
Spark 定製版:015~Spark Streaming原始碼解讀之No Receivers徹底思考
本講內容:
a. Direct Acess
b. Kafka
注:本講內容基於Spark 1.6.1版本(在2016年5月來說是Spark最新版本)講解。
上節回顧
上一講中,我們講Spark Streaming中一個非常重要的內容:State狀態管理
a. 為了說明state狀態管理,拿兩個非常具體非常有價值的方法updateStateByKey和mapWithState這兩個方法來說明sparkstreaming是如何實現對state狀態管理的。Sparkstreaming是按照batchduration劃分job的,但是有時我們想算過去一個小時或者過去一天的資料,在大於batchduration的時候對資料進行符合業務邏輯的操作,這時候不可避免的要進行狀態維護。Sparkstreaming每個batchduration都會產生一個job,job裡面都是RDD,所以現在面臨的一個問題就是,他每個batchduration產生RDD,怎麼對他的狀態進行維護的問題(像updateStateByKey)。例如計算一天的商品的點選量,這時候就需要類似於updateStateByKey或者mapWithState這樣的方法幫助完成核心的步驟
b. Spark 的狀態管理其實有很多函式,比較典型的有類似的UpdateStateByKey、MapWithState方法來完成核心的步驟
updateStateByKey和mapWithState這兩個方法在DStream中並不能找到。因為updateStateByKey和mapWithState這兩個方法都是針對key-value型別的資料進行操作,也就是pair型別的,和前邊講RDD是一樣的,RDD這個類本事並不會對key-value型別的資料進行操作,所以這時候就需要藉助scala的語法隱式轉換。隱式轉換一般放在類的伴生物件中,將DStream轉換成PairDStreamFunctions。這是從地獄中召喚出來的功能,使用後又回到地獄。執行機制就是找不到DStream的updateStateByKey和mapWithState,他們是PairDStreamFunctions的方法,就找隱式轉換,隱式轉換中發現toPairDStreamFunctions這個功能,就使用了implicit功能
最後我們附上程式碼執行流程圖:

開講
上一講中主要是使用ReceiverInputDStream,是針對Receiver方式開展的剖析
本講我們之所以用一節課來講No Receivers,是因為企業級Spark Streaming應用程式開發中在越來越多的採用No Receivers的方式。No Receiver方式有自己的優勢,比如更大的控制的自由度、語義一致性等等。所以對No Receivers方式和Receiver方式都需要進一步研究、思考
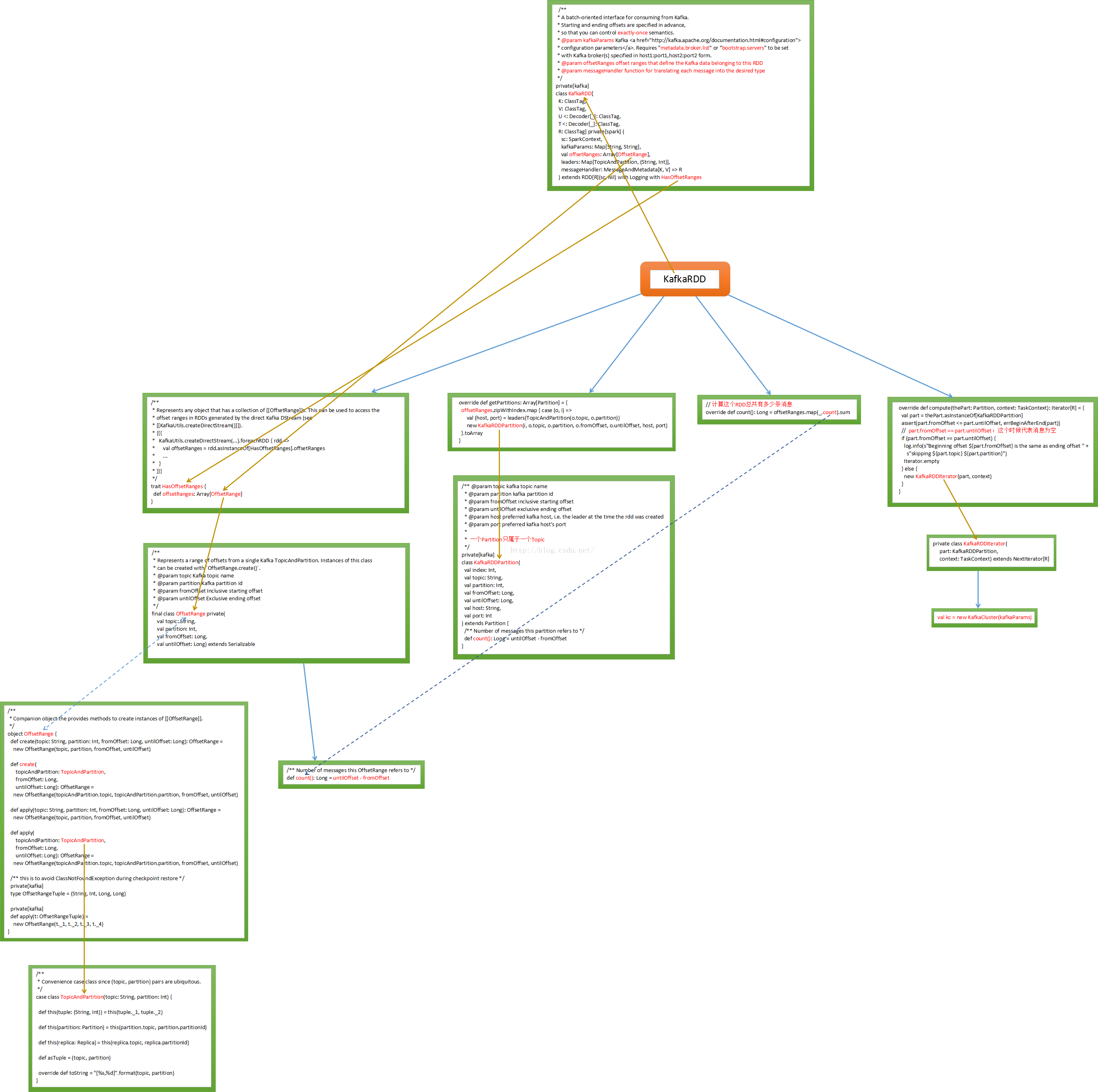
Spark Streaming現在支援兩個方式,一種是Receivers的方式來接收資料的輸入或者對資料的控制,另一種是No Receivers的方式,也就是directAPI。其實No Receivers的方式是更符合讀取資料和操作資料的思路的,因為Spark是一個計算框架,作為一個計算框架底層會有資料來源,如果用No Receivers的方式直接操作資料來源中的資料,這是更自然的一種方式。如果要操作資料來源肯定要有一個封裝器,封裝器肯定是RDD型別的,所以SparkStreaming為了封裝資料推出了一個自定義的RDD叫KafkaRDD
從Kafka中消費資料的一種實現,首先要確定開始和結束的offset來保證exactly-once。
kafkaParams 中最關鍵的是metadata.broker.list,這個broker是kafka中的概念。就是SparkStreaming直接去操作kafka叢集,offsetRanges指的是哪一片資料是這個RDD的。Kafka傳資料的時候會進行編碼所以需要Decoder。直接從kafka中讀取資料需要自定義一個RDD,如果想從Hbase中直接讀資料也需要自定義RDD
所以Spark Streaming就產生了自定義RDD –> KafkaRDD
原始碼分析:
走進KafkaRDD開始探祕之旅
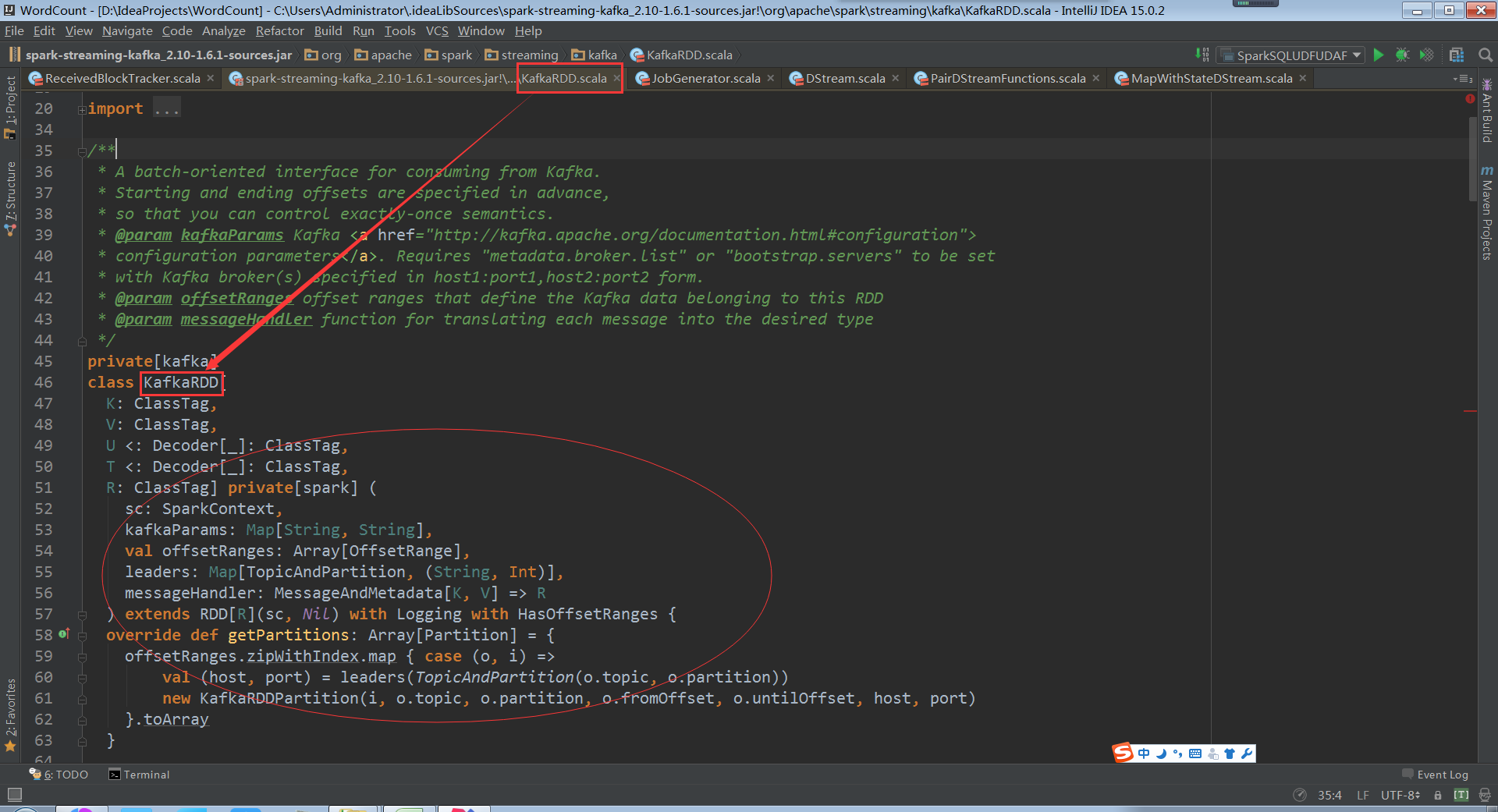
KafkaRDD在繼承RDD的時候也繼承了HasOffsetOranges,這個是必須的,因為RDD天然的是a list of partitions,基於kafka直接訪問RDD時必須是HasOffsetRange型別,代表了來自kafka topicAndParttion,其實力被HasOffsetRange Create建立,從fromOffset到untilOffset ,
分散式傳輸Offset資料時必須序列化
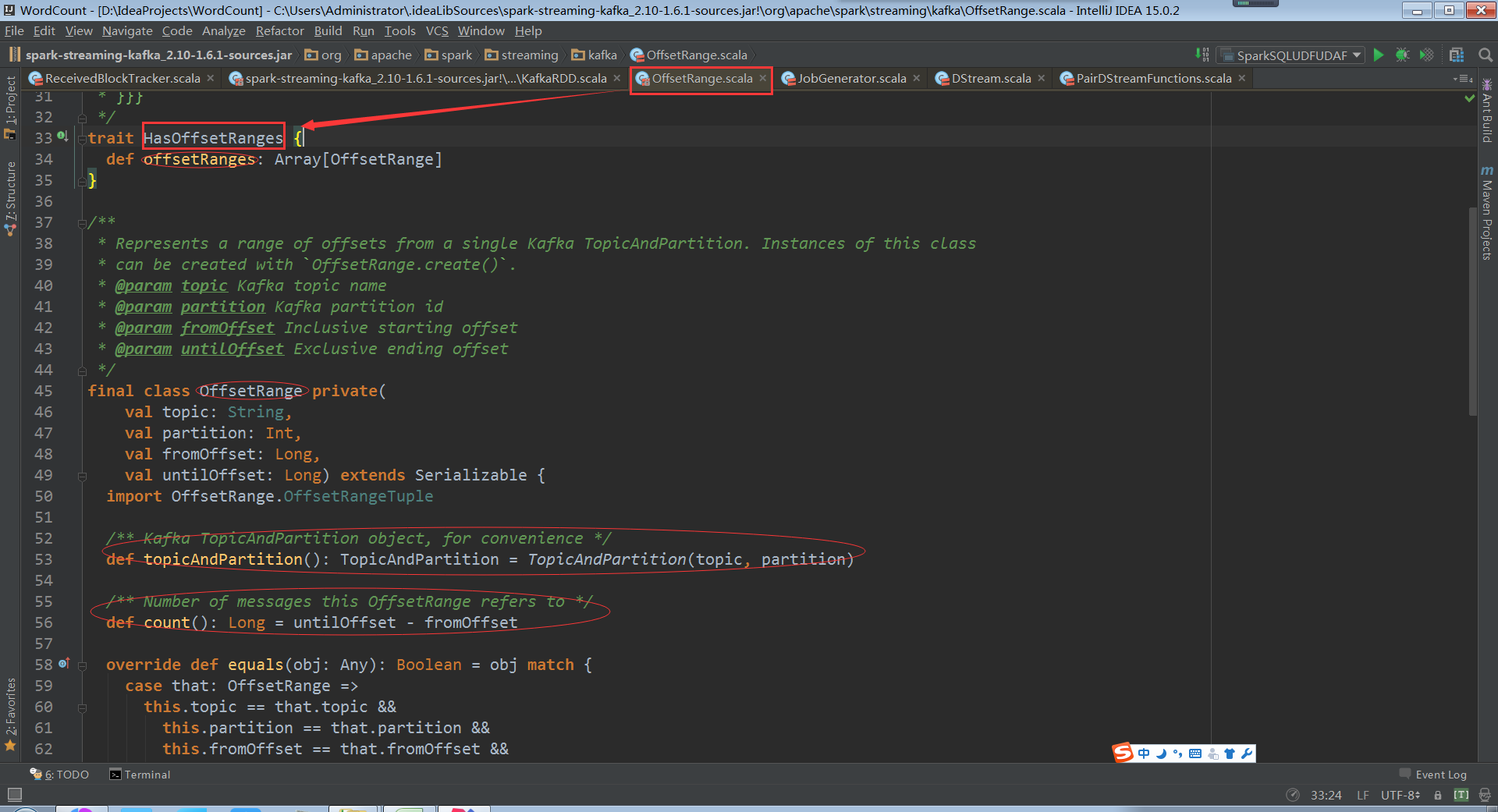
Offset是訊息偏移量,假設untilOffset是10萬,fromOffset是5萬,第10萬條訊息和5萬條訊息,一般處理資料規模大小是以資料條數為單位
建立一個offSetrange例項時可以確定從kafka叢集partition中讀取哪些topic,從foreachrdd中可以獲得當前rdd訪問的所有分割槽資料。Batch Duration中產生的rdd的分割槽資料,這個是對元資料的控制
再看getPartitions方法,offsetRanges指定了每個offsetrange從什麼位置開始到什麼位置結束
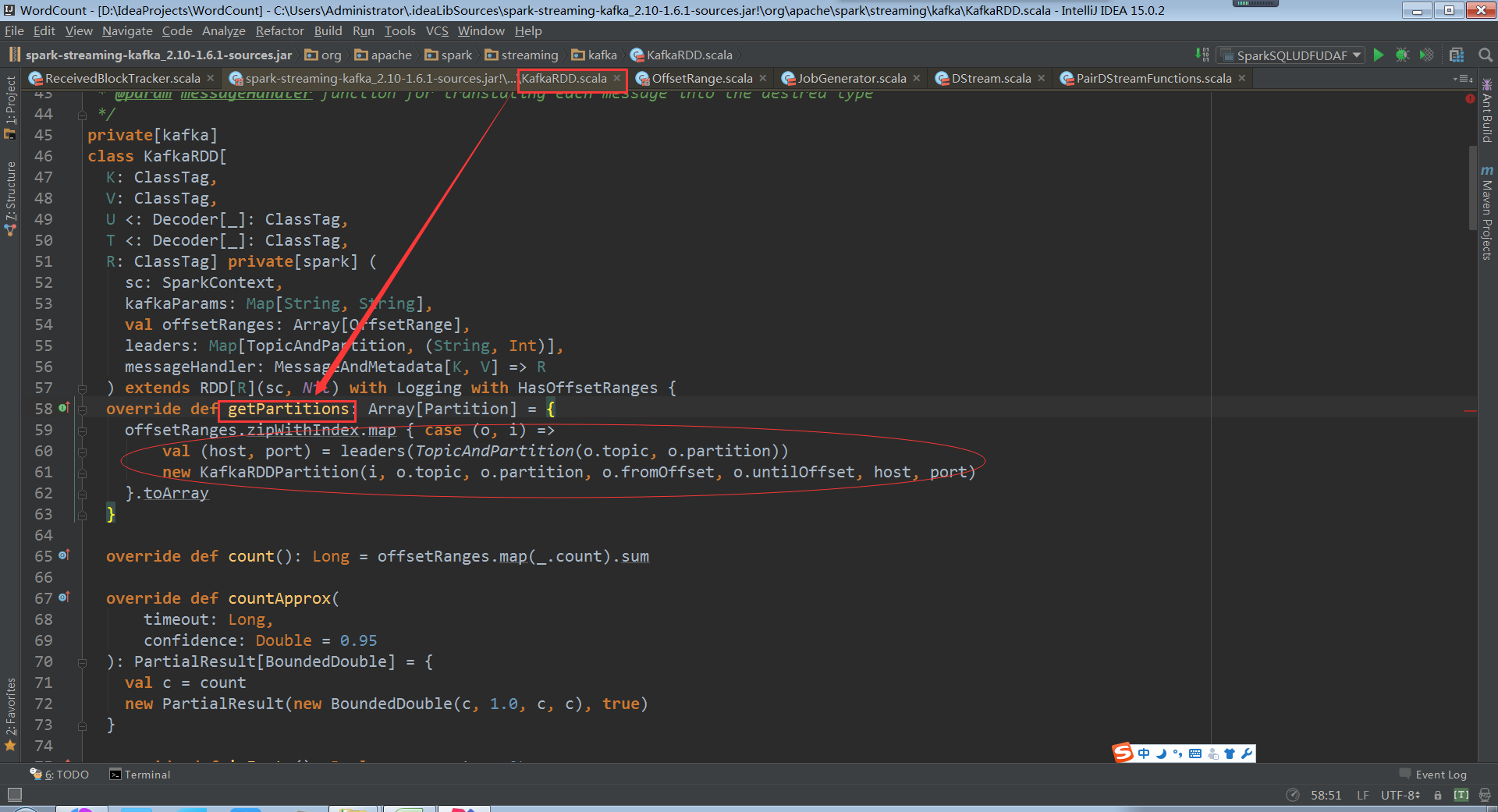
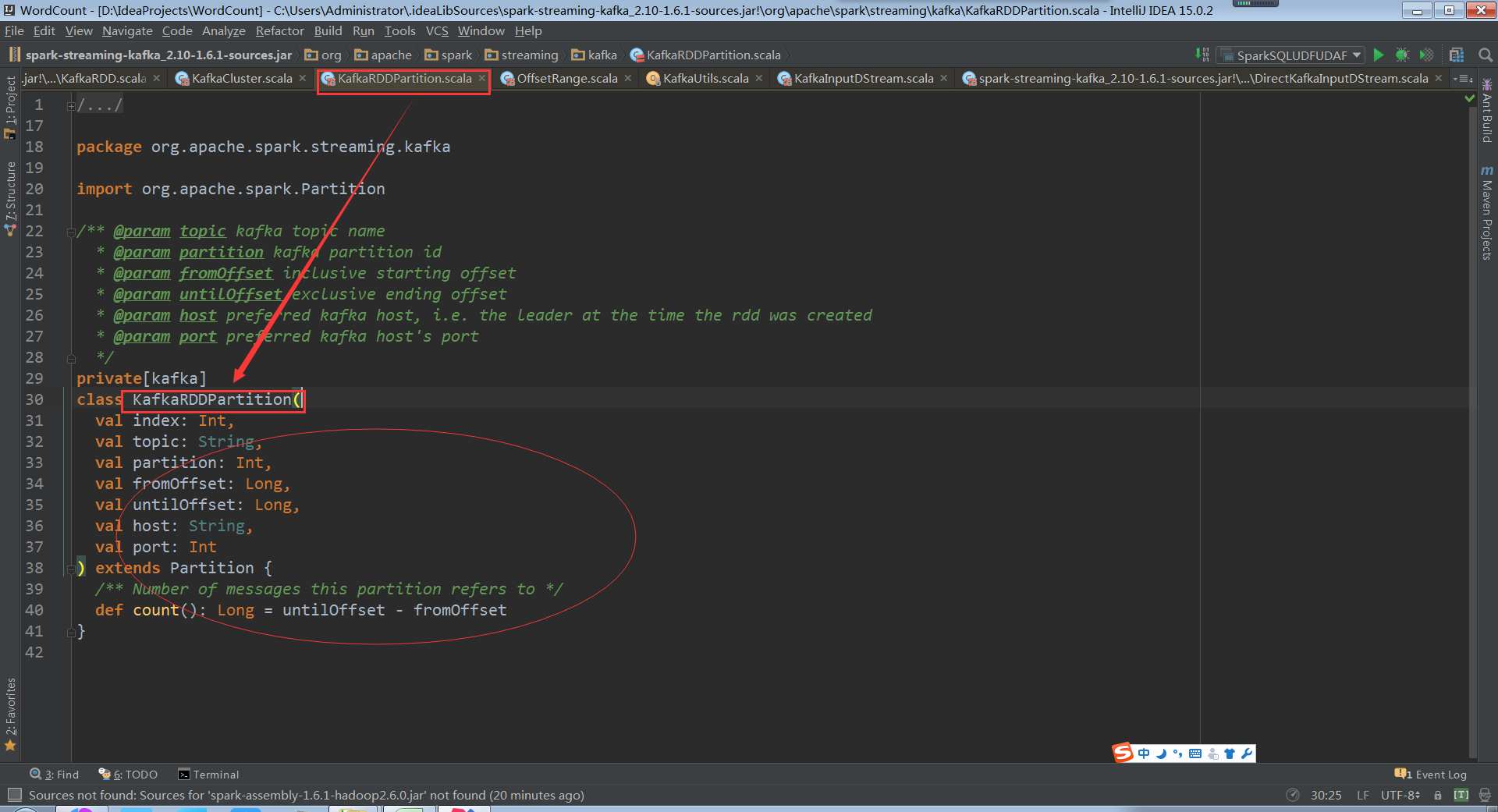
看KafkaRDDPartition類,會從傳入的topic和partition及offset中獲取kafka資料
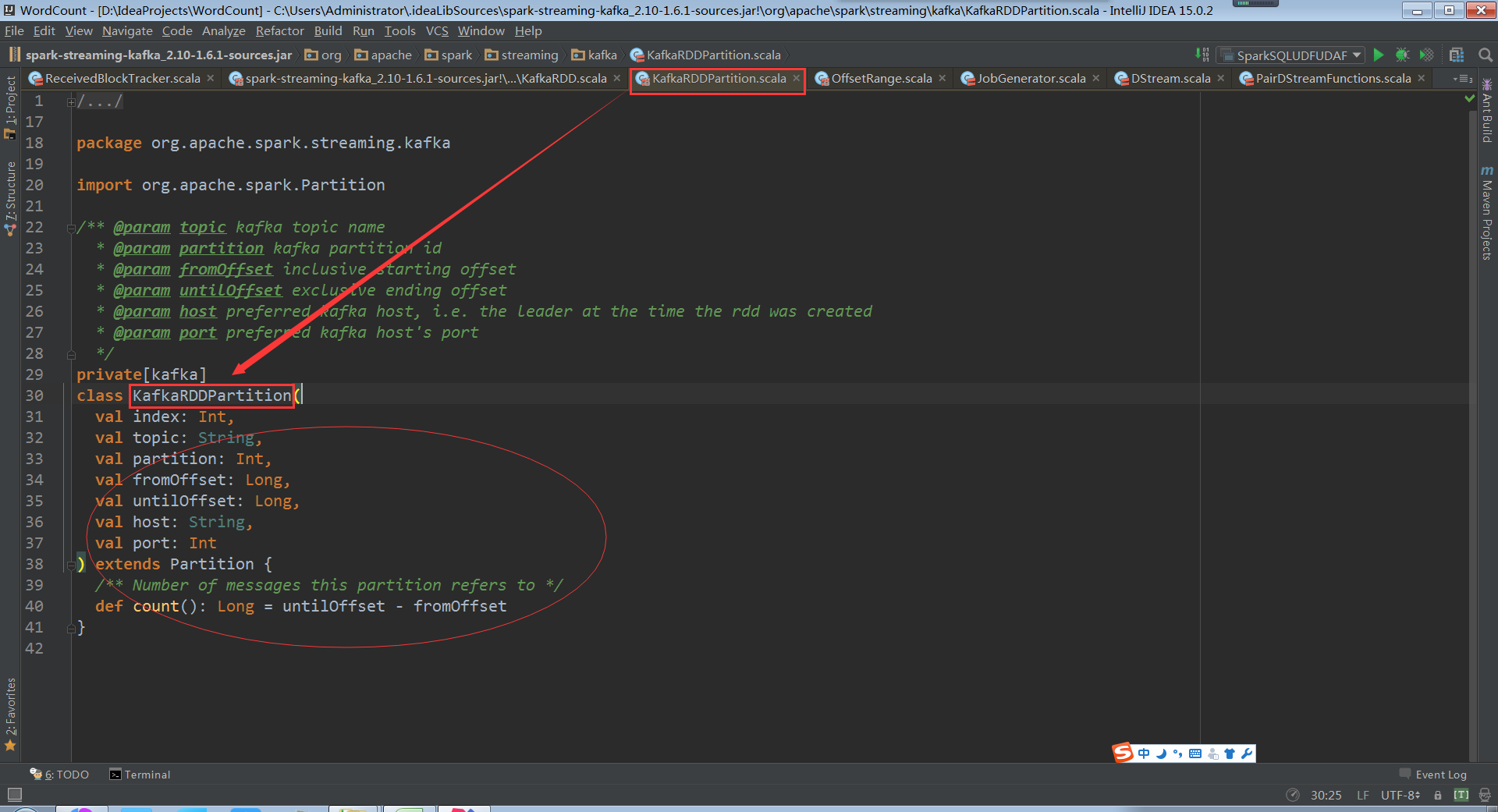
Host port指定讀取資料來源的kfakf機器
看kafka rdd的compute計算每個資料分片,和rdd理念是一樣的,每次迭代操作獲取計算的rdd一部分
操作KafkaRDDIterator和操作rdd分片是一樣的,需要迭代資料分片
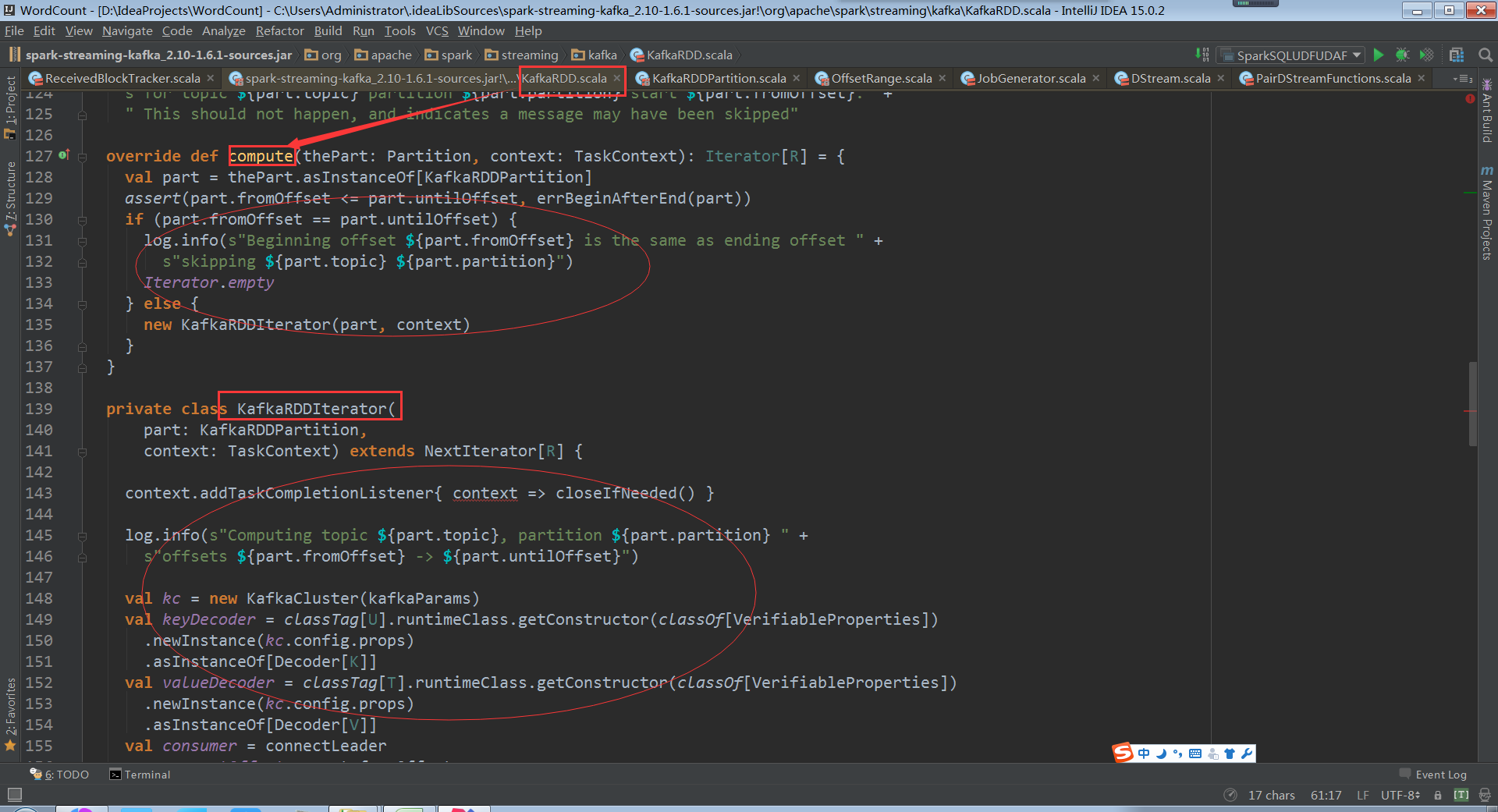
關鍵的地方kafkaCluster物件時在kafkaUtils中直接建立了directStream,看下之前操作kafka程式碼發現傳入的引數是上下文、 broker.List.topic.list引數
構建時傳入topics為Set,當然可以直接指定ranges,他從kafka叢集直接建立了kafkaCluster和叢集進行互動,從fromOffset獲取資料具體的偏移量
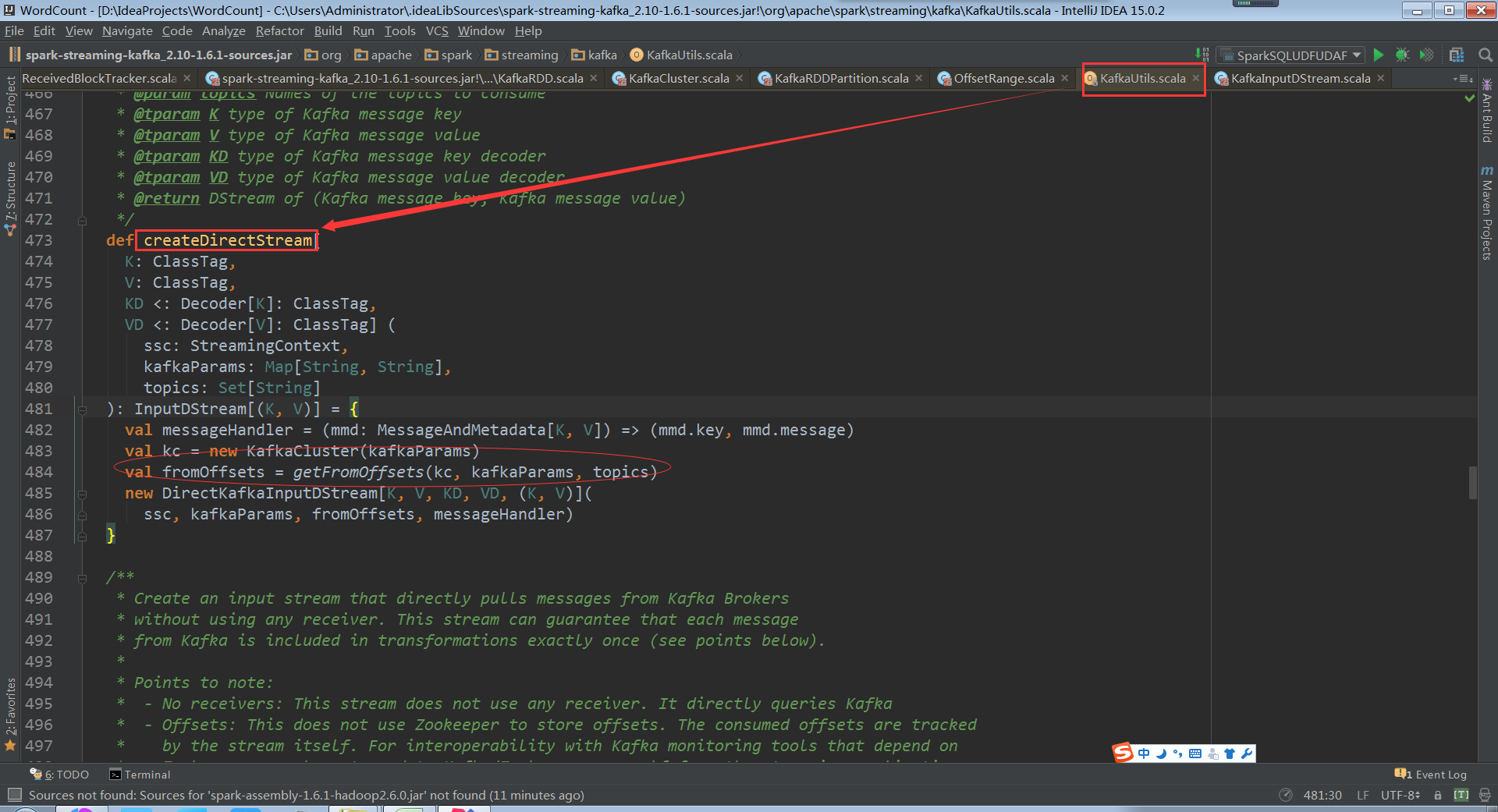
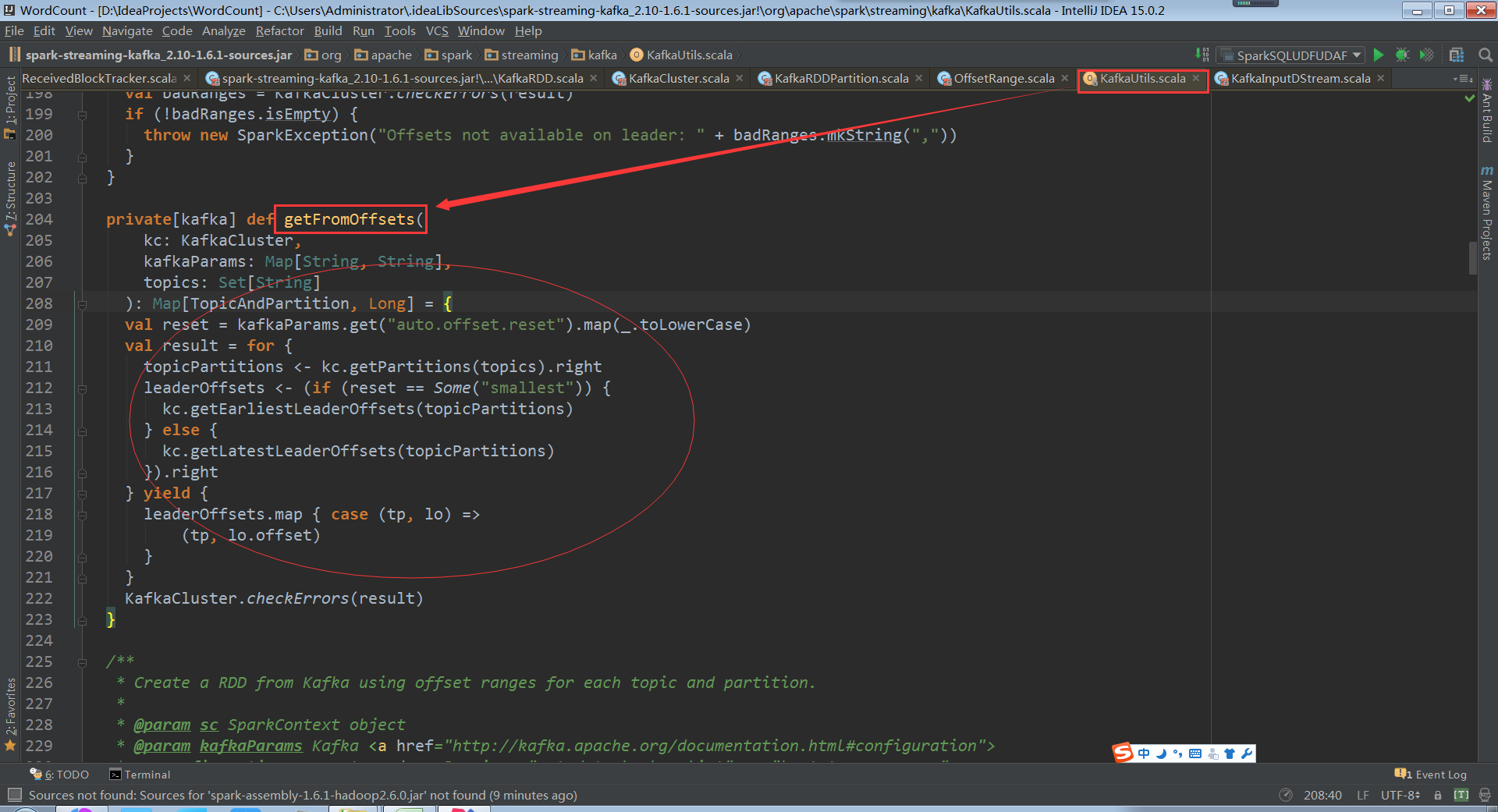
如果不知道fromOffsets的話直接從配置中獲取fromOffsets,建立kafka DirectKafkaInputDStream的時候會從kafka叢集進行互動獲得partition、offset資訊,通過DirectKafkaInputDStream無論什麼情況最後都會建立DirectKafkaInputDStream
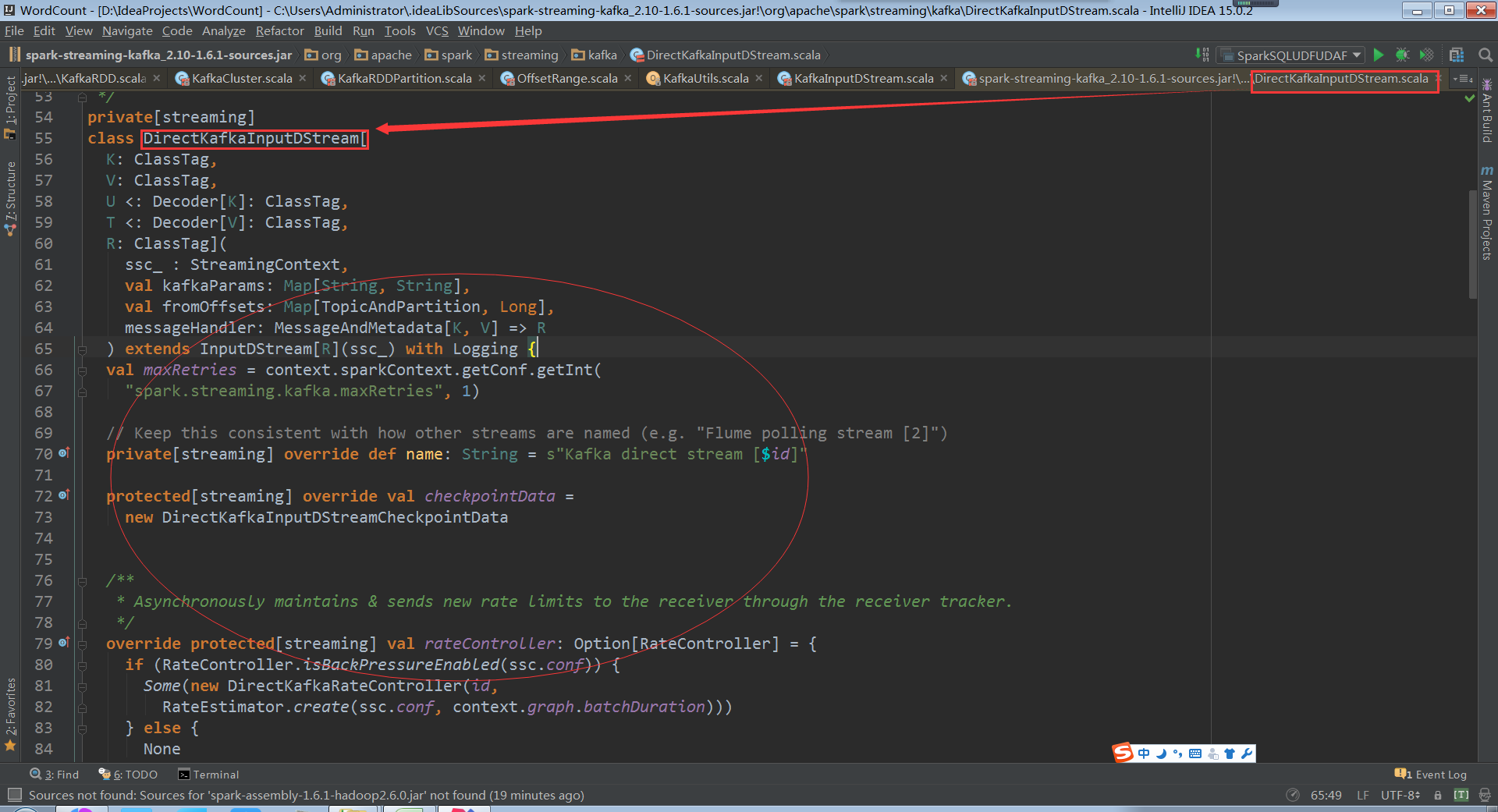
DirectKafkaInputDStream會產生kafkaRDD,不同的topic partitions生成對應的的kafkarddpartitions,控制消費讀取速度。操作資料的時候是compute直接構建出kafka rdd,讀取kafka 上的資料。確定獲取讀取資料的期間就知道需要讀取多少條資料,然後構建kafkardd例項。Kafkardd的例項和DirectKafkaInputDStream是一一對應的,每次compute會產生一個kafkardd,其會包含很多partitions,有多少partition就是對應多少kafkapartition
看下KafkaRDDPartition就是一個簡單的資料結構
總結:
而且KafkaRDDPartition只能屬於一個topic,不能讓partition跨多個topic,直接消費一個kafkatopic,topic不斷進來、資料不斷偏移,Offset代表kafka資料偏移量指標。
資料不斷流進kafka,batchDuration假如每十秒都會從配置的topic中消費資料,每次會消費一部分直到消費完,下一個batchDuration會再流進來的資料,又可以從頭開始讀或上一個資料的基礎上讀取資料。
Direct的方式相比Receivers的方式的優勢:
a. Direct的方式沒有快取,也就不用擔心出現記憶體溢位的問題。如果是Receivers的方式就存在快取
b. 如果是Receivers的方式,Receivers是和具體的worker繫結,Receivers的方式不方便做分散式,當然配置一下是可以做分散式的。Direct的方式預設資料就會在多個executor上
c. 資料消費的問題,我們在實際操作的時候,如果是Receivers的方式假如資料來不及處理,資料操作delazy之後,delazy多次的話,sparkstreaming程式就會崩潰。如果是Direct的方式就不存在這種情況
d. Direct的方式完全的語義一致性。不會重複消費,並且確保資料一定被消費。Direct的方式是和kafka進行互動,只有資料被真正的執行成功才會被記錄下來
e. Direct的方式比Receivers的方式速度快。對Direct的方式資料流進的速度的配置是對每個partition進行配置
f. Sparkstreaming還有一個配置是backpressure,這個引數可以試探一下資料流進來的速度和處理能力是否一致,如果處理不一致可以動態的進行調整,也就是資源的動態調整
生產環境下強烈建議採用direct方式讀取kafka資料
Kafka Direct方式的程式碼執行流程的原始碼和重要程式碼流程圖
相關推薦
Spark 定製版:015~Spark Streaming原始碼解讀之No Receivers徹底思考
本講內容: a. Direct Acess b. Kafka 注:本講內容基於Spark 1.6.1版本(在2016年5月來說是Spark最新版本)講解。 上節回顧 上一講中,我們講Spark Streaming中一個非常重要的內容:State狀態管理
第15課:Spark Streaming原始碼解讀之No Receivers徹底思考
背景: 目前No Receivers在企業中使用的越來越多。No Receivers具有更強的控制度,語義一致性。No Receivers是我們操作資料來源自然方式,操作資料來源使用一個封裝器,且是RDD型別的。所以Spark Streaming就產生了自定義R
Spark Streaming原始碼解讀之No Receivers詳解
背景: 目前No Receivers在企業中使用的越來越多。No Receivers具有更強的控制度,語義一致性。No Receivers是我們操作資料來源自然方式,操作資料來源使用一個封裝器,且是RDD型別的。所以Spark Streaming就產生了自定義
Spark 定製版:013~Spark Streaming原始碼解讀之Driver容錯安全性
本講內容: a. ReceiverBlockTracker容錯安全性 b. DStreamGraph和JobGenerator容錯安全性 注:本講內容基於Spark 1.6.1版本(在2016年5月來說是Spark最新版本)講解。 上節回顧 上一講中,
Spark 定製版:010~Spark Streaming原始碼解讀之流資料不斷接收全生命週期徹底研究和思考
本講內容: a. 資料接收架構設計模式 b. 資料接收原始碼徹底研究 注:本講內容基於Spark 1.6.1版本(在2016年5月來說是Spark最新版本)講解。 上節回顧 上一講中,我們給大傢俱體分析了Receiver啟動的方式及其啟動設計帶來的多個
Spark 定製版:004~Spark Streaming事務處理徹底掌握
本講內容: a. Exactly Once b. 輸出不重複 注:本講內容基於Spark 1.6.1版本(在2016年5月來說是Spark最新版本)講解。 上節回顧: 上節課通過案例透視了Spark Streaming Job架構和執行機,並結合原
Spark定製班第9課:Spark Streaming原始碼解讀之Receiver在Driver的精妙實現全生命週期徹底研究和思考
本期內容: 1. Receiver啟動的方式設想 2. Receiver啟動原始碼徹底分析 1. Receiver啟動的方式設想 Spark Streaming是個執行在Spark Core上的應用程式。這個應用程式既要接收資料,還要處理資料,這些都是在分散式的
Spark Streaming原始碼解讀之Receiver在Driver的精妙實現全生命週期徹底研究和思考
在Spark Streaming中對於ReceiverInputDStream來說,都是現實一個Receiver,用來接收資料。而Receiver可以有很多個,並且執行在不同的worker節點上。這些Receiver都是由ReceiverTracker來管理的。
Spark Streaming原始碼解讀之資料清理內幕徹底解密
本篇部落格的主要目的是: 1. 理清楚Spark Streaming中資料清理的流程 組織思路如下: a) 背景 b) 如何研究Spark Streaming資料清理? c) 原始碼解析
Spark Streaming原始碼解讀之Driver中的ReceiverTracker詳解
本篇博文的目標是: Driver的ReceiverTracker接收到資料之後,下一步對資料是如何進行管理 一:ReceiverTracker的架構設計 1. Driver在Executor啟動Receiver方式,每個Receiver都封裝成一個Tas
Spark Streaming原始碼解讀之State管理之updateStateByKey和mapWithState解密
源地址:http://blog.csdn.net/snail_gesture/article/details/5151058 背景: 整個Spark Streaming是按照Batch Duractions劃分Job的。但是很多時候我們需要算過去的一天甚
Spark定製版2:通過案例對SparkStreaming透徹理解三板斧之二
本節課主要從以下二個方面來解密SparkStreaming: 一、解密SparkStreaming執行機制 二、解密SparkStreaming架構 SparkStreaming執行時更像SparkCore上的應用程式,SparkStreaming程式啟動後會啟動很
Spark——Streaming原始碼解析之容錯
此文是從思維導圖中匯出稍作調整後生成的,思維腦圖對程式碼瀏覽支援不是很好,為了更好閱讀體驗,文中涉及到的原始碼都是刪除掉不必要的程式碼後的虛擬碼,如需獲取更好閱讀體驗可下載腦圖配合閱讀: 此博文共分為四個部分: DAG定義 Job動態生成 資料的產生與匯入 容錯 策略 優點 缺點 (1) 熱備
Spark——Streaming原始碼解析之資料的產生與匯入
此文是從思維導圖中匯出稍作調整後生成的,思維腦圖對程式碼瀏覽支援不是很好,為了更好閱讀體驗,文中涉及到的原始碼都是刪除掉不必要的程式碼後的虛擬碼,如需獲取更好閱讀體驗可下載腦圖配合閱讀: 此博文共分為四個部分: DAG定義 Job動態生成 資料的產生與匯入 容錯 資料的產生與匯入主要分為以下五個部分
Spark——Streaming原始碼解析之DAG定義
此文是從思維導圖中匯出稍作調整後生成的,思維腦圖對程式碼瀏覽支援不是很好,為了更好閱讀體驗,文中涉及到的原始碼都是刪除掉不必要的程式碼後的虛擬碼,如需獲取更好閱讀體驗可下載腦圖配合閱讀: 此博文共分為四個部分: DAG定義 Job動態生成 資料的產生與匯入 容錯 1. DStream 1.1. RD
Spark運算元[10]:foldByKey、fold 原始碼例項詳解
foldByKey與aggregateByKey,fold與aggregate用法相近,作用相似! foldByKey是aggregateByKey的簡化,fold是aggregate的簡化。
<spark> error:啟動spark後查看進程,進程中master和worker進程沖突
告訴 若有 master 沖突 存在 查看進程 spark 但是 文件 啟動hadoop再啟動spark後jps,發現master進程和worker進程同時存在,調試了半天配置文件。 測試發現,當我關閉hadoop後 worker進程還是存在, 但是,當我再關閉spar
Spark On Yarn:提交Spark應用程式到Yarn
Spark On Yarn模式配置非常簡單,只需要下載編譯好的Spark安裝包,在一臺帶有Hadoop Yarn客戶端的機器上解壓,簡單配置之後即可使用。 要把Spark應用程式提交到Yarn執行,首先需要配置HADOOP_CONF_DIR或者YARN_C
Spark學習筆記:初識Spark
=。= // 將users中的vertex屬性新增到graph中,生成graph2 // 使用joinVertices操作,用user中的屬性替換圖中對應Id的屬性 // 先將圖中的頂點屬
Spark MLlib原始碼解讀之樸素貝葉斯分類器,NaiveBayes
Spark MLlib 樸素貝葉斯NaiveBayes 原始碼分析 基本原理介紹 首先是基本的條件概率求解的公式。 P(A|B)=P(AB)P(B) 在現實生活中,我們經常會碰到已知一個條件概率,求得兩個時間交換後的概率的問題。也就是在已知P(A