
[轉]LSM-Tree (BigTable 的理論模型)
LSM-Tree理論模型:
來源:http://www.cnblogs.com/raymondshiquan/archive/2011/06/04/2072630.html
Google的BigTable架構在分散式結構化儲存方面大名鼎鼎,其中的MergeDump模型在讀寫之間找到了一個較好的平衡點,很好的解決了web scale資料的讀寫問題。
MergeDump的理論基礎是LSM-Tree (Log-Structured Merge-Tree), 原文見:LSM Tree
下面先說一下LSM-Tree的基本思想,再記錄下讀文章的幾點感受。
LSM思想非常樸素,就是將對資料的更改hold在記憶體中,達到指定的threadhold後將該批更改批量寫入到磁碟,在批量寫入的過程中跟已經存在的資料做rolling merge。
拿update舉個例子:
比如有1000萬行資料,現在希望update table.a set addr='new addr' where pk = '833',
如果使用B-Tree類似的結構操作,就需要:
1. 找到該條記錄所在的page,
2. load page到記憶體(如果恰好該page已經在記憶體中,則省略該步)
3. 如果該page之前被修改過,則先flush page to disk
4. 修改資料
上面的動作平均來說有兩次disk I/O,
如果採用LSM-Tree類似結構,則:
1. 將需要修改的資料直接寫入記憶體
可見這裡是沒有disk I/O的。
當然,我們要說,這樣的話讀的時候就費勁了,需要merge disk上的資料和memory中的修改資料,這顯然降低了讀的效能。
確實如此,所以作者其中有個假設,就是寫入遠大於讀取的時候,LSM是個很好的選擇。我覺得更準確的描述應該是”優化了寫,沒有顯著降低讀“,因為大部分時候我們都是要求讀最新的資料,而最新的資料很可能還在記憶體裡面,即使不在記憶體裡面,只要不是那些更新特別頻繁的資料,其I/O次數也是有限的。
所以LSM-Tree比較適合的應用場景是:insert資料量大,讀資料量和update資料量不高且讀一般針對最新資料。
文章讀下來有以下幾點感受:
1. 基本思想早就有了,作者給出了較好的表現形式。
2. Merge是page/block級別的,而不是BigTable中的檔案級別的。這一點主要原因可能是BigTable在分散式場景下做block級別很困那,而且GFS也不支援修改。
3. 其提出的比較標準比較有趣,將磁碟容量,轉速等結合起來給出一個以美元為單位的cost標準,然後跟B-Tree結構的實現做了比較,結果當然是大大勝出。但是這裡我覺得作者有些比較是不合理的,比如LSM使用log而B-Tree沒有使用,這顯然對B-Tree不公,其實B-Tree如果使用log,寫入效能應該不比LSM差,順序讀取可能差一些。
4. 在Multi components 中,提出Ci/Ci+1的比例達到20的時候是最優的,這個數字意義不大,但是其中的分析方法對於Merge策略的選擇是個啟發。
【大話LSM Tree 】
來源:http://f.dataguru.cn/thread-24939-1-1.html
任何一種排序演算法都是在一定的問題背景下提出來的。 ——XXX大學的資料結構老師
沒有完美的犯罪 ——XXX神探
平衡是系統設計的一種美 ——我是這麼想的
記憶體的高效性是lsm的結構基礎,我們在訪問資料的時候速度肯定是記憶體大於磁碟的,這樣的話為什麼不全用記憶體呢?原因大家自己考慮下就行了,所以權衡下來還是需要用硬碟的,那麼為了實現資料的快速插入和查詢,儲存應該怎麼設計呢?學過oracle的同學都應該知道,要使一個表對查詢的響應比較快,那麼最主要的手段就是索引,但是索引多了就會影響資料插入的速度,這也是一種平衡,下面我們將分析lsm,看看它是設計了個完美的解決方案嗎?
在討論這個問題之前,讓我們看下lsm tree解決了什麼問題:
答案就是減少資料頻繁的插入、修改、刪除操作所需要的磁碟I/O次數
學過資料結構的同學都知道Btree樹是很多索引的優先選擇結構,b tree樹訪問的時間複雜度接近Logm(N/2),我們可以計算下,在成百上千的索引節點下,即使索引十幾億的資料,那麼樹的深度也不會很深的,應該是10以內吧,再加上對於lru演算法的支援,可以很明顯的減少io,那為什麼hbase不用這個結構呢,答案就是本文開頭的幾句話。
因為hbase中資料插入是比較隨機的或者說是無序的,在查詢資料的時候回到索引上,也就是對於某個葉子節點的訪問是很隨機的,這個場景很重要,那麼我們根據這個具體場景分析一下b+樹,因為查詢是隨機的,那麼也就是說我們上次調入記憶體的資料可能很久以後都不會被訪問,所以lru演算法失去了它的價值,主要的系統開銷變成了訪問B+樹的io了,記憶體的命中率很低,對於插入資料來說道理是一樣的。
下面我們再看看lsm tree是怎麼做的:
lsm構造許多小的結構,每個結構在記憶體裡排序一下構成內部有序,查詢的時候對每個小結構就可以採用二分法高效的查詢定位,我們都知道有序的東西查詢起來速度肯定比無序的快,如果只是這麼設計肯定不能達到快速插入和查詢的目的,lsm還引入了Bloom filter和小樹到大樹的排序。
Bloom Filter是一種空間效率很高的隨機資料結構,它利用位陣列很簡潔地表示一個集合,並能判斷一個元素是否屬於這個集合。Bloom Filter的這種高效是有一定代價的:在判斷一個元素是否屬於某個集合時,有可能會把不屬於這個集合的元素誤認為屬於這個集合(false positive)。因此,Bloom Filter不適合那些“零錯誤”的應用場合。而在能容忍低錯誤率的應用場合下,Bloom Filter通過極少的錯誤換取了儲存空間的極大節省。
關於Bloom filter的詳細請大家自己google。
Bloom filter在lsm中的作用就是判斷要查詢的資料在哪個記憶體部件中,或者要插入的資料應該插入到哪個記憶體部件中。
小樹到大樹的排序是為了節約記憶體,做開發的同學應該都明白記憶體中寶貴,同時也是為了恢復,因為我們知道hbase的delete和update其實都是insert,這都是由lsm的特點決定的,新的資料會被寫到磁碟新的位置上去,這樣就保證了舊記錄不會被覆蓋,在系統crash後的恢復過程會很有用,只要按日誌順序恢復就ok了。
說了半天沒說什麼是lsm tree:
LSM-Tree通過使用一個基於記憶體的元件C0和一至多個基於磁碟的(C1, C2, …, CK)元件演算法,對索引變更進行延遲及批量處理,並通過歸併的方式高效的將更新遷移到磁碟。
下面我們看一下兩元件演算法的具體實現:
如下圖
當我們進行插入操作的時候,首先向日誌檔案中寫入一個用於恢復該插入的日誌記錄,然後去寫這條記錄,把這個記錄的索引放在c0樹上,一段時間之後,把這個索引節點放到c1樹上,對於資料的檢索現在c0上,然後在c1上,這是肯定會命中的,由於記憶體的限制,所以c0不能太大,這就要求一定大小時要把c0中的某些連續節點merge到c1上,如下圖

磁碟上的c1是類似於b-樹的結構,這個結構也被優化過,針對磁碟的塊屬性和訪問的順序性做了專門的優化。那麼c0樹是b-樹嗎?
相信很多人關心,當然也是貫性思維,其實不是的,因為為了能快速刪除節點(為了merge)和查詢,設計成b樹是沒有必要的,普通的avl也可以的。
多元件演算法其實和兩元件的類似,因為2-n從來就不是個問題,圖如下:

論壇中也有很多同學用了上面的這幾幅圖,說的也是很詳細的,可以仔細閱讀下,我在這裡不費口舌了。
下面討論下lsm tree的插入和刪除:
插入的時候先生成唯一值來確保索引的唯一,生成的規則很大程度上決定了查詢的規則,然後寫日誌,最後批量把資料寫入硬碟,批量有兩個含義就是延遲和合並。
刪除其實也是批量的思想,就是先寫日誌,然後標記延遲、最後合併的時候清除。
lsm tree之所以能夠做批量得意於它的日誌設計。
任何的演算法都有它適用的具體場景,或是具體的問題域,所以更多的時候我們是把各種演算法進行綜合使用,來達到我們預期的效果,也就是說組合的優勢是揚長避短,同時我們也應該各有取捨。
在寫本文的時候也看了網上很多這方面的文章,很多同學說lsm tree適用於寫入遠大於讀取的場景,我覺得這個問題是相對的,從設計角度上講,這也是一種平衡,但是從效能角度講,lsm tree結構的搜尋會比b-tree慢嗎?怎麼衡量呢?這也是個問題,所以我在文章開頭定義了高速讀寫的特性給lsm tree的原因。
【從LSM-Tree、COLA-Tree談到StackOverflow、OSQA 】
來源:http://blog.csdn.net/v_july_v/article/details/7526689
作者:July,chx/@羅勍從LSM-Tree、COLA-Tree談到StackOverflow、OSQA
出處:結構之法演算法之道blog
導讀
本文重點談了4個東西,LSM-Tree及COLA-Tree,及StackOverflow及OSQA,全文分為以下兩部分:- 第一部分從最基本的LSM-Tree的C0C1兩元件演算法,談到多元件演算法( LSM-Tree最適用於那些索引插入頻率遠大於查詢頻率的情況,比如,對於歷史記錄表和日誌檔案來說,就屬於這種情況),再稍稍提下COLA-tree,讓讀者對COLA有個印象。
- 第二部分則是講講最近我和幾個朋友利用OSQA(OSQA為仿照StackOverflow的開源系統)搭建的一個仿照StackOverflow的問答系統,分享實踐開發過程中遇到的一些問題及其解決方式,此部分主要由chx/@羅勍編寫。
第一部分、LSM-Tree、COLA-Tree
1.0、哪裡用到了LSM-Tree
最初看到LSM-Tree這個樹結構,是從友情站點NoSQLFan上一篇介紹有著高效能key-value的資料庫nessDB的文章內瞭解到的。nessDB是一個小巧、高效能、可嵌入式的key/value儲存引擎,使用標準C開發,支援Linux, *BSD, OS X and Solaris等系統,無第三方庫依賴。同時nessDB還提供一個服務端,支援Redis的 PING, SET, MSET, GET, MGET, DEL, EXISTS, INFO, SHUTDOWN命令,你可以使用任何一款Redis客戶端來連線和操作nessDB。
而整個引擎基於LSM-Tree思想開發,對隨機寫非常友好。為提高隨機讀,nessDB使用了Level LRU和Bloom Filter策略。我們知道,現在一般主流的資料庫索引一般都是用的B/B+樹系列,包括MySQL及NoSQL中的MongoDB。而這個nessDB為何例外,LSM-Tree有何特別呢?抱著對它的好奇,便研究學習了下此LSM-Tree。
甚至包括現在另一種比較火/流行的資料庫Cassandra 以及與眾多類BigTable儲存一樣,都採用的是LSM-Tree 結構來儲存資料,簡單來說就是將原來的直接維護索引樹變為增量寫的方式,這樣能夠保證對磁碟的操作是順序的。
再後來,看到了一篇論文:The Log-Structured Merge-Tree,這篇論文原英文有30多頁,看了兩個下午。下面,本文第一部分就結合這篇論文及星星的譯作,從最基本的LSM-Tree的C0C1兩元件演算法,談到多元件演算法,讓讀者對LSM-Tree這個樹結構的原理有個充分的認識與理解。
1.1、什麼是LSM-Tree
相信隨著NoSQL據庫,尤其是類BigTable系統的流行,LSM-Tree這個樹結構,大家很快就不會再如此時這般陌生了。blog內已經詳細闡述過B/B+樹,那麼這個LSM跟B樹系列相比,有什麼不同呢,它的優勢在哪,適用於何種情況?一切,請聽我慢慢道來。
此處的Log-Structured這個詞源於Ousterhout和Rosenblum在1991年發表的經典論文<<The Design and Implementation of a Log-Structured File System >>,這篇論文提出了一種新的磁碟儲存管理方式,在這種結構下,針對磁碟內容的所有更新將會被順序地寫入一個類日誌的結構中,從而加速檔案寫入和回收速度。該日誌包含了一些索引資訊以保證檔案可以快速地讀出。日誌會被劃分為多個段來進行管理。這種方式非常適合於存在大量小檔案寫入的場景。
LSM-Tree具體是一種什麼樣的樹結構呢,具體來說,LSM-Tree通過使用某種演算法(兩元件C0C1及多元件演算法),對索引變更進行延遲及批量處理,並通過一種類似於歸併排序的方式高效地將更新遷移到磁碟。
將索引節點放置到磁碟上的這一過程進行延遲處理,是最根本的,LSM-Tree結構通常就是包含了一系列延遲放置機制。LSM-Tree結構也支援其他的操作,比如刪除,更新,甚至是那些具有long latency的查詢操作。只有那些需要立即響應的查詢會具有相對昂貴的開銷。LSM-Tree的主要應用場景就是,查詢頻率遠低於插入頻率的情況(大多數人不會像開支票或存款那樣經常檢視自己的賬號活動資訊)。在這種情況下,最重要的是降低索引插入開銷;與此同時,也必須要維護一個某種形式的索引,因為順序搜尋所有記錄是不可能的。
因此,LSM-Tree最適用於那些索引插入頻率遠大於查詢頻率的情況,比如,對於歷史記錄表和日誌檔案來說,就屬於這種情況。OK,接下來,咱們就來截殺這個兩元件C0C1演算法,以及多元件演算法。
1.2、LSM-Tree之兩元件C0C1演算法
1.2.1、LSM-Tree兩元件COC1由上文,我們已經知道,LSM-Tree通過使用某種演算法(兩元件C0C1及多元件演算法),對索引變更進行延遲及批量處理,並通過一種類似於歸併排序的方式高效地將更新遷移到磁碟。更進一步,LSM-Tree由兩個或多個類樹的資料結構元件構成。我們先考慮簡單的兩個元件的情況,如下圖所示:
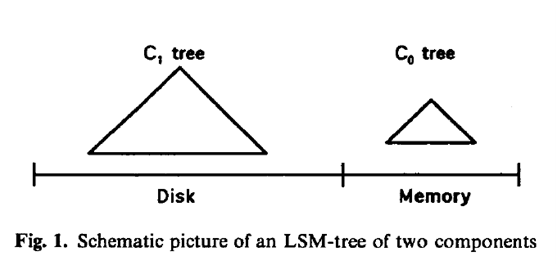
如上,便是LSM-Tree之兩元件C0C1演算法的示意圖。C1樹在左邊,存在於磁碟Disk上,C0樹在右邊,存在於記憶體Memory上。
在每條歷史記錄表中的記錄生成時,會首先向一個日誌檔案中寫入一個用於恢復該插入操作的日誌記錄。然後針對該歷史記錄表的實際索引節點會被插入到駐留在記憶體中的C0樹,之後它將會在某個時間從右到左被移到磁碟上的C1樹中。對於某條記錄的檢索,將會首先在C0中查詢,然後是C1。在記錄從C0移到C1中間肯定存在一定時間的延遲,這就要求能夠恢復那些crash之前還未被移出到磁碟的記錄。
向駐留在記憶體中的C0樹插入一個索引條目不會花費任何IO開銷。但是,用於儲存C0的記憶體的成本要遠高於磁碟,這就限制了它的大小。這就需要一種有效的方式來將記錄遷移到駐留在更低成本的儲存裝置上的C1樹中。為了實現這個目的,在當C0樹因插入操作而達到接近某個上限的閾值大小時,就會啟動一個rolling merge過程,來將某些連續的記錄段從C0樹中刪除,並merge到磁碟上的C1樹中。如下圖所示:
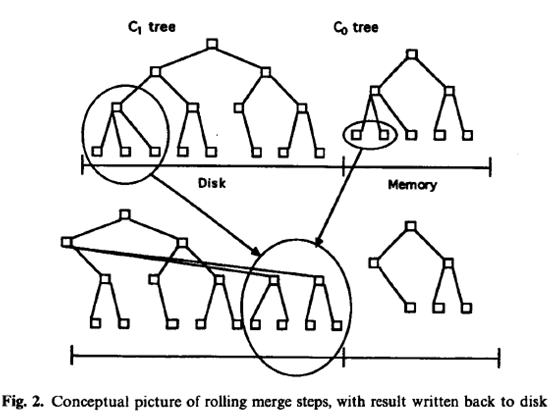
如上,Rolling merge實際上由一系列的merge步驟組成。首先會讀取一個包含了C1樹中葉節點的multi-page block,這將會使C1中的一系列記錄進入快取。之後,每次merge將會直接從快取中以磁碟頁的大小讀取C1的葉節點,將那些來自於葉節點的記錄與從C0樹中拿到的葉節點級的記錄進行merge,這樣就減少了C0的大小,同時在C1樹中建立了一個新的merge好的葉節點。
磁碟上的C1樹具有一個類似於B-樹的目錄結構,但是它是為順序性的磁碟訪問優化過的,所有的節點都是100%滿的,同時為了有效利用磁碟,在根節點之下的所有的單頁面節點都會被打包(pack)放到連續的多頁面磁碟塊(multi-page block)上;類似的優化也被用在SB-樹中。對於rolling merge和長的區間檢索的情況將會使用multi-page block io,而在匹配性的查詢中會使用單頁面節點以最小化快取需求。對於root之外的節點使用256Kbytes的multi-page block大小(root節點根據定義通常都只是單個的頁面)。
1.2.2、LSM-Tree之記憶體上C0樹的選擇
LSM-tree從誕生那一刻開始的整個變化過程如下,我們首先從針對C0的第一次插入開始。與C1樹不同,C0樹不一定要具有一個類B-樹的結構。首先,它的節點可以具有任意大小:沒有必要讓它與磁碟頁面大小保持一致,因為C0樹永不會位於磁碟上(位於哪?記憶體上阿),因此我們就沒有必要為了最小化樹的深度而犧牲CPU的效率(如果看下B-樹,就可以知道實際上它為了降低樹的高度,犧牲了CPU效率。所以,在當整個資料結構都是在記憶體中時(別忽略了這個前提),一棵普通的2-3樹(2-3-4樹和B樹的前身)或AVL樹足矣,且不必使用B樹查詢,因為B樹更適合外存查詢(當然,在B樹查詢資料時,把資料從磁碟匯入到記憶體後,由於B樹表的結構是有序的,可以直接二分查詢)。
說的細一點,則是記憶體不用B樹系列,外存則用B樹系列。你知道,IO操作是影響整個B樹查詢效率的決定因素,更多細節請參看此文第3小節:從B 樹、B+ 樹、B* 樹談到R 樹。
這樣,一個2-3樹或者是AVL樹就可以作為C0樹使用的一個數據結構。當C0首次增長到它的閾值大小時,最左邊的一系列記錄將會從C0中刪除(這應是以批量處理的模式完成,而不是一次一條記錄),然後被重新組織成C1中的一個100%滿(滿的意思就是節點允許最多多少個子節點便有多少個子節點)的葉子節點。後續的葉節點會按照從左到右的順序放到快取中的一個multi-page block的初始頁面中,直到該block填滿為止;之後,該block會被寫到磁碟中,成為C1樹的磁碟上的葉級儲存的第一部分。隨著後續的葉節點的加入,C1樹會創建出一個目錄節點結構。具體細節請參看原論文:The Log-Structured Merge-Tree。
讀者朋友@豬婆的豬公反饋:B樹的確存在你上述所說的問題,尤其是批量插入的資料大量分散在不同葉結點時。但如果系統中有通用的快取機制,那一個葉結點頁面在插入一條資料後不必立即寫出,只有緩衝區已滿需要替換時才需要寫出,此時可能已有多條資料插入到同一葉結點頁面。當然,B樹最適用的操作是等值查詢和範圍查詢,維護操作代價的確是高了。
1.3、LSM-Tree之多元件演算法
當在LSM-tree index上執行一個需要理解響應的精確匹配查詢或者range查詢時,首先會到C0中查詢所需的那個或那些值,然後是C1中。這意味著與B-樹相比,會有一些額外的CPU開銷,因為現在需要去兩個目錄中搜索。對於那些具有超過兩個元件的LSM-tree來說,還會有IO上的開銷。具體做法是,我們將一個具有元件C0,C1,C2…Ck-1和Ck的多元件LSM-tree,索引樹的大小伴隨著下標的增加而增大,其中只有C0是駐留在記憶體中的,其他則是在磁碟上。
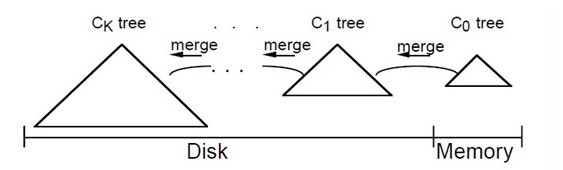
在所有的元件對(Ci-1,Ci)之間都有一個非同步的rolling merge過程負責在較小的元件Ci-1超過閾值大小時,將它的記錄移到Ci中。一般來說,為了保證LSM-tree中的所有記錄都會被檢查到,對於一個精確匹配查詢和range查詢來說,需要訪問所有的Ci元件。當然,也存在很多優化方法,可以使搜尋限制在這些元件的一個子集上。
所以,LSM-Tree之多元件演算法便是:我們將一個具有元件C0,C1,C2…Ck-1和Ck的多元件LSM-tree,索引樹的大小伴隨著下標的增加而增大,其中C0是駐留在記憶體中的,其他則是在磁碟上。在所有的元件對(Ci-1,Ci)之間都有一個非同步的rolling merge過程負責在較小的元件Ci-1超過閾值大小時,將它的記錄移到Ci中。
1.3.1、LSM-Tree之插入與刪除
LSM-Tree之插入首先,如果生成邏輯可以保證索引值是唯一的,比如使用時間戳來進行標識時,如果一個匹配查詢已經在一個早期的Ci元件中找到時那麼它就可以宣告完成了。再比如,如果查詢條件裡使用了最近時間戳,那麼我們可以讓那些查詢到的值不要向最大的元件中移動。當merge遊標掃描(Ci,Ci+1)對時,我們可以讓那些最近某個時間段(比如τi秒)內的值依然保留在Ci中,只把那些老記錄移入到Ci+1。
在那些最常訪問的值都是最近插入的值的情況下,很多查詢只需要訪問C0就可以完成,這樣C0實際上就承擔了一個記憶體緩衝區的功能。比如,用於短期事務UNDO日誌的索引訪問模式,在中斷事件發生時,通常都是針對相對近期的資料的訪問,這樣大部分的索引就都會是仍處在記憶體中。通過記錄每個事務的啟動時間,就可以保證所有最近的τ0秒內發生的事務的所有日誌都可以在C0中找到,而不需要訪問磁碟元件。
LSM-Tree之刪除需要指出的是刪除操作可以像插入操作那樣享受到延遲和批量處理帶來的好處。當某個被索引的行被刪除時,如果該記錄在C0樹中對應的位置上不存在,那麼可以將一個刪除標記記錄(delete node entry)放到該位置,該標記記錄也是通過相同的key值進行索引,同時指出將要被刪除的記錄的Row ID(RID)。實際的刪除可以在後面的rolling merge過程中碰到實際的那個索引entry時執行:也就是說delete node entry會在merge過程中移到更大的元件中,同時當碰到相關聯的那個entry,就將其清除。與此同時,查詢請求也必須在通過該刪除標記時進行過濾,以避免返回一個已經被刪除的記錄。
該過濾很容易進行,因為刪除標記就是位於它所標識的那個entry所應在的位置上,同時在很多情況下,這種過濾還起到了減少判定記錄是否被刪除所需的開銷(比如對於一個實際不存在的記錄的查詢,如果沒有該刪除標記,需要搜尋到最大的那個Ci元件為止,但是如果存在一個刪除標記,那麼在碰到該標記後就可以停止了)。對於任何應用來說,那些會導致索引值發生變化(比如一條記錄包含了ID和name,同時是以ID進行索引的,那麼如果是name更新了,很容易,只需要對該記錄進行一個原地改動即可,但是如果是ID該了,那麼該記錄在索引中的位置就要調整了,因此是很棘手的)的更新都是不平凡的,但是這樣的更新卻可以被LSM-tree一招化解,通過將該更新操作看做是一個刪除操作+一個插入操作。
1.3.2、LSM-Tree多元件演算法的開銷
通過上文,我們已經瞭解到:一個具有K+1個元件的LSM-tree具有元件C0,C1,C2…,Ck-1和Ck,元件大小依次遞增;C0元件是基於記憶體的,其他都是基於磁碟的(對於那些經常訪問的頁面來說會被快取在記憶體中)。在所有的元件對(Ci-1,Ci)之間都存在一個非同步的rolling merge過程,它負責在Ci-1超過閾值大小時,將記錄從較小的元件中移入到較大的元件中。當一個生命期很長的記錄被插入到LSM-tree之後,它首先會進入C0樹,然後通過這一系列的K個非同步rolling merge過程,最終將被移出到Ck。還是引用上圖,如下:
這裡我們主要關注插入效能,因為我們假設LSM-tree通常使用在插入為主的場景中。對於三元件或者多元件LSM-tree來說,查詢操作效能上會有降低,通常一個磁碟元件將會帶來一次額外的頁面IO。
通常情況下,可以通過最小化LSM-tree的總開銷(用於C0的記憶體開銷加上用於C1的磁碟空間/IO能力開銷)來確定C0的大小。為了達到這種最小化的開銷,我們通常從一個比較大的C0元件開始,同時讓C1元件大小接近於所需空間的大小。在C0元件足夠大的情況下,對於C1的IO壓力就會很小。現在,我們可以開始試著通過減少C0的大小,來在昂貴的記憶體和廉價磁碟之間進行權衡,直到減低到當前C1所能提供的IO能力完全被利用為止。此時,如果再降低C0的記憶體開銷,將會導致磁碟儲存開銷的增加,因為需要擴充C1元件以應對磁碟負載的增加,最終將會達到一個最小開銷點。
現在,對於兩元件LSM-tree來說,這個典型的C0元件大小從記憶體使用的角度上看開銷仍是比較高的。一個改進的方案是,採用一個三元件或者多元件LSM-tree。簡單來說,如果C0太大以至於記憶體開銷成為主要因素,那麼我們可以考慮在兩元件LSM-tree的C0和C1之間加入一箇中間大小的基於磁碟的元件,這就允許我們在降低了C0大小的同時還能夠限制住磁碟磁臂的開銷。
我們知道,對於B樹來說,每條記錄的插入通常需要對該記錄所屬的節點進行兩次IO(一次讀出一次寫入),與此相比,可以向每個葉子中一次插入多條記錄就是一個優勢。插入的葉子節點在從B樹中讀入後之後短暫地在記憶體中停留,在它被再一次使用時它已不在記憶體了。因此對於B樹索引來說就沒有一種批量處理的優勢:每個葉節點被讀入記憶體,然後插入一條記錄,然後寫出去。
但是在一個LSM-tree中,只要與C1元件相比C0元件足夠大,總是會有一個批量處理效果。比如,對於16位元組的索引記錄大小來說,在一個4Kbytes的節點中將會有250條記錄。如果C0元件的大小是C1的1/25,那麼在每個具有250條記錄的C1節點的Node IO中,將會有10條是新記錄(也就是說在此次merge產生個node中有10條是在C0中的,而C0中的記錄則是使用者之前插入的,這相當於將使用者的插入先暫存到C0中,然後延遲到merge時寫入磁碟,這樣這一次的Node IO實際上消化了使用者之前的10次插入,的確是將插入批量化了)。很明顯,由於這兩個因素,與B-樹相比LSM-tree效率更高,而rolling merge過程則是其中的關鍵。
1.4、CacheObliviousBTree
本文開頭的導讀部分已經說過,目前比較出名的效率優於B+tree的有兩大類:一個類是本文第一部分將要介紹的LSM-Tree,另一個是COLA,搞tokudb的那一幫人。這個快取忘卻CacheOblivious演算法在演算法導論第18章B樹的最後的本章註記中也已提到:為了如何讓B樹更有效的執行,他們提出了一個快取忘卻CacheOblivious演算法,該演算法在不需要明確知道儲存器層次中資料傳輸規模的情況下,也可以高效的工作。更多請參見:http://en.wikipedia.org/wiki/Cache-oblivious_algorithm。
COLA便是CacheObliviousBTree作為一個無處不B-樹的替代品,COLA的創造者們實現了一個cache-oblivious的動態搜尋樹。他們用二叉樹的“van Emde Boas”的佈局,其葉節點指向“packed memory structure”中的時間間隔。這棵cacheObliviousBTree支援高效的查詢,以及高效的批次插入和刪除。
B-樹的有效實施,需要對快取記憶體行的大小和頁面大小和一個特定的記憶體層次結構進行了優化。相比之下,cacheObliviousBTree包含不依賴於機器的變數,以及執行上的任何記憶體層次結構,並要求最少的使用者級別的記憶體管理。cacheObliviousBTree隨機插入資料/資料結構,效能優於B-樹的Berkeley DB,且能良好的執行一系列操作。
這個資料結構的另一個優點是,儲存器陣列保持在排列順序的資料,允許在高速行駛時連續讀取、插入、和寫入、刪除一些資料。此外,此資料結構也很容易實現,因為它使用的是記憶體對映,而不是儲存在磁碟上的資料是單級儲存。 我們也可以把CacheObliviousBTree的鍵設計得很長(想象一個關鍵,如DNA序列,這比記憶體更大),從而支援快速批量插入。
第一部分,完。
除了近幾天一直在看上面這個LSM-Tree/CacheObliviousBTree之外,這個月組織幾個朋友一直在開發StackOverflow/OSQA,以使我的群友們/讀者們有一個好的交流之地。OK,接下來,進入本文第二部分。
第二部分、OSQA開發日誌
2.1、中國的StackOverflow
在我的三五杆槍,可幹革命,三五個人,可以創業的文章內,我便已提到:“ 如今國外有一個專門面向程式設計師的問答社群已經風靡全世界,它就是stackoverflow:http://stackoverflow.com/。借鑑於此,近期內我們會先做一個中國的stackoverflow(4月份開始),與國內外雜而多不同,我們的stack專注一個方向,專注一個領域的問答。” 4月6日,我和幾個朋友便開始正式啟動了。這個東西,有幾點用處,一者它能發揮群體智慧集體程式設計的優勢,二者把它獻給我的的群友們及讀者們,讓他們有一個交流之地,而不再是在QQ群裡彼此阻隔無法溝通,不再只是我發文章他們評論,而是群友們/讀者們彼此之間直接相互溝通交流,三者,國內目前沒有一個好的專注於程式設計師問答的技術社群。 分為兩條線,並行(全部工作利用業餘時間完成):- 一條是銀河系至始至終用java自己開發,
- 第二條線則是選擇在開源框架OSQA上直接搭建,修改完善。
ok,以下為我們團隊成員中的chx@羅勍用OSQA搭建成功後,寫的開發日誌,我們遇到的問題很多(包括還遺留著很多的問題亟待解決),特此把這些問題及其解決方式分享出來(日後會分享第一條線銀河系的開發日誌),以作梳理+總結+備忘。
2.2、第二條線之OSQA搭建
chx/@羅勍
搭建過程基本沒什麼,直接按照wiki:http://wiki.osqa.net/display/docs/Home,根據自己的系統來選擇安裝。我用的ubuntu+python2.6+django1.3(1.4能用,但是需要改很多地方)安裝過程可以參考wiki,解釋得已經很詳細。過程中出現no module之類的都easy_install就可以了。
Osqa下載之後要配幾個地方
settings_local.py.dist重新命名成settings_local.py
settings_local.py需要修改的地方:
- [plain] view plaincopyprint?
- DATABASES = {
- 'default': {
- 'ENGINE': 'django.db.backends.mysql',
- 'NAME': 'osqa',
- 'USER': 'root',
- 'PASSWORD': 'root',
- 'HOST': '127.0.0.1',
- 'PORT': '3306',
- }
- 根據自己的設定填寫
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'osqa', 'USER': 'root', 'PASSWORD': 'root', 'HOST': '127.0.0.1', 'PORT': '3306', } }#根據自己的設定填寫 - APP_URL = 'http://127.0.0.1:8000'
- LANGUAGE_CODE = 'cn'#漢化得已經很不錯了
- DJANGO_VERSION = 1.3#填寫自己的django版本
- DISABLED_MODULES = ['mysqlfulltext','books', 'recaptcha', 'project_badges']#trunk的預設用的是mysql全文索引,需要把這個加到diabledmodule!
- 如果用spinx做全文搜尋的話,追加[plain] view plaincopyprint?
- SPHINX_API_VERSION = 0x116 #refer to djangosphinx documentation
- SPHINX_SEARCH_INDICES=('search_question_index',) #a tuple of index names remember about a #comma after the
- SPHINX_SERVER='localhost'
- SPHINX_PORT=9312
- 並且在settings.py
- INSTALLED_APPS = [
- 'django.contrib.auth',
- 'django.contrib.contenttypes',
- 'django.contrib.sessions',
- 'django.contrib.sites',
- 'django.contrib.admin',
- 'django.contrib.humanize',
- 'django.contrib.sitemaps',
- 'django.contrib.markup',
- 'forum',
- 'djangosphinx',
- ]
SPHINX_API_VERSION = 0x116 #refer to djangosphinx documentation SPHINX_SEARCH_INDICES=('search_question_index',) #a tuple of index names remember about a #comma after the SPHINX_SERVER='localhost' SPHINX_PORT=9312 並且在settings.py INSTALLED_APPS = [ 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.sites', 'django.contrib.admin', 'django.contrib.humanize', 'django.contrib.sitemaps', 'django.contrib.markup', 'forum', 'djangosphinx', ]
當然,要用sphinx就easy_install django-sphinx和sphinxsearch。到此,基本配置都已完成,不管用apache還是簡單的manage.py runserver的方式都可以啟動,看到介面了。配置郵件可以參考:http://support.google.com/mail/bin/answer.py?hl=en&answer=13287
接下來,注意到新增感興趣標籤的時候,輸入標籤名點選新增就可以看到剛才的標籤已經在上面了,可是重新整理之後發現不見了。於是檢視程式碼之後發現這句:
froum\views\commands.py line 536
try:
t = Tag.objects.get(name=tag)
mt = MarkedTag(user=request.user, reason=reason, tag=t)
mt.save()
except :
pass
就是說,如果該標籤不存在在資料庫,不是已有的標籤,就會靜靜地pass,而前端還能顯示能加到。
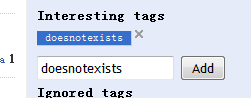
官網也是這個樣子……….這樣的方式不太友好,在沒有該標籤的時候應該給使用者一個友好提示…
2.3、Coreseek實現OSQA的搜尋
2.3.1、Mysql全文索引不堪重用
第二個問題,搜尋問題顯示沒有match的。即使輸入的是某個標題的關鍵字也搜不到,最後幾天便一直卡在這個問題上。
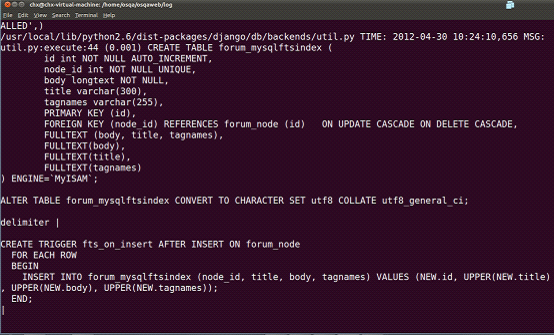
Google了N多,試了又試,無意間在settings.py所在的目錄看到有個log資料夾。裡面有個django.osqa.log檔案 Tail -f django.osqa.log,在頁面發一個搜尋請求,看到了它其實用的是mysql的全文索引。如果表裡沒有資料,則搜尋不到問題。
後來終於在/home/osqa/osqaweb/log目錄下的django.osqa.log檔案中看到這句,這個表forum_mysqlftsindex就是用mysql做全文索引建的表,建個trigger在每次人問問題和回答問題,都會觸發這個觸發器,並且重新將該問題相關的全部內容都重新更新到索引表:
接下來試試搜尋問題 也能看到這樣:
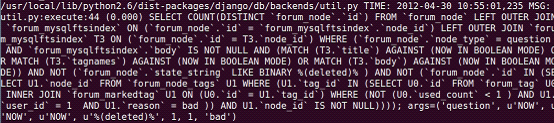
所以,很明顯,預設的用的是mysqlfulltext,搜尋的時候也走的這條線。在這之前,試圖很多次開啟sphinxfulltext模組的時候,settings等地方需要都改了,需要配的都配了,但是始終在sphinx的服務端沒有看到任何請求過來,coreseek雖然是第一次使用,但是對sphinx已經用了很久,所以能肯定sphinx的server端肯定是沒有問題的。在看到上面的log之後就確定是預設走的是mysql的全文索引,於是在disabledmodule裡將mysqlfulltext加上。就試了試搜尋,就看到如下的結果:

應該走的是django的模糊匹配,我的keyword是 ask,它就到forum_node這個問題表中用like ‘%ask%’這樣的模糊匹配去取資料,當然,直接去這裡找當然能找到了,頁面也能顯示相應的問題了,但是like畢竟不是長久之計,本身也對MySQL資料庫產生巨大的壓力,也就是說,表forum_mysqlftsindex就是用mysql做全文索引建的表,那麼現在咱們得廢掉這個MySQL本身提供的全文索引,尋找一種更為有效的全文索引方式或解決方案。
2.3.2、基於sphinx之上的Coreseek實現搜尋
下面就考慮給osqa的搜尋用sphinx實現。因為包含中文搜尋,雖然sphinx可以通過設定編碼和有效字符集支援中文,但是中文分詞搞不定,就用coreseek來實現,coreseek整合了分詞+搜尋。
coreseek官網穩定版是3.2.14,是基於sphinx0.9.9的。
$ /usr/local/mmseg3/bin/mmseg -d /usr/local/mmseg3/etc src/t1.txt
中文/x 分/x 詞/x 測試/x
中國人/x 上海市/x
Word Splite took: 1 ms
- 第二部分是csft,看到如下所示表示已經安裝成功
$ /usr/local/coreseek/bin/indexer -c /usr/local/coreseek/etc/sphinx-min.conf.dist
##以下為正常測試時的提示資訊:
Coreseek Fulltext 3.2 [ Sphinx 0.9.9-release (r2117)]
Copyright (c) 2007-2010,
Beijing Choice Software Technologies Inc (http://www.corese