
【Lucene01】索引的建立&Luke的配置使用
在Lucene對文字進行處理的過程中,可以大致分為三大部分:
1、索引檔案:提取文件內容並分析,生成索引
2、搜尋內容:搜尋索引內容,根據搜尋關鍵字得出搜尋結果
3、分析內容:對搜尋詞彙進行分析,生成Quey物件。
索引檔案
基本步驟如下:
1、建立索引庫IndexWriter
2、根據檔案建立文件Document
3、向索引庫中寫入文件內容
package org.algorithm;
import java.io.File;
import java.io.IOException;
import org.apache Luke檢視Lucene索引:
1、Luke的使用
下載Luke,這裡下載的是lukeall-4.0.0.jar
使用方法:
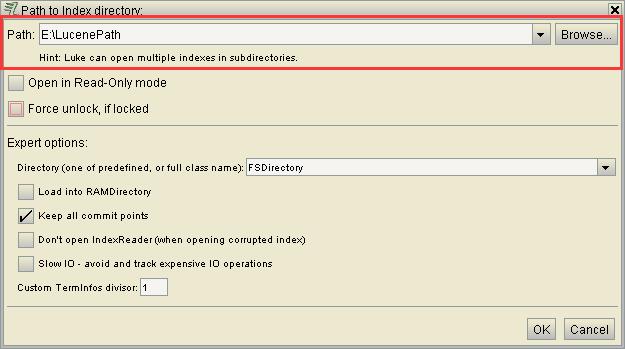
下載完luke後直接放在某個碟符下然後可以在cmd視窗找到luke工具所在的碟符根路徑下,使用 java -jar luke.jar 就可以啟動了,有的luke工具直接雙擊執行就可以啟動,使用時候兩種方式都可以試一下,啟動之後,點選Browser按鈕,找到你的索引路徑點OK,即可顯示你索引的內容。
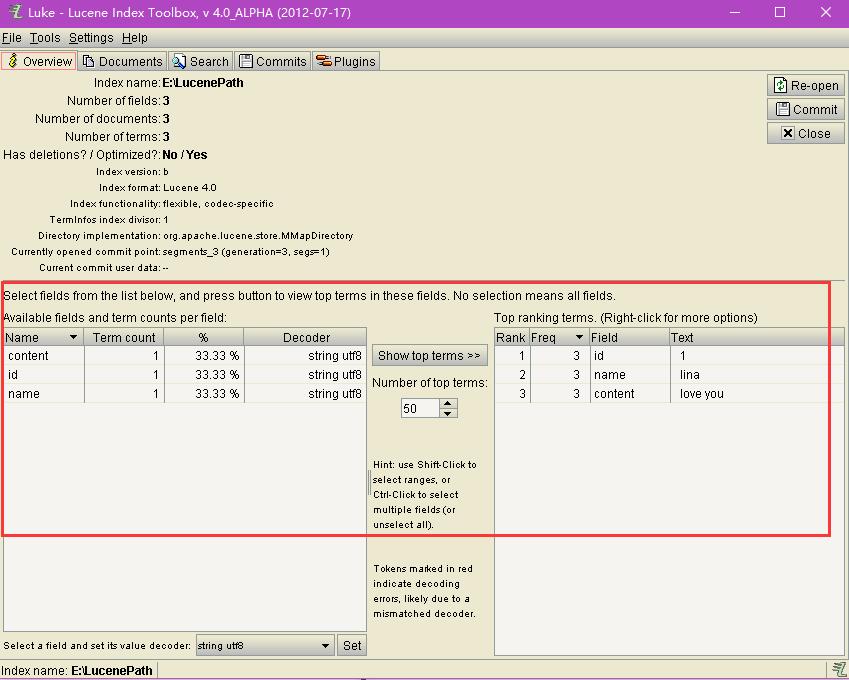
overview介面是用來進行索引的一般性檢視和操作的,比如索引目錄,域資訊,版本,term資訊,Rank排名等資訊。注意,索引檔案裡Analyze卻不Store的欄位資訊還是不可見的,也就是隻能看STORE了的內容。
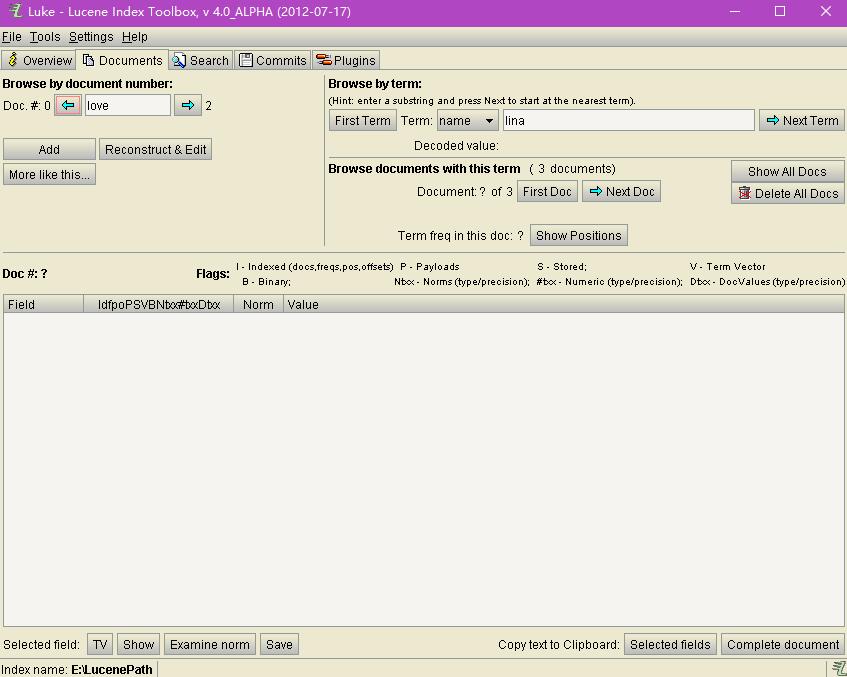
documents介面是用來進行文件的操作和檢視的,能根據文件編號和詞進行查詢,其實這個就是搜尋功能。
search介面是可以進行索引的搜尋測試,可以編寫lucene搜尋語句,看到語句解析後的query樹,還可以選擇進行搜尋的分詞器、預設欄位和重複搜尋次數,然後下面的listview中就會列出一個搜尋的的文件的所有儲存的(store)欄位的值,可以看到查詢花費的時間。
file介面,故名思義,這個就是用來檢視每個索引相關檔案的一些屬性的介面,具體的話,可以通過這個介面分析下索引檔案的多少,是否需要優化或者合併等等
plugins介面,就是可以看到luke提供的各種外掛。比較有用的還是分詞工具,提供一個分詞的類,然後下面文字框輸入一段文字,然後就可以讓這個工具幫你分詞,你可以看到詳細的分詞資訊,對自定義分詞器的除錯或者測試。還有一個hadoop外掛,支援從hadoop節點中獲取節點中檔案的相關資訊,對分散式搜尋引擎搭建有用,算是支援多平臺的lucene索引檔案塊的檢視。
最後,還可以將lukeall-4.0.0.jar匯入到ecplise中,檢視原始碼進行分析其功能特點。