
Spark 定製版:013~Spark Streaming原始碼解讀之Driver容錯安全性
本講內容:
a. ReceiverBlockTracker容錯安全性
b. DStreamGraph和JobGenerator容錯安全性
注:本講內容基於Spark 1.6.1版本(在2016年5月來說是Spark最新版本)講解。
上節回顧
上一講中,我們從安全形度來講解Spark Streaming,由於Spark Streaming會不斷的接收資料、不斷的產生job、不斷的提交job。所以資料的安全性至關重要。
首先我們來談談,對於資料安全性的考慮:
a. Spark Streaming是基於Spark Core之上的,如果能夠確保資料安全可好的話,在Spark Streaming生成Job的時候裡面是基於RDD,即使執行的時候出現問題,那麼Spark Streaming也可以藉助Spark Core的容錯機制自動容錯
b. 對於executor的安全容錯主要是資料的安全容錯。Executor計算時候的安全容錯是藉助Spark core的RDD的,所以天然是安全的
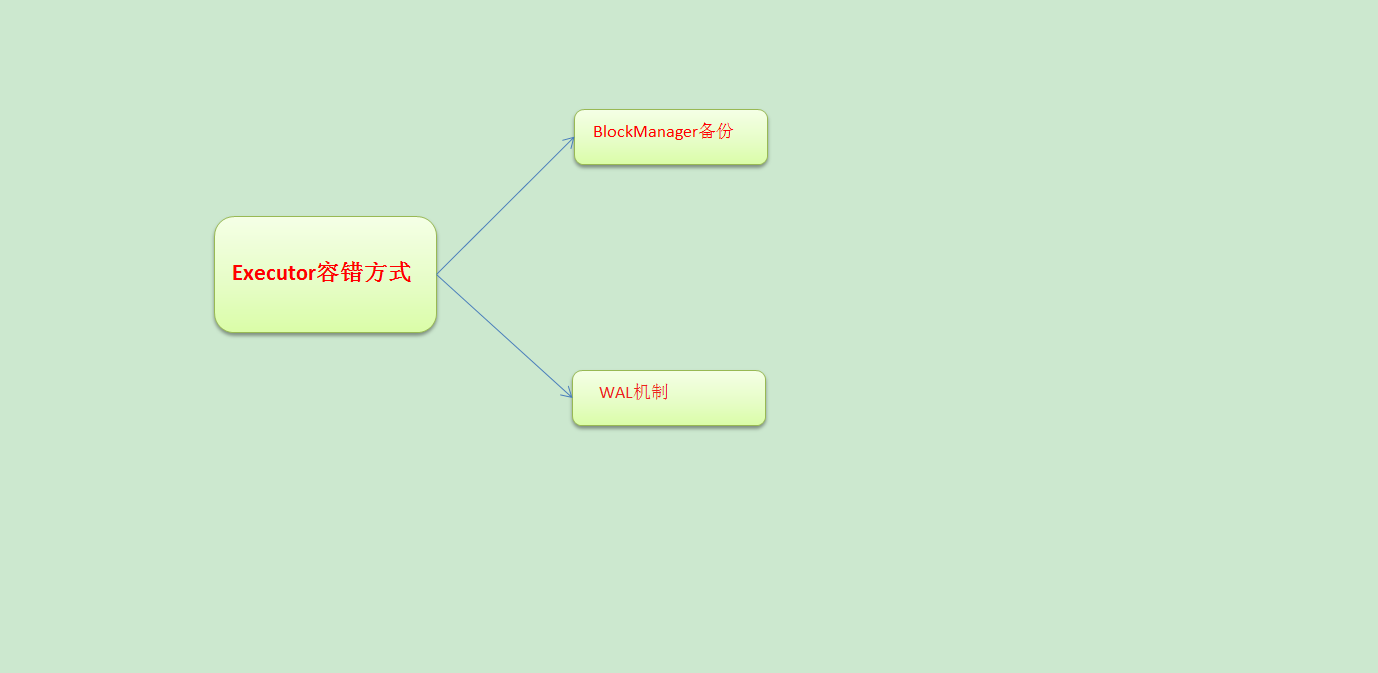
那麼Executor容錯方式是什麼呢?
a. 最簡單的容錯是副本方式,基於底層BlockManager副本容錯,也是預設的容錯方式
b. 接收到資料之後不做副本,支援資料重放,所謂重放就是支援反覆讀取資料
開講
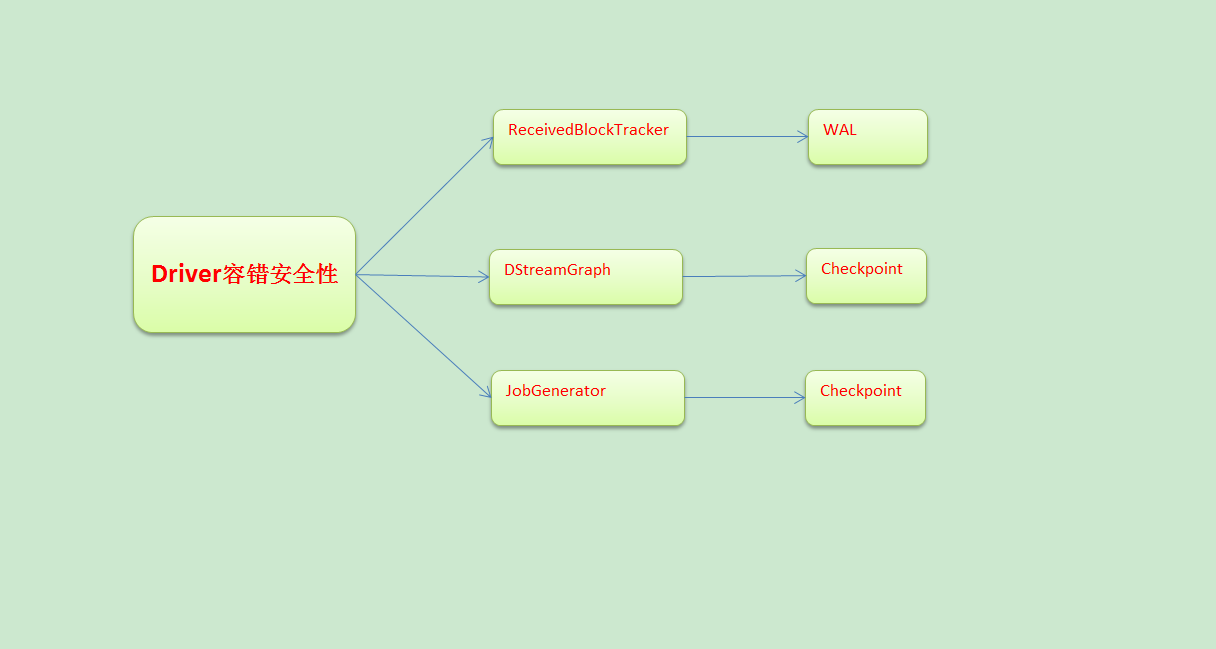
本講我們從Spark Streaming原始碼解讀Driver容錯安全性:那麼什麼是Driver容錯安全性呢?
a. 從資料層面:ReceivedBlockTracker為整個Spark Streaming應用程式記錄元資料資訊
b. 從排程層面:DStreamGraph和JobGenerator是Spark Streaming排程的核心,記錄當前排程到哪一進度,和業務有關
c. 從執行角度: 作業生存層面,JobGenerator是Job排程層面
談Driver容錯性我們需要考慮Driver中有那些需要維持狀態的執行
a. ReceivedBlockTracker跟蹤了資料,因此需要容錯。通過WAL方式容錯
b. DStreamGraph表達了依賴關係,恢復狀態的時候需要根據DStream恢復計算邏輯級別的依賴關係。通過checkpoint方式容錯
c. JobGenerator表面是基於ReceiverBlockTracker中的資料,以及DStream構成的依賴關係不斷的產生Job的過程。也可以這麼理解這個過程中消費了那些資料,並且跟蹤進行到了一個怎樣的程度
具體分析如下圖:
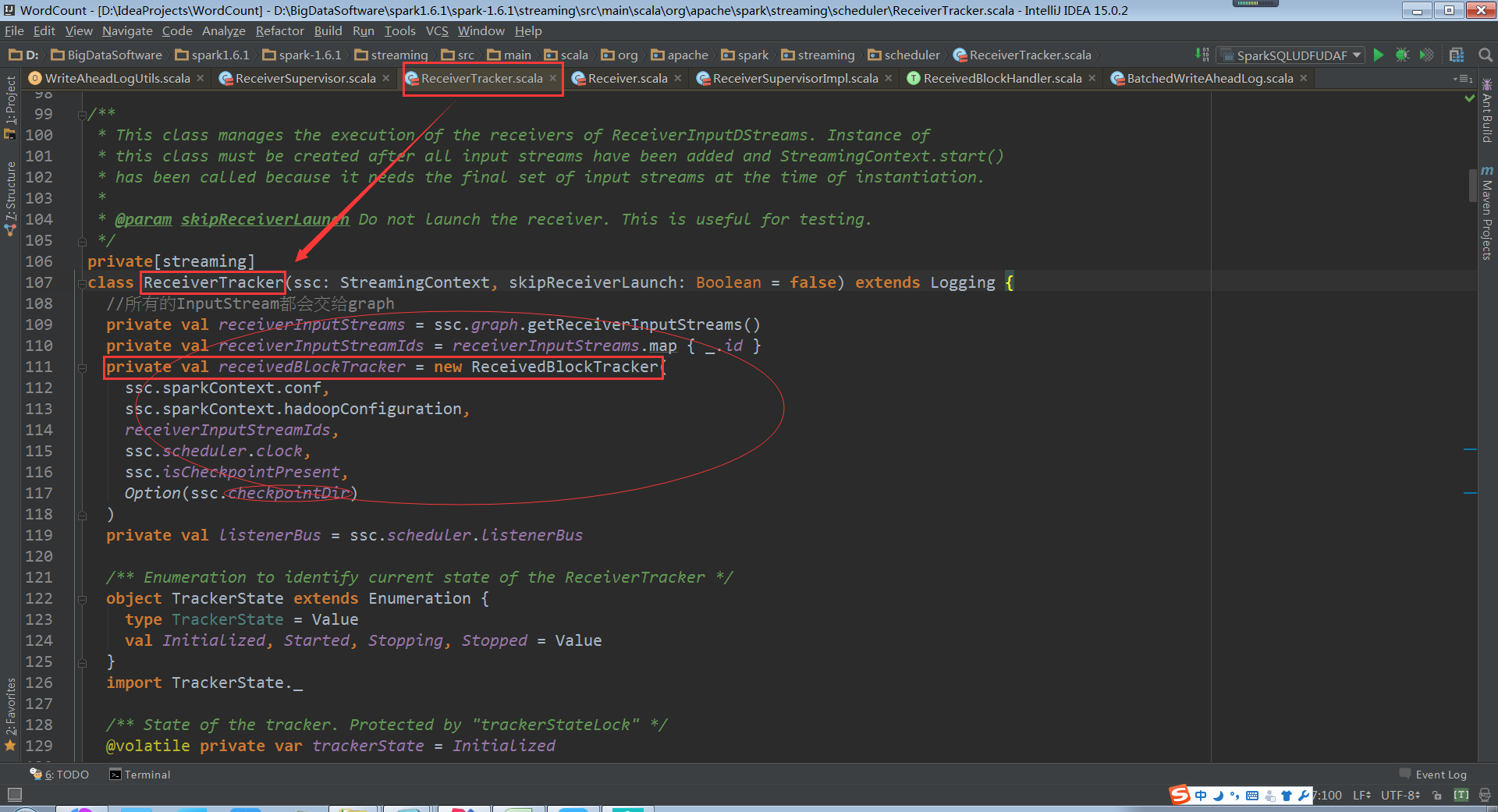
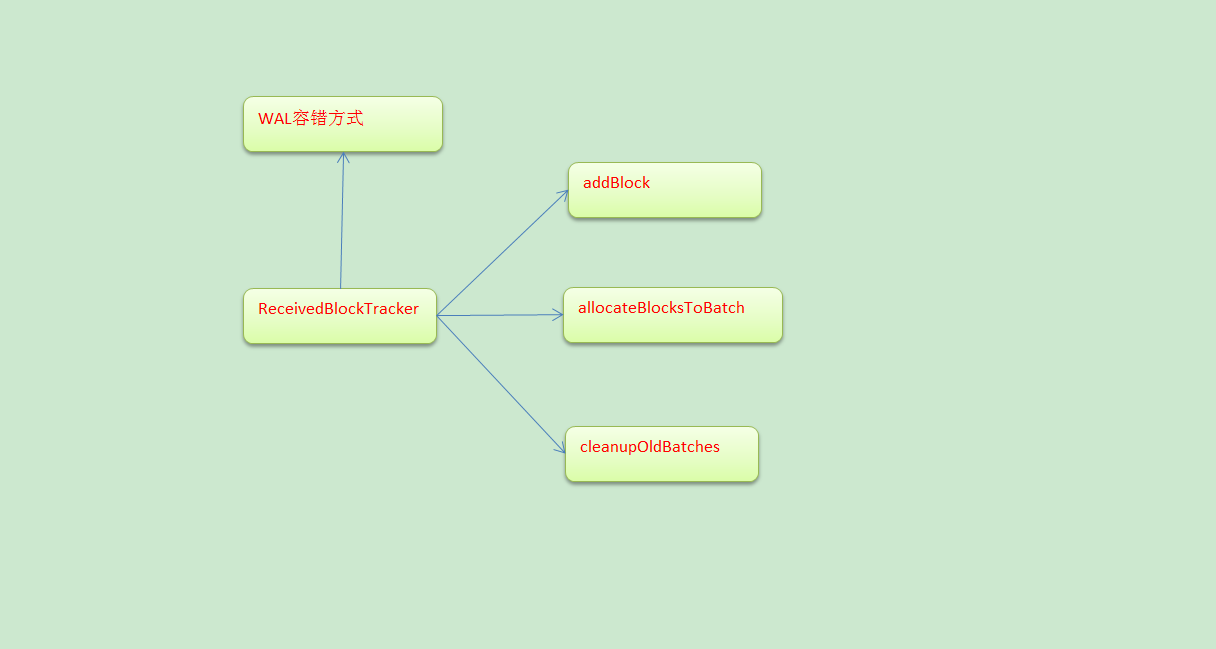
ReceivedBlockTracker
ReceivedBlockTracker會管理Spark Streaming執行過程中所有的資料。並且把資料分配給需要的batches,所有的動作都會被WAL寫入到Log中,Driver失敗的話,就可以根據歷史恢復tracker狀態,在ReceivedBlockTracker建立的時候,使用checkpoint儲存歷史目錄
下面我們就走進Receiver,解密在收到資料之後,有事怎麼處理的?
Receiver接收到資料,把元資料資訊彙報上來,然後通過ReceiverSupervisorImpl就將資料彙報上來,就直接通過WAL進行容錯
當Receiver的管理者,ReceiverSupervisorImpl把元資料資訊彙報給Driver的時候,正在處理是交給ReceiverBlockTracker. ReceiverBlockTracker將資料寫進WAL檔案中,然後才會寫進記憶體中,被當前的Spark Streaming程式的排程器使用的,也就是JobGenerator使用的。JobGenerator不可能直接使用WAL。WAL的資料在磁碟中,這裡JobGenerator使用的記憶體中快取的資料結構
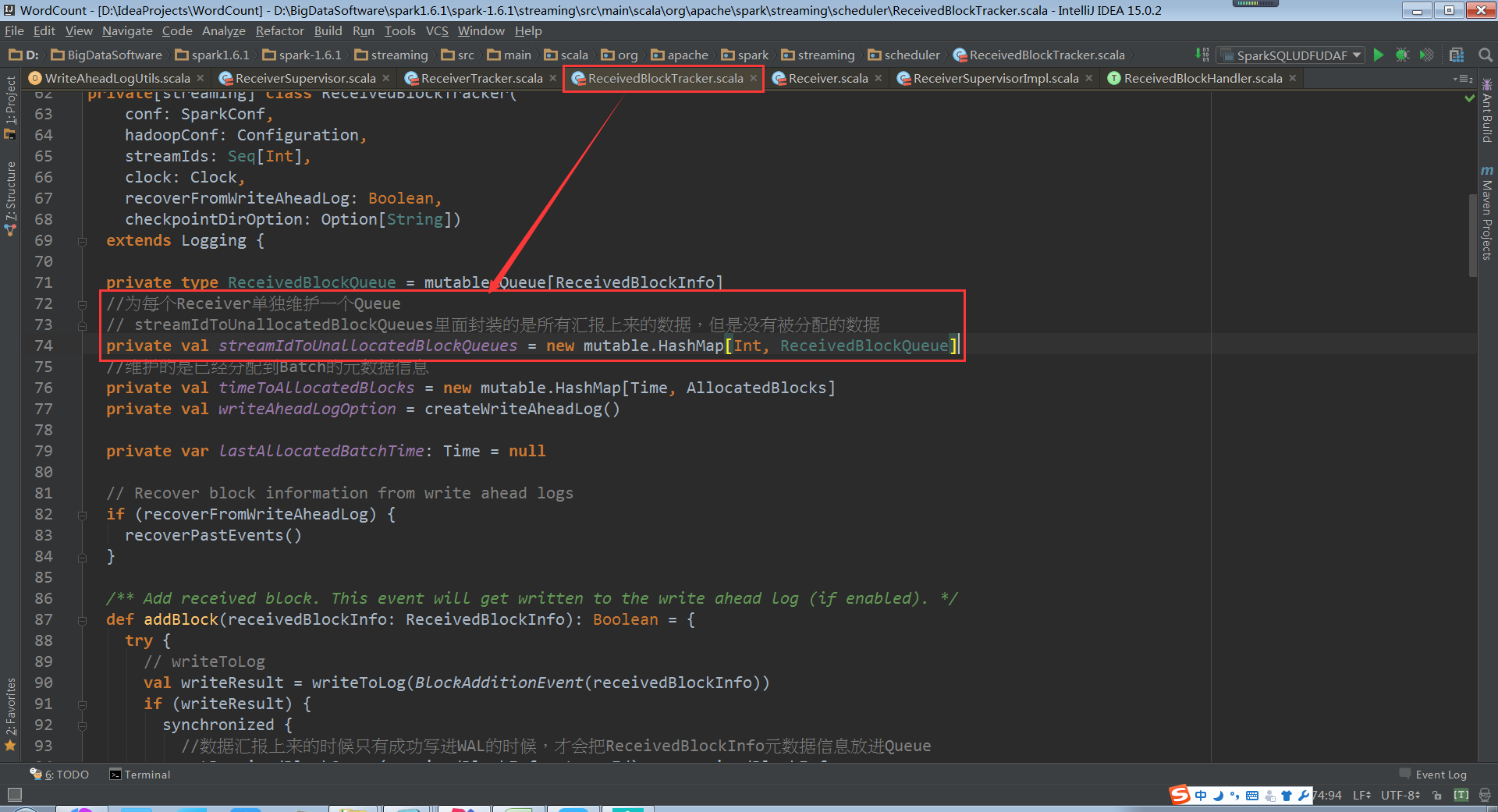
ReceiverBlockTracker.addBlock原始碼
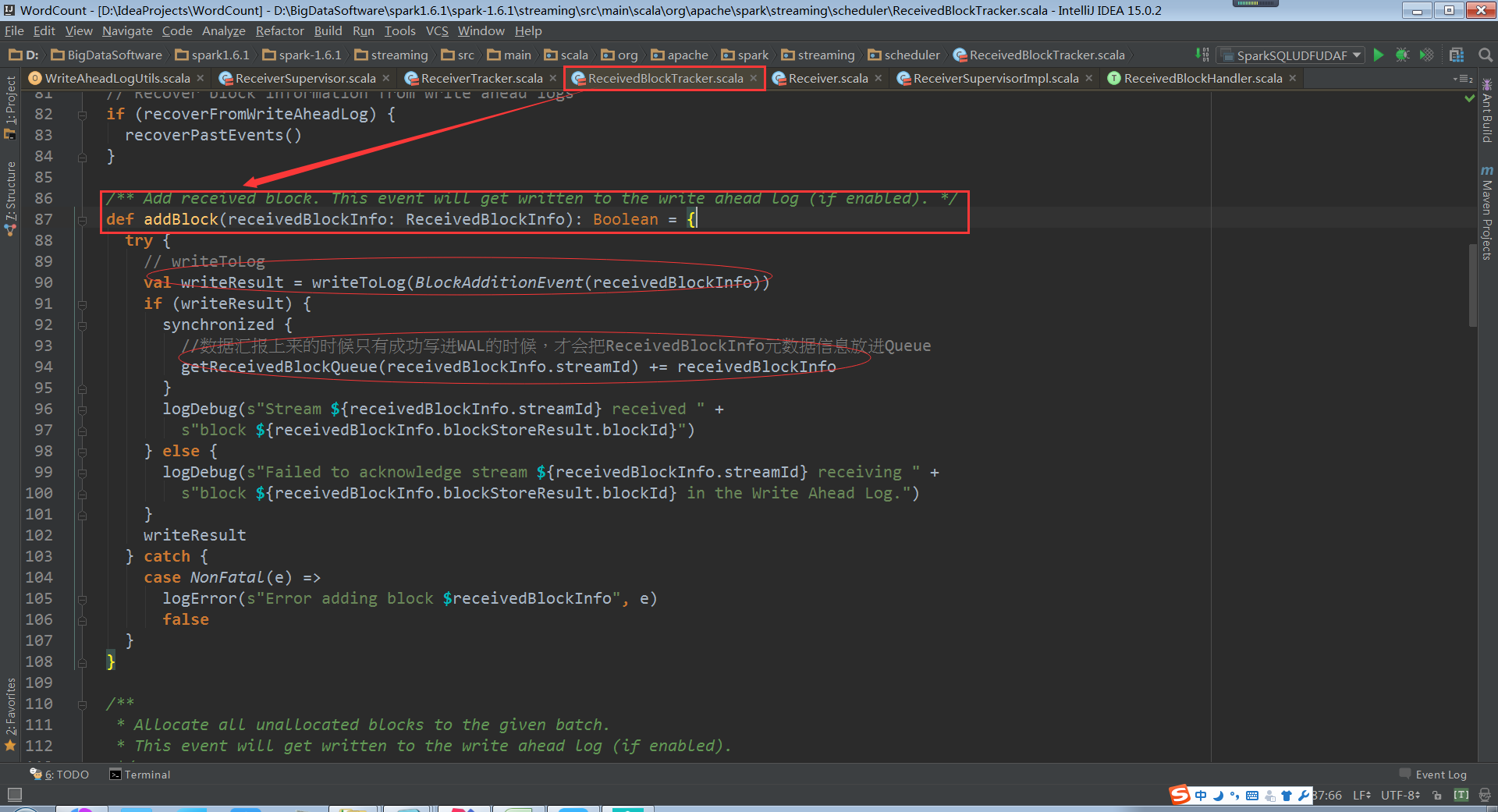
此時的資料結構就是streamIdToUnallocatedBlockQueues,Driver端接收到的資料儲存在streamIdToUnallocatedBlockQueues中
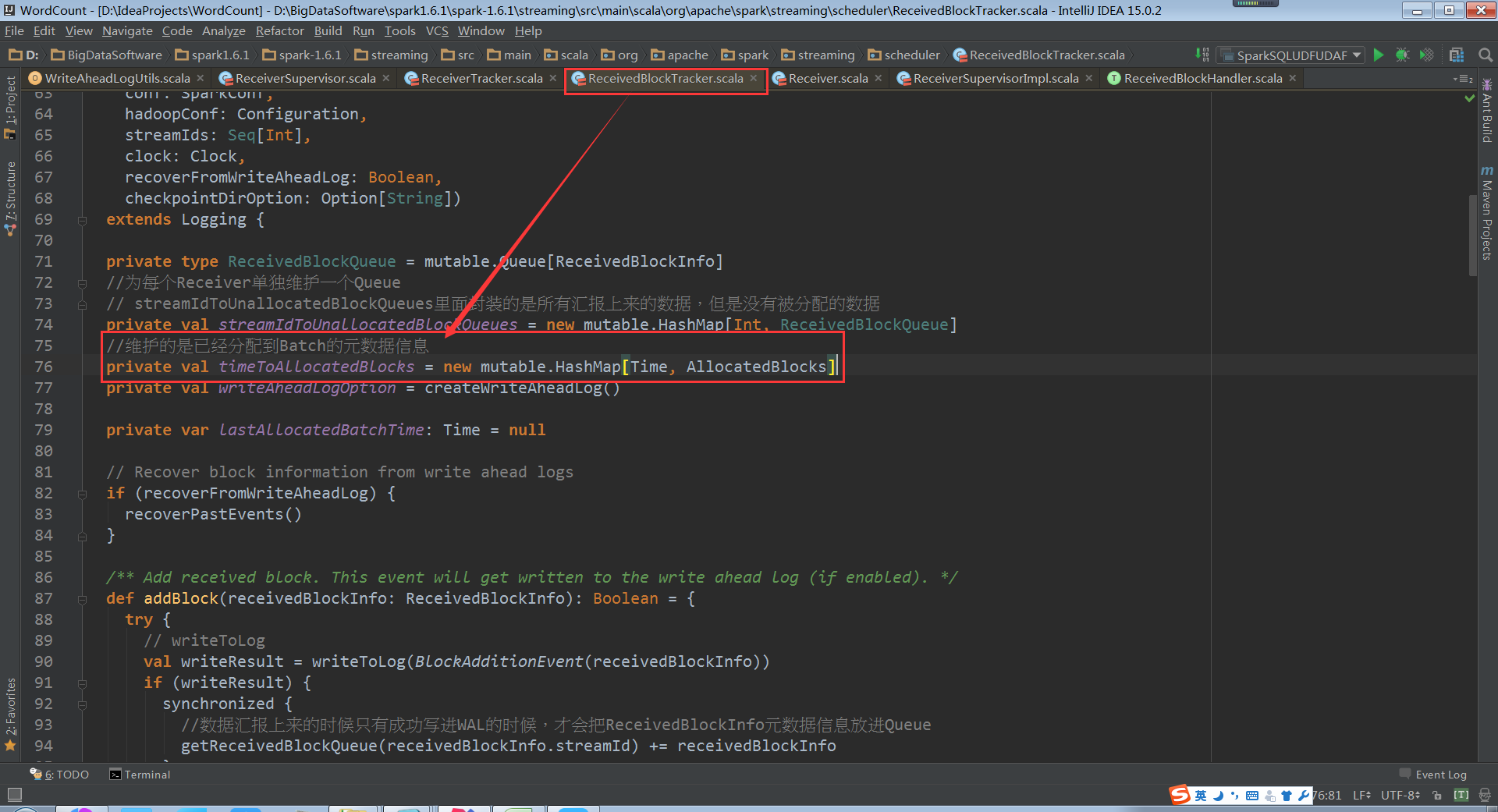
allocateBlocksToBatch把接收到的資料但是沒有分配,分配給batch,根據streamId取出Block,由此就知道Spark Streaming處理資料的時候可以有不同的batchTime(batchTime是上一個Job分配完資料之後,開始再接收到的資料的時間)

timeToAllocatedBlocks可以有很多的時間視窗的Blocks,也就是Batch Duractions的Blocks。這裡面就維護了很多Batch Duractions分配的資料
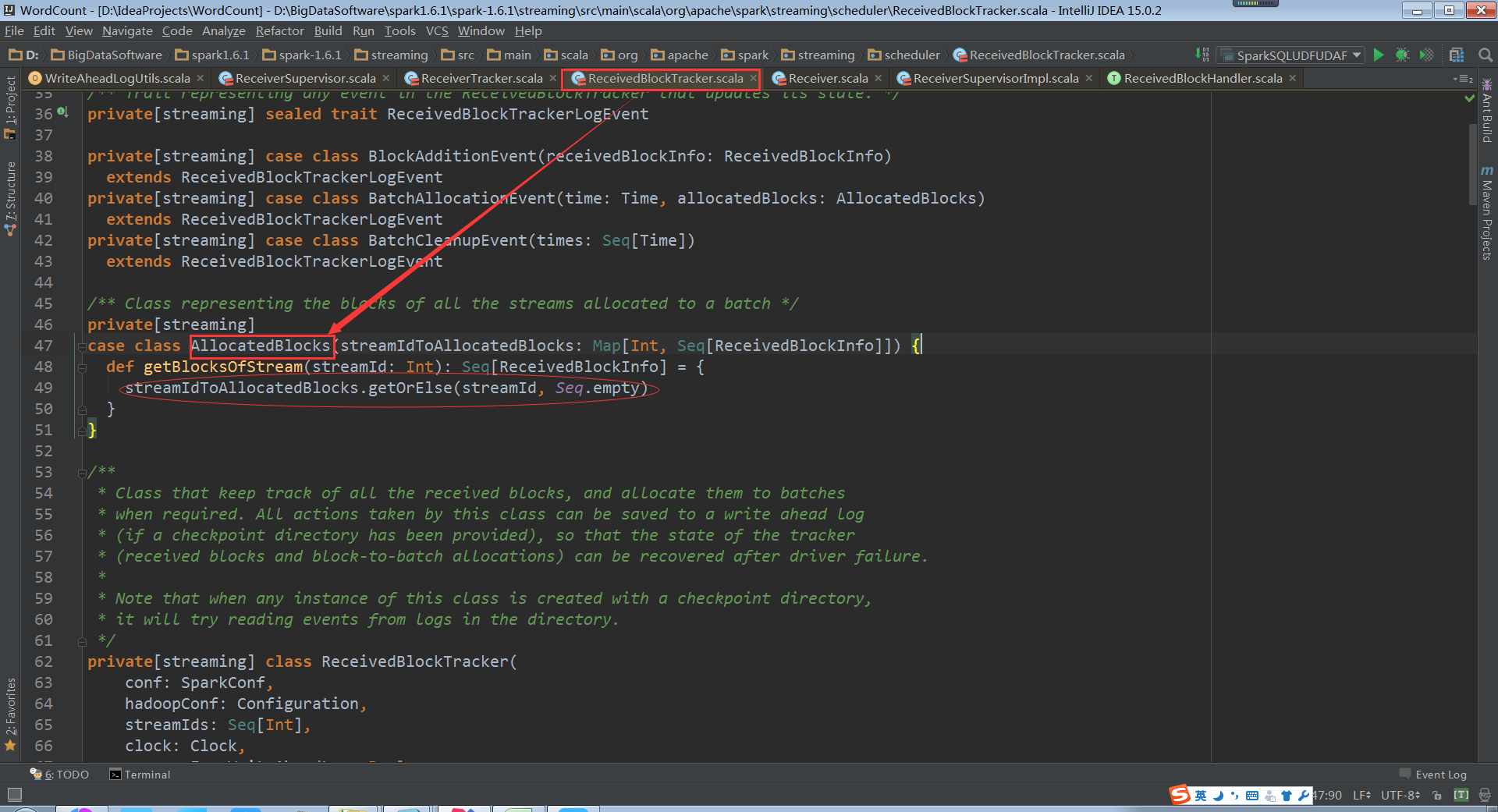
根據streamId獲取Block資訊
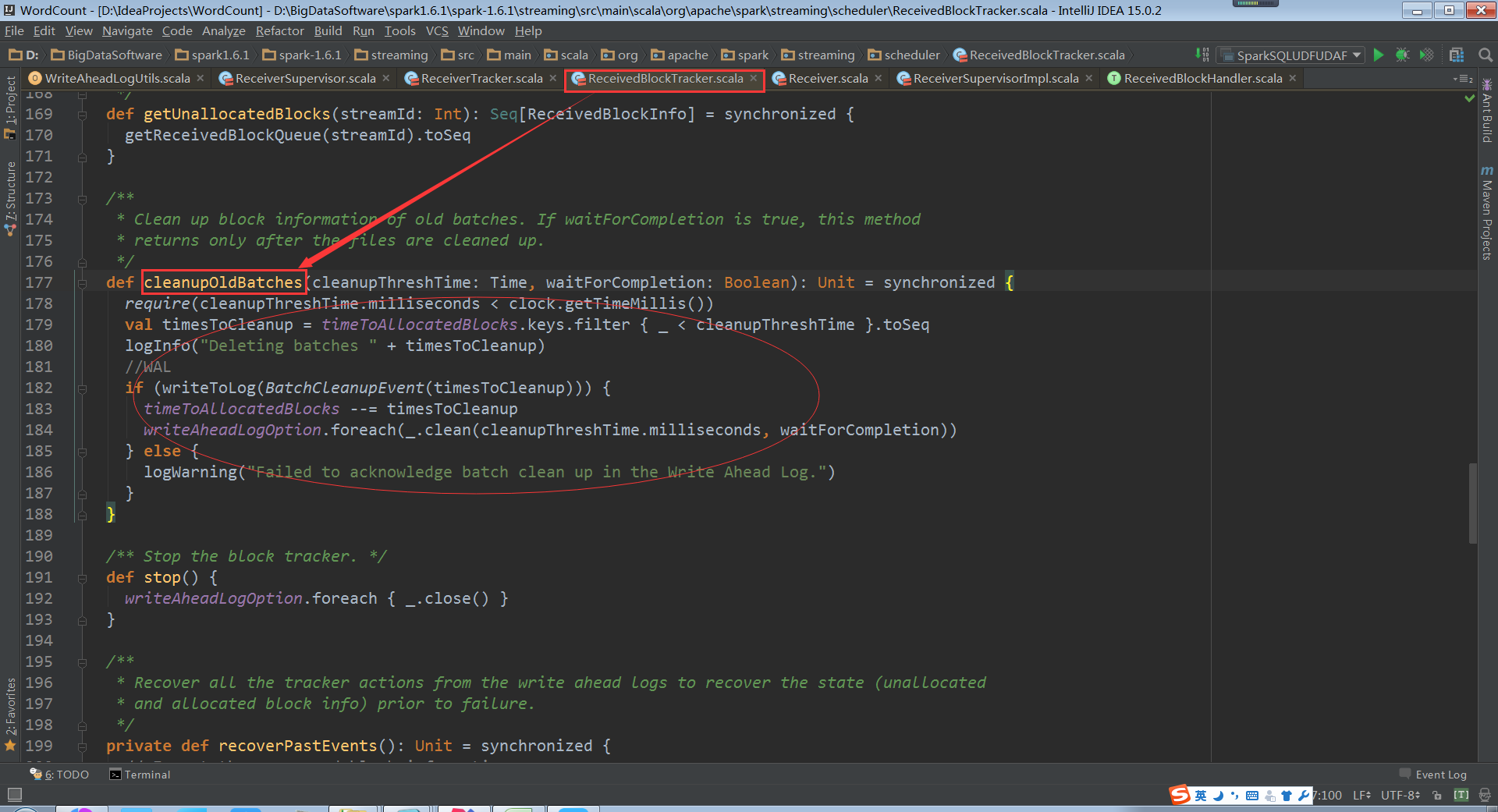
cleanupOldBatches:因為時間的推移會不斷的生成RDD,RDD會不斷的處理資料,
因此不可能一直儲存歷史資料
writeToLog原始碼
總結:
WAL對資料的管理包括資料的生成,資料的銷燬和消費。上述在操作之後都要先寫入到WAL的檔案中
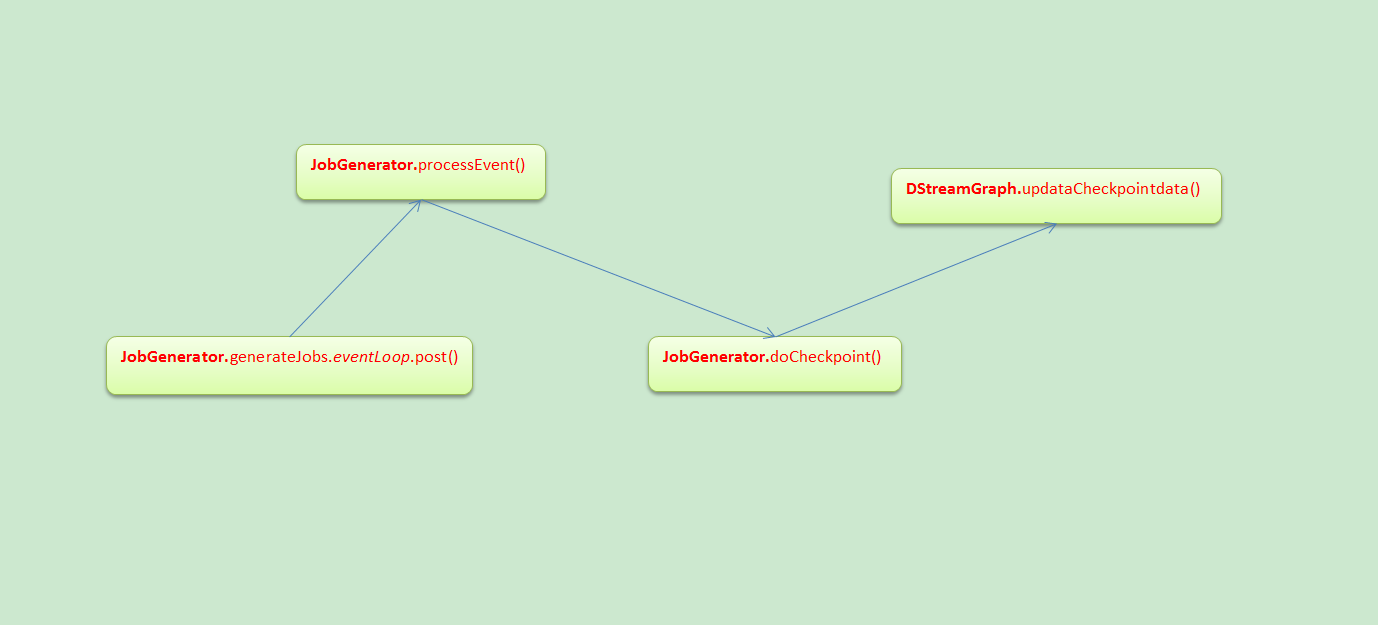
JobGenerator
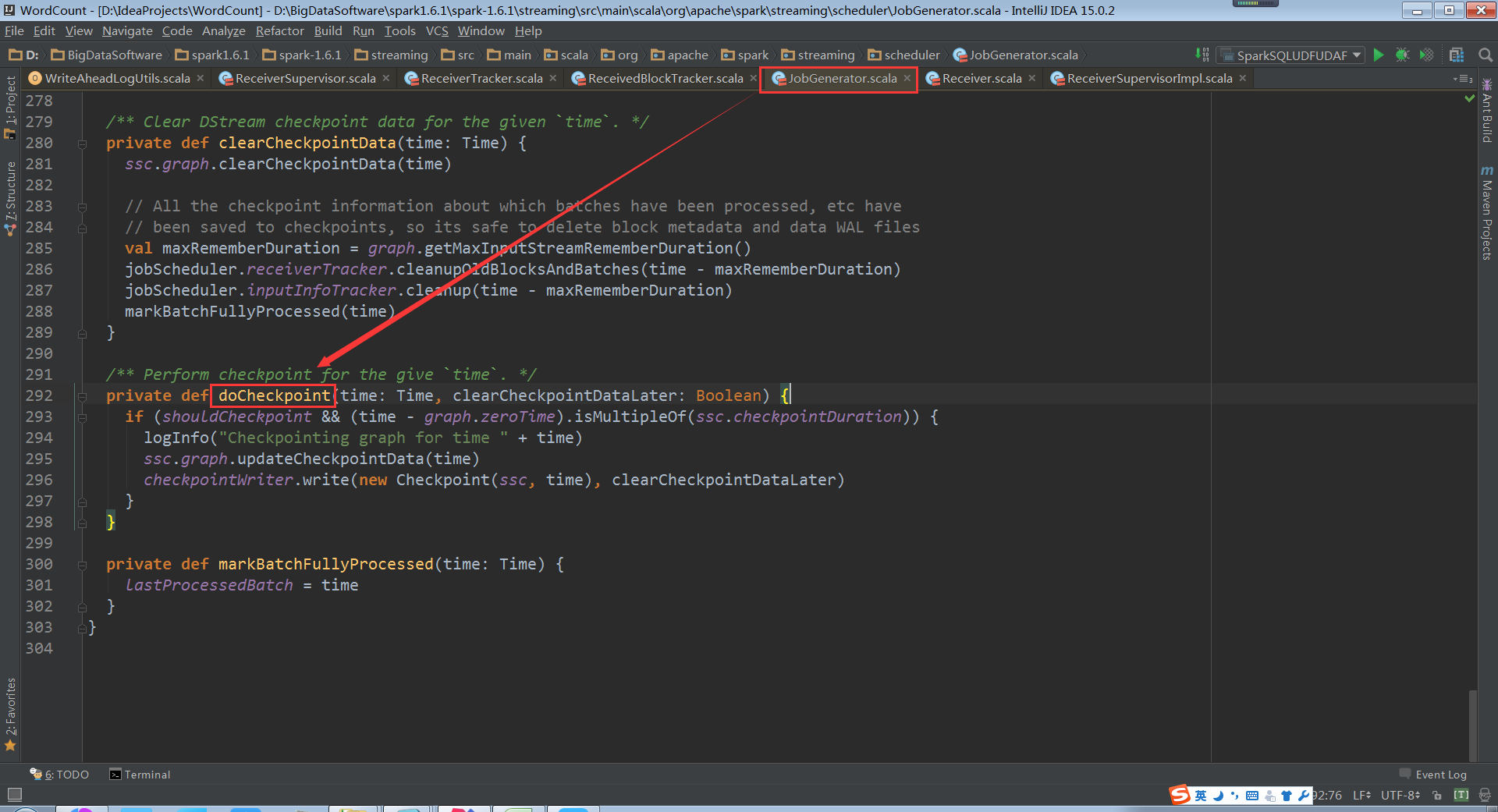
Checkpoint會有時間間隔Batch Duractions,Batch執行前和執行後都會進行checkpoint
doCheckpoint被呼叫的前後流程
generateJobs原始碼
processEvent接收到訊息
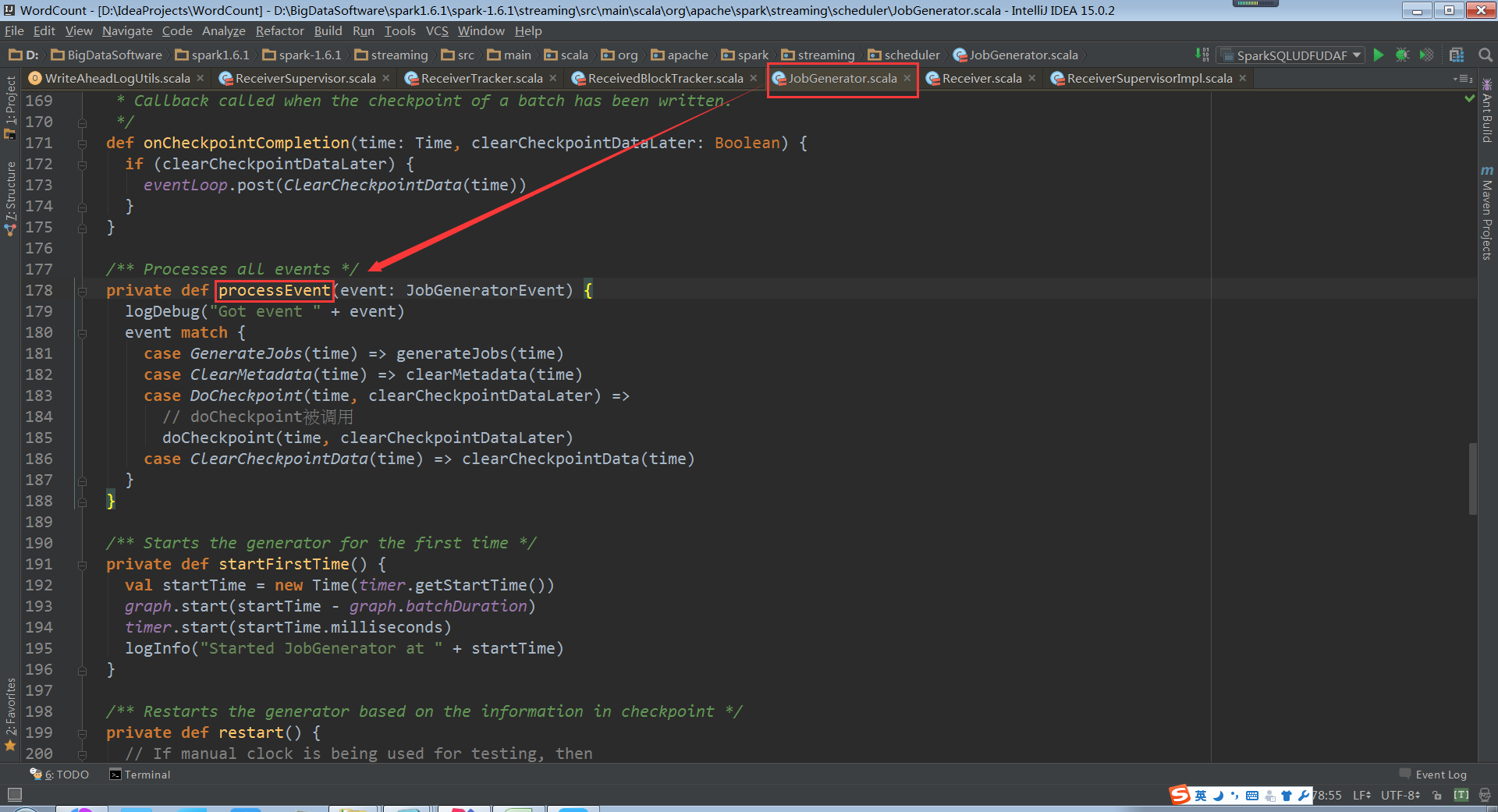
對當前的狀態進行Checkpoint
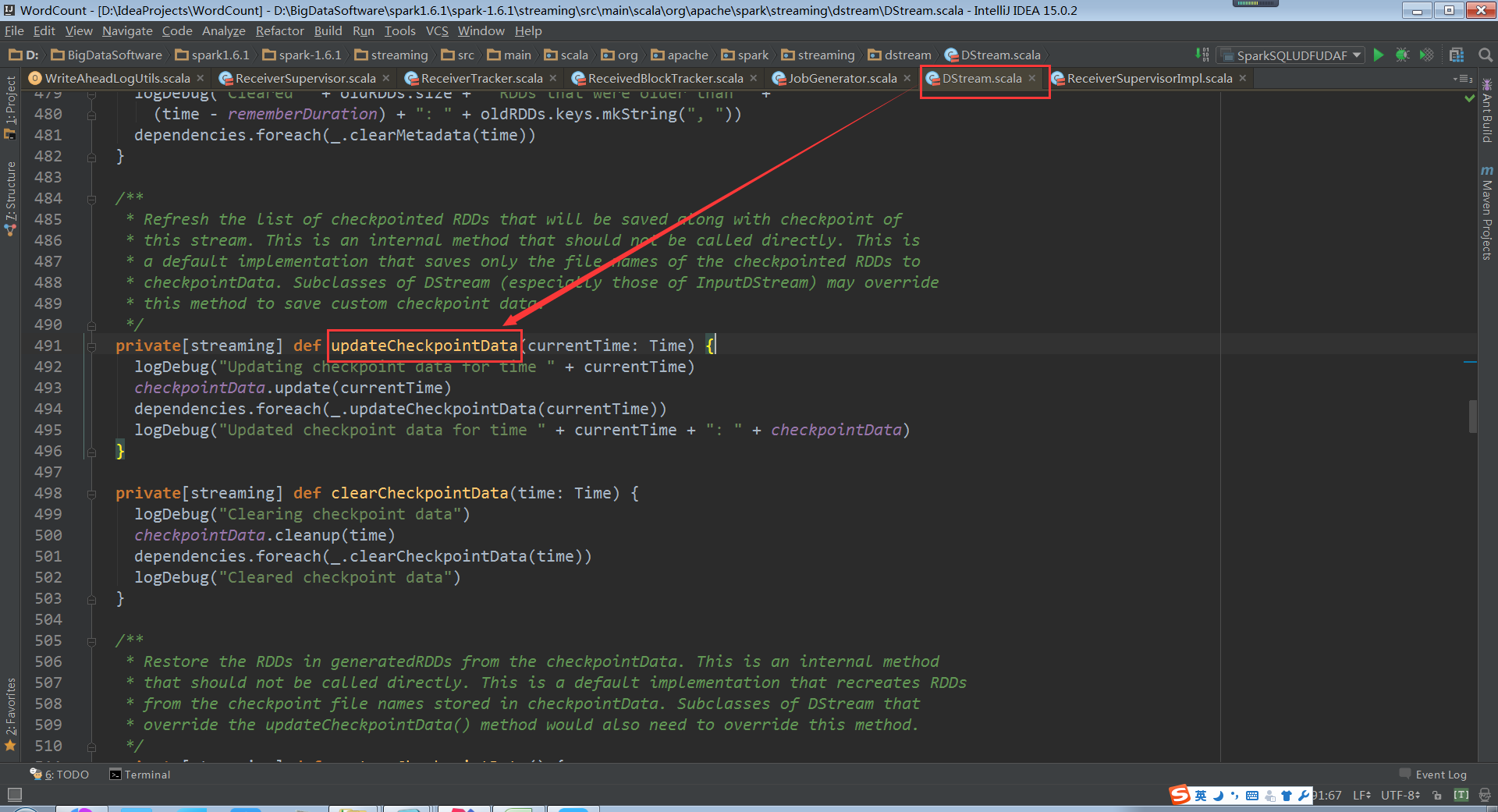
DStream中的updateCheckpointData原始碼(最終導致RDD的Checkpoint)
doCheckpoint中的shouldCheckpoint是狀態變數
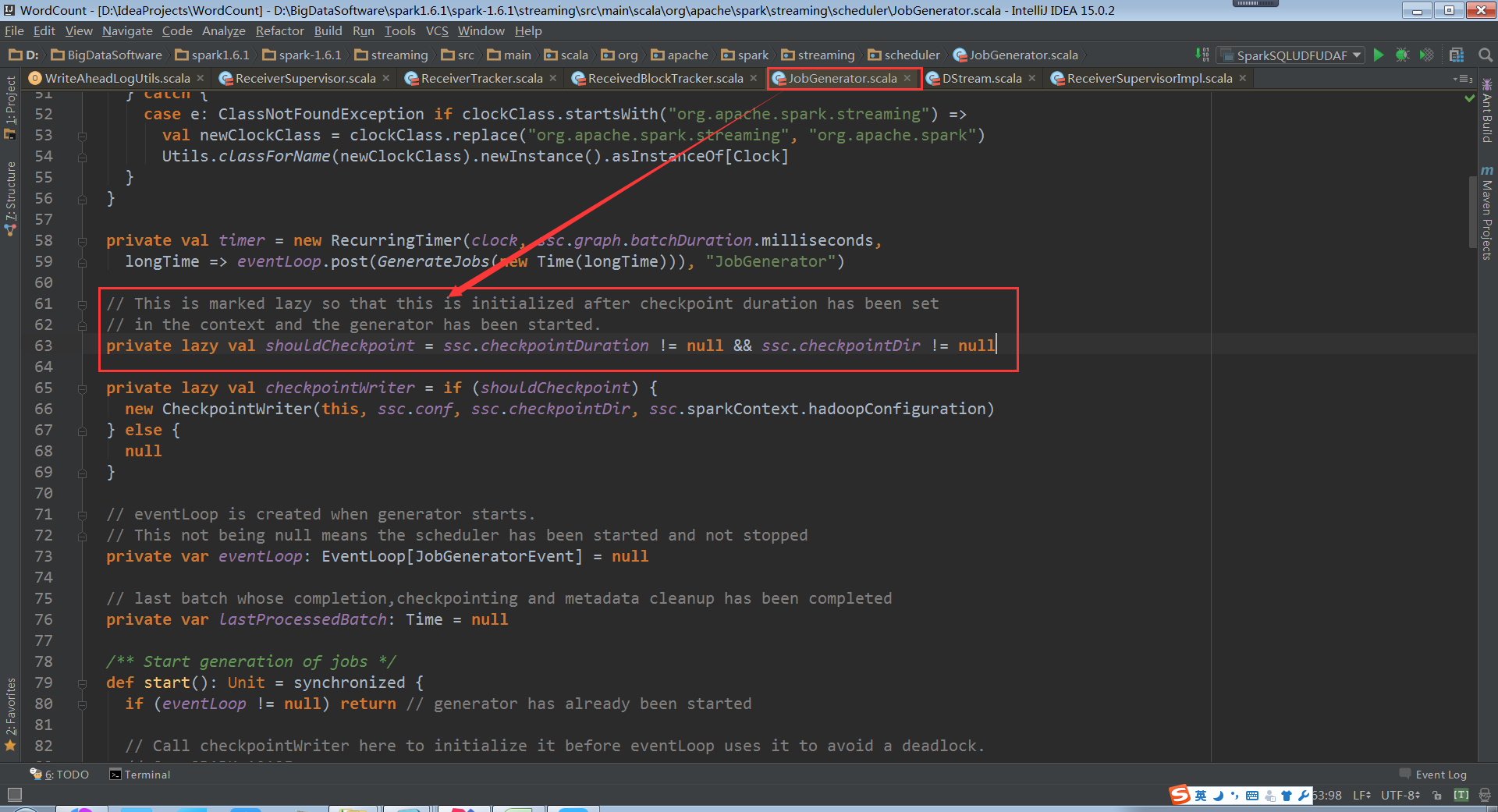
JobGenerator容錯安全性
總結
a. ReceivedBlockTracker是通過WAL方式來進行資料容錯的。
b. DStreamGraph和JobGenerator是通過checkpoint方式來進行資料容錯的。