資料分析與AI(五)pandas的資料拼接操作/美國各州人口分析/蘋果歷年股票曲線圖
阿新 • • 發佈:2019-01-25
pandas的拼接操作
pandas的拼接分為兩種:
- 級聯: pd.concat, pd.append
- 合併: pd.merge, pd.join
0. 回顧numpy的級聯
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as pltnd = np.random.randint(0,150,size=(5,4))
nd
# 結果如下:
array([[ 54, 65, 70, 31],
[ 5, 85 # 列級聯
np.concatenate([nd,nd], axis=1)
# 結果如下:
array([[ 54, 65, 70, 31, 54, 65, 70, 31],
[ 5, 85, 36, 137, 5, 85, 36, 137],
[ 87, 38, 63, 77, 87, 38, 63, 77],
[ 89 為方便講解,我們首先定義一個生成DataFrame的函式:
def make_df(cols, index):
data = {col:[str(col)+str(ind) for ind in index] for col in cols}
df = DataFrame(data= data, columns = cols, index = index)
return dfdf1 = make_df(['a' 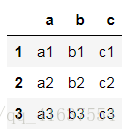
df2 = make_df(['a','b','c'],[4,5,6])
df2
# 結果如下: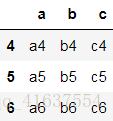
1. 使用pd.concat()級聯
pandas使用pd.concat函式,與np.concatenate函式類似,只是多了一些引數:
pandas使用pd.concat函式,與np.concatenate函式類似,只是多了一些引數:
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)1) 簡單級聯
和np.concatenate一樣,優先增加行數(預設axis=0)
# np.concatenate(axis=1)的情況是水平級聯, np中沒有index, 和columns 所以只要行列相等就可以級聯
# 在pd中, 如果行 和 列 不一致, 但是shape(形狀)相同, 會級聯成一個更大的df, 但是不對應的值會填充NaN
pd.concat([df1, df2], axis=1)
# 結果如下: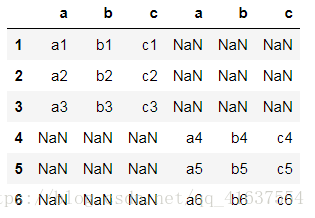
可以通過設定axis來改變級聯方向
pd.concat([df1, df2], axis=0)
# 結果如下:
注意index在級聯時可以重複
df3 = make_df(['a','b','c'],[2,3,4])
df3
# 結果如下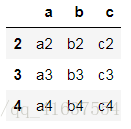
pd.concat([df1,df3],axis=1)
# 水平合併以後結果如下: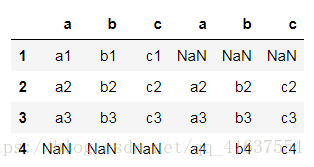
也可以選擇忽略ignore_index,重新索引
# git中有 .gitignore 這個檔案, 會把寫入的檔案路徑給遮蔽, 不會被上傳到github
# add . commit push
# ignore_index 作用是對索引重新排序
pd.concat([df1,df3],axis=0, ignore_index=True)
# 在工作中, 大部分的分析資料來源於mysql,mysql中的id都是唯一的, 分表
# mysql在面試中是最重要的,分表 每個表最大的儲存限制是100w條, 一般只會使用80W條是最優的
或者使用多層索引 keys
concat([x,y],keys=[‘x’,’y’])
df4 = pd.concat([df1,df3],keys=['期中','期末'])
df4
# 結果如下:
2) 不匹配級聯
不匹配指的是級聯的維度的索引不一致。例如縱向級聯時列索引不一致,橫向級聯時行索引不一致
有3種連線方式:
- 外連線:補NaN(預設模式)
df1
# 結果如下: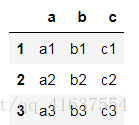
df5 = make_df(['c','d','e'],[3,4,5])
df5
# 結果如下: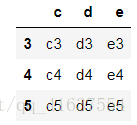
# concat預設使用的外連線
df6 = pd.concat([df1,df5],axis=0)
df6
# 結果如下: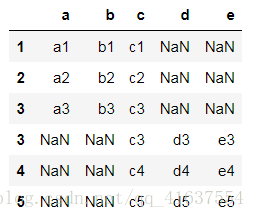
- 內連線:只連線匹配的項
# 回憶mysql中, outer和inner的不同
# 外連線 left 以左邊的表中的資料為核心, 右邊資料不匹配,則填充Null
# 內連線 join 兩邊表資料不完全對應的話, 會只顯示能對應上的資料
# join 預設值是outer
df6 = pd.concat([df1,df5],axis=1, join='inner')
df6
# 同mysql一致
- 連線指定軸 join_axes
df1
# 結果如下: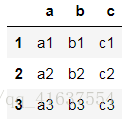
df5
# 結果如下: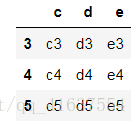
df7 = pd.concat([df1, df5], join_axes=[df1.columns])
df7
# join_axes 的值 是一個列表[df1.index]
# select df1.a, df1.b , df1.c from df1 left join df5 using(c);
# using(c) 相當於: on df1.c=df5.c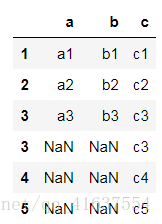
3) 使用append()函式新增
由於在後面級聯的使用非常普遍,因此有一個函式append專門用於在後面新增
append 和 concat相似
df1
# 結果如下: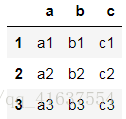
df2
# 結果如下: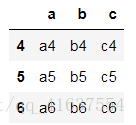
# 垂直
df1.append(df2)
2. 使用pd.merge()合併
merge與concat的區別在於,merge需要依據某一共同的行或列來進行合併
使用pd.merge()合併時,會自動根據兩者相同column名稱的那一列,作為key來進行合併。
注意每一列元素的順序不要求一致
1) 一對一合併
df1
# 結果如下: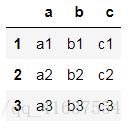
df2
# 結果如下: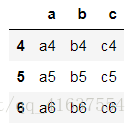
# 預設是內連線, 表的兩邊資料都不對應
pd.merge(df1,df2)
# 結果如下
display(df1,df5)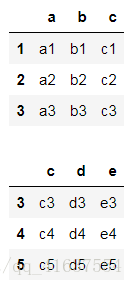
how的取值 : {‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘inner’
pd.merge(df1,df5, how='right')
# 結果如下:
pd.merge(df1,df5,how='left')
# 結果如下:
2) 多對一|一對多合併
df1
# 結果如下: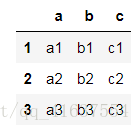
df8 = make_df(['c','d','e'],[1,1,1,4])
df8
# 結果如下: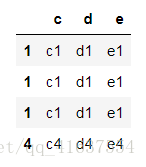
pd.merge(df1,df8)
# select * from df1 join df8 on df1.c= df8.c
pd.merge(df1,df8, how='left')
# 結果如下: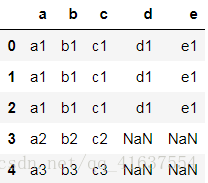
pd.merge(df1,df8,how='outer')
# 在工作中用outer , 可以自動分配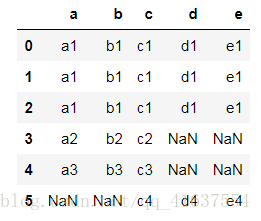
pd.merge(df1,df8,how='right')
# 結果如下:
3) 多對多合併
df8
# 結果如下:
df8.iloc[0]['d'] = 'qwe'
df8['e'][4] = 'asd'
df9 = make_df(list('abd'),[1,1,4,4])
df9
# 結果如下;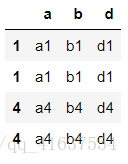
pd.merge(df9, df8)
# 結果如下:
pd.merge(df9, df8,how='outer')
# 結果如下:
4) key的規範化
- 使用on=顯式指定哪一列為key,當有多個key相同時使用
df1
# 結果如下: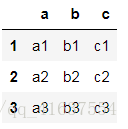
# on的作用是將兩個表中相同資料型別, 含義一致的欄位進行連線的
pd.merge(df1,df10, left_on='c',right_on='w')
# mysql
# select * 
df11 = make_df(list('bcd'),[1,2,3])
df11
# 結果如下: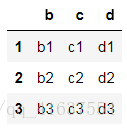
pd.merge(df1,df11,on='b')
# mysql中一般碰到兩個欄位相同, 但是代表的含義不一樣, 或者資料型別不同
# a.u = b.u a.o - b.o
# select a.o a_o, b.o b_o
6) 列衝突的解決
當列衝突時,即有多個列名稱相同時,需要使用on=來指定哪一個列作為key,配合suffixes指定衝突列名
可以使用suffixes=自己指定字尾
pd.merge(df1,df11,on='c',suffixes=('_up','_down'))
# 結果如下:
U.S.A人口分析
United States America
import pandas as pd
from pandas import DataFrame, Series# 先匯入資料檔案
# 各州的面積
areas = pd.read_csv('../data/state-areas.csv')
# 縮寫
abbr = pd.read_csv('../data/state-abbrevs.csv')
# 人口
pop = pd.read_csv('../data/state-population.csv')
areas.head()
pop.head()
# 結果如下:
# 開始合併
abbrToPop = pd.merge(abbr,pop, left_on='abbreviation', right_on='state/region', how='outer')
abbrToPop.head()
# 合併結果如下:
# 將重複的列刪除掉
# .drop()
# 一般的一執行完就列印的, 這種形式的方法不對原資料產生影響, inplace代表是否對原陣列產生影響
abbrToPop.drop(columns='abbreviation', inplace=True) # 或者abbrToPop.drop(labels='abbreviation', axis=1)
# 空資料一般會顯示NaN
abbrToPop.isnull().any()
# 結果如下:
state True
state/region False
ages False
year False
population True
dtype: bool # 其中返回True的欄位中存在NAN空資料, 需要進行處理# 怎麼計算丟失資料的數量
# state population
abbrToPop['state'].isnull().sum()
# 結果如下: 96# 把空資料填充上, 得到NAN行的篩選條件
cond = abbrToPop['state'].isnull()
# state是州名, 如何填充
# unique()去除重複的值
abbrToPop['state/region'][cond].unique()
# 結果如下:array(['PR', 'USA'], dtype=object)# 我們通過翻閱資料查到了PR的全稱
# Puerto Rico
# 開始賦值
cond_pr = abbrToPop['state/region'] == 'PR'
abbrToPop['state'][cond_pr] = 'Puerto Rico'
cond_usa = abbrToPop['state/region'] == 'USA'
abbrToPop['state'][cond_usa] = 'United States'
abbrToPop.isnull().any()
# 結果如下:
state False
state/region False
ages False
year False
population True
dtype: bool # 成功將state資料修復abbrToPop.dropna(inplace=True)
# population 查閱資料, 我們先刪除掉
abbrToPop.isnull().sum()
# 結果:
state 0
state/region 0
ages 0
year 0
population 0
dtype: int64# 還有一個表需要合併
areas.head()
# 結果如下
# 融合面積
abbrToPopToAreas = pd.merge(abbrToPop,areas, on='state',how='outer' )
abbrToPopToAreas.head()
abbrToPopToAreas.isnull().sum()
# 結果如下:
state 0
state/region 0
ages 0
year 0
population 0
area (sq. mi) 48
dtype: int64 # area欄位有48個空值cond_area = abbrToPopToAreas['area (sq. mi)'].isnull()
total_area = areas['area (sq. mi)'].sum()
total_area # 結果是: 3790399
# U.S.A
cond_ab = abbrToPopToAreas['state/region'] == 'USA'
abbrToPopToAreas['area (sq. mi)'][cond_ab] = total_area
abbrToPopToAreas.isnull().sum()
# 資料處理完畢後結果:
state 0
state/region 0
ages 0
year 0
population 0
area (sq. mi) 0
dtype: int64# 現在的表已經完全融合完成了
# 現在可以進行分析了找出2010年全民人口資料, df.query()
abbrToPopToAreas_2010 = abbrToPopToAreas.query('year == 2010 & ages == "total"')
abbrToPopToAreas_2010.head()
# 結果如下:
以state作為列索引
# 工作中會使用id作為列的索引
# set_index()
abbrToPopToAreas_2010.set_index('state', inplace=True)
abbrToPopToAreas_2010.head()
計算人口的密度, population / area (sq. mi)
density_2010 = abbrToPopToAreas_2010['population'] / abbrToPopToAreas_2010['area (sq. mi)']
density_2010
# 結果如下:state
Alabama 91.287603
Alaska 1.087509
Arizona 56.214497
Arkansas 54.948667
California 228.051342
Colorado 48.493718
Connecticut 645.600649
Delaware 460.445752
District of Columbia 8898.897059
Florida 286.597129
Georgia 163.409902
Hawaii 124.746707
Idaho 18.794338
Illinois 221.687472
Indiana 178.197831
Iowa 54.202751
Kansas 34.745266
Kentucky 107.586994
Louisiana 87.676099
Maine 37.509990
Montana 6.736171
Nebraska 23.654153
Nevada 24.448796
New Hampshire 140.799273
New Jersey 1009.253268
New Mexico 16.982737
New York 356.094135
North Carolina 177.617157
North Dakota 9.537565
Ohio 257.549634
Oklahoma 53.778278
Oregon 39.001565
Maryland 466.445797
Massachusetts 621.815538
Michigan 102.015794
Minnesota 61.078373
Mississippi 61.321530
Missouri 86.015622
Pennsylvania 275.966651
Rhode Island 681.339159
South Carolina 144.854594
South Dakota 10.583512
Tennessee 150.825298
Texas 93.987655
Utah 32.677188
Vermont 65.085075
Virginia 187.622273
Washington 94.557817
West Virginia 76.519582
Wisconsin 86.851900
Wyoming 5.768079
Puerto Rico 1058.665149
United States 81.607845
dtype: float64
2010年的人口密度融合到表中
abbrToPopToAreas_2010['density_2010'] = density_2010
abbrToPopToAreas_2010.head()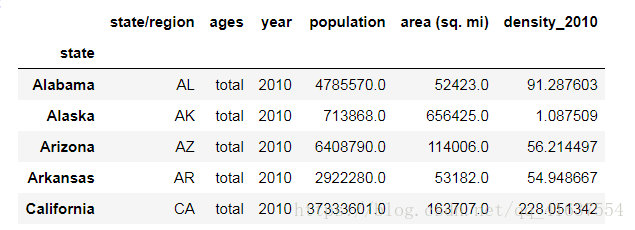
排序,找出人口密度最高的五個州¶
# sort_values 根據值來進行排序
abbrToPopToAreas_2010.sort_values(by='density_2010').tail()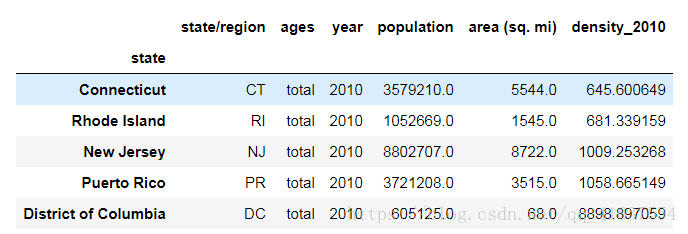
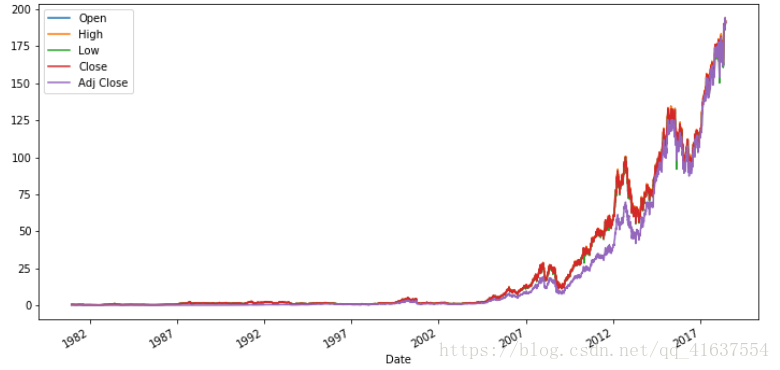
蘋果股票漲跌圖繪製
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
import numpy as npapple = pd.read_csv('../data/AAPL.csv')
apple.head()
# 結果如下: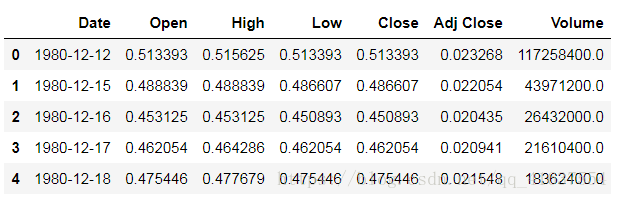
apple.dtypes
# 結果如下:
Date object
Open float64
High float64
Low float64
Close float64
Adj Close float64
Volume float64
dtype: object # 在這裡可以看見Date是object型別的轉換一下data的資料型別
mysql 中有datetime pd .to_datetime()
apple['Date'] = pd.to_datetime(apple['Date'])
apple.dtypes
# 結果如下:
Date datetime64[ns]
Open float64
High float64
Low float64
Close float64
Adj Close float64
Volume float64
dtype: object # Date的資料型別轉換為datetime64apple.set_index('Date', inplace=True)
# 結果如下: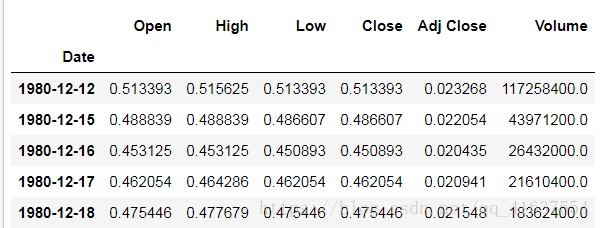
繪製圖形
adj_plot = apple['Adj Close'].plot()
fig = adj_plot.get_figure()
# set_size_inches 設定圖片的大小, 單位是英寸
fig.set_size_inches(12,6)
# 結果如下: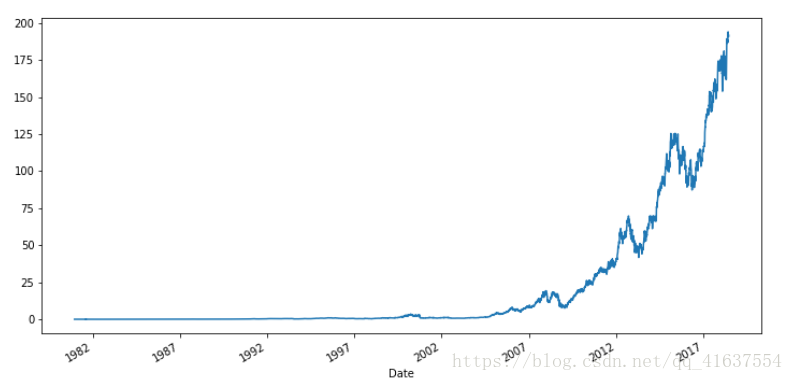
# 因為Volume這一列資料量級太大,不適合分析,故刪除
apple.drop('Volume', axis=1, inplace=True)
app = apple.plot()
fig1 = app.get_figure()
fig1.set_size_inches(12,6)