌資料來自於哪一個業務系統,可以專門為不同的業務系統設定獨立的Topic。分割槽數量最好為Brokers數量的整數倍,這樣才能確保在每一個物理節點在硬體配置相同的情況下,能夠很好的均分吞吐量壓力。具體來說,由於我們在生產環境採用了5個Brokers物理節點,那麼每一個Topic的分割槽數量最好為5的整數倍,例如您可以設定分割槽數量為10。
既然設定分割槽數量為10,那麼同一個消費者組的消費者數量最科學的值也是10。因為Kafka叢集中存在同一個分割槽的資料在同一時間最多被一個消費者所消費的限制,所以如果存在第11個消費者,它也只能處於備用等待狀態。待到某個消費者出現問題時,再由第11個消費者進行頂替。實際上在 事件/日誌採集系統 中這樣的Apache Kafka叢集規模,已經完全可以應付日均200萬PV的網站系統對日誌採集工作的吞吐量要求了。
- 什麼是適當的儲存方案
日誌資料的分析手段一般有兩種:實時分析和離線分析。所謂實時分析是說分析服務在接收到日誌資料後,立即對產生的後果進行計算並將分析結果記錄在某個儲存方案上。Apache Storm、Apache Spark都是常用的實時分析系統,不過在本專題中並不會對Apache Storm或者Apache Spark進行詳細介紹,畢竟這屬於另一個知識領域了(資料分析以後會有專門的專題進行講解。當然,讀者也可以認為作者壓根不知道)。實時分析在生產環境中有很多應用,例如根據使用者的上線/下線日誌對使用者的線上數量進行實時統計;根據商品的點選情況,對商品的檢視數量進行實時統計;根據使用者的頁面跳轉情況實時形成使用者瀏覽軌跡地圖。
日誌資料的另一種分析手段是離線分析。即分析服務在接收到原始日誌資料後並不做任何處理,只是將原始資料按照預定的格式(又或者就是資料本來的格式)儲存到某個位置。當某個時間週期到來或者具體的事件被觸發時,再由其他軟體對這些資料進行分析。Apache Hadoop/Cloudera Hadoop就是常用的離線分析工具。您可以通過某種手段,將原始的日誌資訊儲存在HDFS檔案系統上,以便Hadoop進行離線分析。離線分析在實際生產環境中也有很多應用,例如按照使用者的商品瀏覽情況分析使用者的購買趨勢、利用商品關鍵詞進一步分析適合銷售的使用者群體、利用商品庫存和價格走勢預測最佳補貨時機。
無論是實時分析還是離線分析Kafka的下層系統(元件)都需要做儲存操作。例如您可以直接使用Kafka的消費者將訊息寫入Cassandra叢集、可以將Kafka接受到的資料作為Apache Strom 的Spout,直接送入Strom的管道(進行實時分析)。如果您要將日誌寫入HDFS檔案系統,則可以直接使用Flume(這個在後續的示例方案中會講到)。不過,請別做愚蠢的事情:不要將日誌資料送入任何關係型資料庫。
- 業務層實現示圖
在接下來的方案演示中我們假定業務系統基於JAVA,並且已經集成了Spring框架。由於在本方案中我們使用了過濾器(Filters)/攔截器(Interceptor)隔離操作日誌,所以業務服務中怎樣進行業務層和資料層的處理本方案可以不必過多關注:
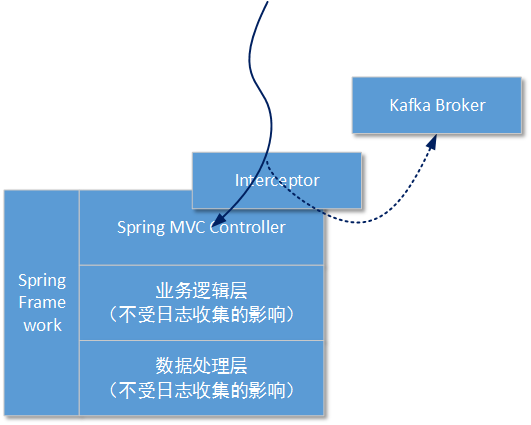
這樣做的好處是,可以將對日誌的攔截操作在執行真正的業務操作前進行隔離,業務處理程式碼不需要關心在這之前都有多少層攔截,只需要按照原有的處理邏輯執行就行。
5-2-2、編碼過程:生產者和業務系統整合
- 準備工作
演示的業務工程將使用Spring-MVC元件,所以如果您需要檢視演示效果,請在工程中匯入Spring-MVC元件(V3.2.X的版本都行):
- 1
- 2
- 3
- 4
- 5
- 業務系統端整合
為了讓更多的讀者理解整個過程,我們首先來看一下這個攔截器的使用方式:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
以上程式碼片段是一個基於Spring-MVC元件編寫的Http Controller層的類,名叫UserController(當然這個類是被Spring Ioc容器託管了)。在瀏覽器上我們可以使用 http://ip:port/queryAllUser 這樣的URL訪問到queryAllUserWithoutParent方法。
請注意在queryAllUserWithoutParent方法上,我們使用了一個“@LogAnnotation”自定義註解。這個註解表示:當方法被呼叫時,這個業務系統需要向 事件/日誌收集系統 傳送日誌資訊。
- LogAnnotation註解的定義
“@LogAnnotation”註解的定義非常簡單,畢竟它只是一個標識,並不是整個結構能夠執行起來的核心動力。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 使用Spring-MVC的Interceptor攔截器,對HTTP請求進行攔截
好了,為了讓以上的程式碼能夠執行起來。我們需要使用基於Spring-MVC的Interceptor攔截器,對HTTP請求進行攔截。讓它在正式到達(執行)queryAllUserWithoutParent方法前,能夠先被攔截器預先處理。首先我們需要定義一個攔截器,如下所示:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
所有的Spring-MVC Interceptor都要繼承一個父類:org.springframework.web.servlet.handler.HandlerInterceptorAdapter,當然Interceptor也是被Spring-Ioc容器託管的。為了使用Interceptor,您需要在配置檔案中加入相應的資訊:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在HandlerInterceptorAdapter父類中,我們可以按照自身的需要選擇性的重寫preHandle方法、postHandle方法、afterCompletion方法或者afterConcurrentHandlingStarted方法。從這些方法名稱就可以明白這些方法所代表的含義。這裡我們選擇過載其中的preHandle預處理方法。
請注意HandlerInterceptorAdapter類中定義的物件“private ProducerService producerService”。這個物件就是由 事件/日誌收集系統提供的JAVA 客戶端開發包中的主要服務類。第三方業務系統需要使用這個服務類和 事件/日誌收集系統 進行通訊。
- 客戶端開發包中的ProducerService定義和實現:
以下是生產者介面定義
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
以下是生產者介面實現: