hive視窗函式必備寶典
Hive中提供了越來越多的分析函式,用於完成負責的統計分析。我們先在一一列舉,希望能夠加深印象,希望大家積極討論,如有不足,請大家多多指教。。。。
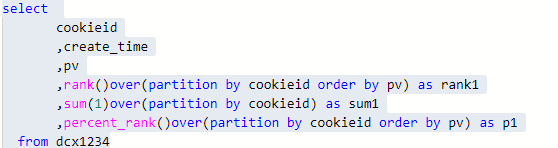
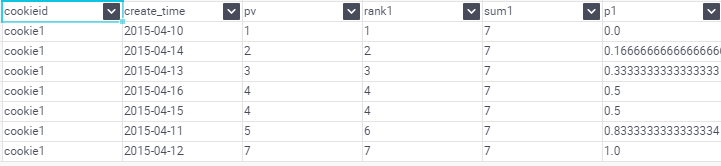
1.Row_Number,Rank,Dense_Rank 這三個視窗函式的使用場景非常多
row_number():從1開始,按照順序,生成分組內記錄的序列,row_number()的值不會存在重複,當排序的值相同時,按照表中記錄的順序進行排列;通常用於獲取分組內排序第一的記錄;獲取一個session中的第一條refer等。
rank():生成資料項在分組中的排名,排名相等會在名次中留下空位。
dense_rank():生成資料項在分組中的排名,排名相等會在名次中不會留下空位。
示例:資料準備
select * from dcx1234;



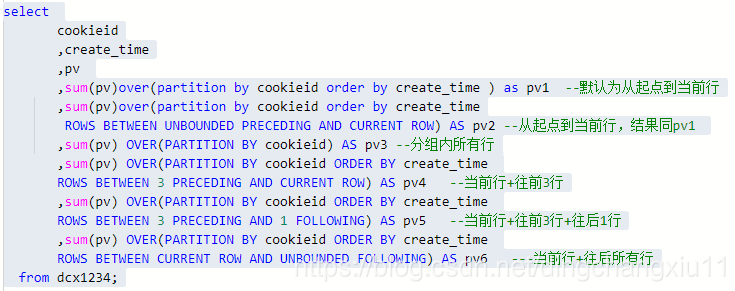
2.SUM、AVG、MIN、MAX
首先理解下什麼是WINDOW子句
PRECEDING:往前
FOLLOWING:往後
CURRENT ROW:當前行
UNBOUNDED:起點,UNBOUNDED PRECEDING 表示從前面的起點, UNBOUNDED FOLLOWING:表示到後面的終點

3.NTILE
NTILE(n) 用於將分組資料按照順序切分成n片,返回當前切片值,如果切片不均勻,預設增加第一個切片的分佈。NTILE不支援ROWS BETWEEN
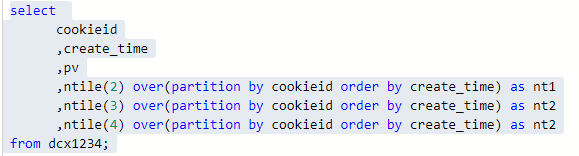
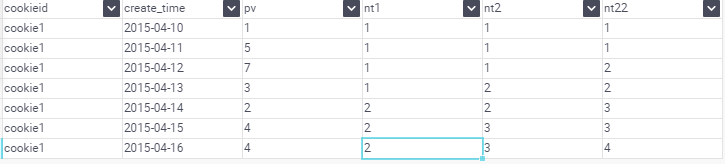
使用場景:
1.如一年中,統計出工資前1/5之的人員的名單,使用NTILE分析函式,把所有工資分為5份,為1的哪一份就是我們想要的結果.
2.sale前20%或者50%的使用者ID
4.LEAD,LAG,FIRST_VALUE,LAST_VALUE
lag與lead函式可以返回上下行的資料
LEAD(col,n,DEFAULT) 用於統計視窗內往下第n行值
第一個引數為列名,第二個引數為往下第n行(可選,預設為1),第三個引數為預設值(當往下第n行為NULL時候,取預設值,如不指定,則為NULL)

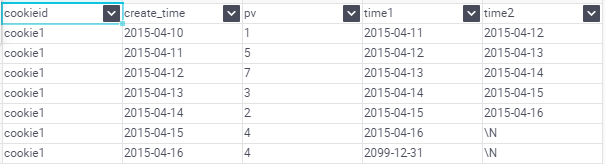
使用場景:通常用於統計某使用者在某個網頁上的停留時間
LAG(col,n,DEFAULT) 用於統計視窗內往上第n行值
第一個引數為列名,第二個引數為往上第n行(可選,預設為1),第三個引數為預設值(當往上第n行為NULL時候,取預設值,如不指定,則為NULL)

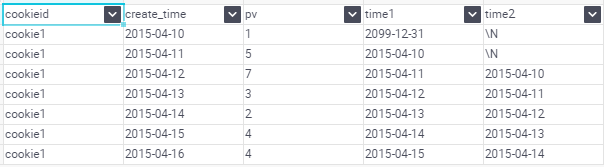
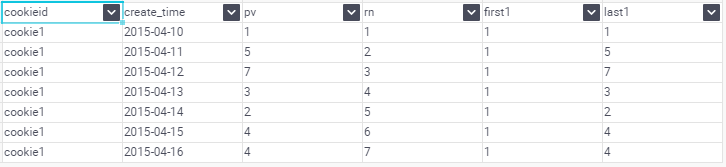
FIRST_VALUE:取分組內排序後,截止到當前行,第一個值
LAST_VALUE:取分組內排序後,截止到當前行,最後一個值
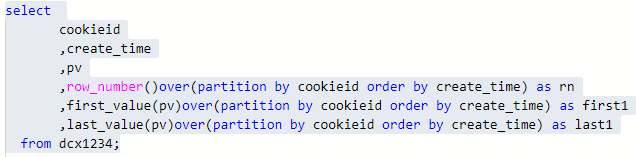
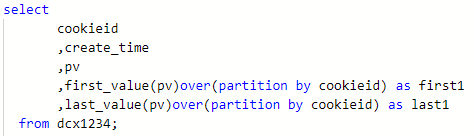
如果不指定ORDER BY,則預設按照記錄在檔案中的偏移量進行排序,會出現錯誤的結果
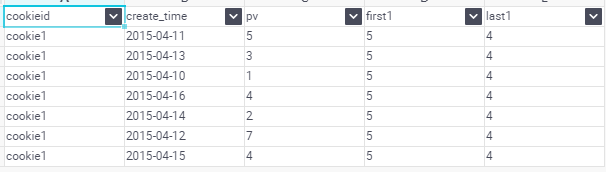
如果想要取分組內排序後最後一個值,則需要變通一下:
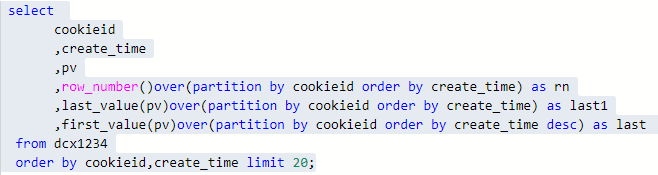
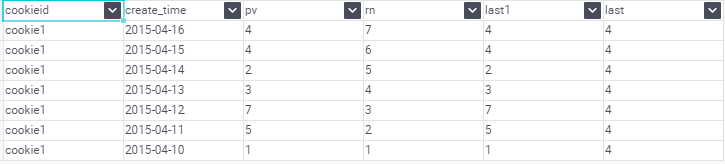
提示:在使用分析函式的過程中,要特別注意ORDER BY子句,用的不恰當,統計出的結果就不是你所期望的
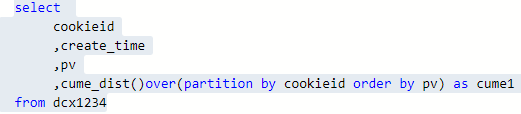
5.CUME_DIST,PERCENT_RANK
這兩個序列分析函式不是很常用,這裡也介紹下,他不支援window子句
–CUME_DIST 小於等於當前值的行數/分組內總行數
–比如,統計小於等於當前薪水的人數,所佔總人數的比例
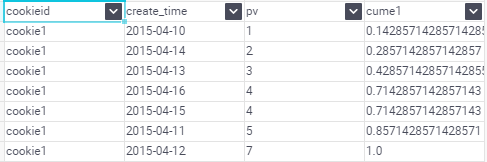
PERCENT_RANK 分組內當前行的RANK值-1/分組內總行數-1