
Dynamic risk management checklists for software
Dynamic risk management checklists for software
Imagine you’re a seasoned pilot, in just one of the thousand of flights you make per year, in an airplane you know like the palm of your hand.
You’re speeding through the runway about to take flight… but something is wrong — The airplane is not taking off… You have seconds to make a diagnostic and a decision… But it’s too late…
That’s what happened with SpainAir flight 5022, with 154 casualties, which attempted a take off with retracted flaps — a mechanism that provides extra lift for airplanes during the low speeds of takeoff and landing. A basic pilot error.
One checklist skipped item = 154 lives lost
Most people tend to immediately point at these situations as lack of experience. Yet this was a seasoned pilot in a familiar airplane. Here, experience and overconfidence might actually be the cause of the problem.
Because the plane had made a maintenance return to gate, passengers and crew had already spent hours on the runway. On the second take off attempt, due to overconfidence and hurry, the checklist item `set and check the flap/slat lever and lights` was skipped.
But what about when checklist work? The cases we never hear about?
Checklist are an amazing tool. How many flights were saved from catastrophe by appropriately following the pre-flight checklist? How many failures in surgeries averted? How many maintenance works caught critical failures that would have gone unchecked without this simple tool?
Globally it might be hard to estimate the number of lives saved, but some individual cases tell us about the potential checklists have — for example, a 2 min checklist by the WHO (world health organisation) has shown to reduce up to 40% mortality during surgery.
This, alone, should be able to put checklists in your personal toolbox.
Gotchas in recurrent checklists
Making checklists that are used recurrently, however, is not easy. As we've seen before, if you use the same checklist for thousands of times it becomes less effective due to overconfidence. It should also be clear that if the checklist is too long, its users will also likely skip items if not the whole list.
Another issue is that checklists are great for static situations, but they get complicated with the branching logic in complex systems (which paradoxically is where checklists are used the most).
Let's imagine the simple example of a checklist for your morning routine.
[ ] - Shower?
[ ] - Deodorant, moisturiser, hair?
[ ] - Brushed your teeth?
[ ] - Umbrella - if raining?
[ ] - Winter coat - if cold?
[ ] - Gym bag - if gym day?
[ ] - Wallet, phone and keys?
[ ] - Switch off the lights?
Now, take a non gym summer day: 3 out of 8 important items become irrelevant in the current situation.
Notice how importance is different from relevance here. Just because they are not relevant right now, it does not mean they cease to be important — if you forget the gym bag on gym day, or the umbrella on a rainy day, you're still going to have a bad day.
So, how would the ideal list look like? How can we keep all important items but only show them if they are relevant? Let's forget the paper medium for a bit here, and look at this dynamic checklist template:
[ ] - Showered?
[ ] - Deodorant, moisturiser and hair?
[ ] - Brushed your teeth?
{{if forecast.status=='raining'}}
[ ]- Take Umbrella
{{endif}}
{{if forecast.min_temp < 0}}
[ ]- Take winter coat
{{endif}}
{{if today.gym_day?}}
[ ]- Take gym bag
{{endif}}
[ ] - Wallet, phone and keys?
[ ] - Switch off the lights
This starts looks better — all items that are important are in the list, but they are only shown if they are relevant to the present situation. This also has the side effect of having dynamic lists — reducing monotony — and making the list as short as possible.
So how can we take this approach and apply it to software?
Checklists have huge potential in software. Especially if we're talking about complex systems, handling sensitive information, with critical functionality for the users. You want to make sure no data gets leaked, that the code is tested, that translations are in place, copy is reviewed … the list goes on.
We can of course make a very general checklist for all changes (eg for all pull requests). But we get into the same problem as we mentioned before. Copy changes rarely need information security checks, changes in an API request don’t required copy checks… You see where we’re getting here.
This was the problem we had with our Pull request reviews. We had a very general checklist with items that did not always apply (although being critical) — just like the gym bag/winter jacket/umbrella checks from the first example.
But most problematic of all, because of the existence of items that do not always apply, adding new items would make the list too long. This made the list incomplete of items that would be relevant.
Towards the ideal software change checklist
In an ideal world you would want to use a checklist related to the changes made to the software — ie if changes are made to authentication, an authentication related checklist should be used.
One possibility would be to make something akin to code coverage. When a test is ran, code coverage tracks the executed code to verify which code lines are covered by the test. If we can map the changed lines to the tests which cover those lines we can infer what features might be affected by the changes through those tests. We would, of course, need to exclude general modules that are ran by every test, and account for those cases.
This, as it should be clear by now, is not a simple endeavour.
So let's try to turn down the over-engineering factor, and…
Meet Jonas (in alpha) !

Jonas is a middle-ground between static pull request checklists and code analysis generated checklists.
As we know, most software is divided into modules and libraries. Ideally these components should be loosely coupled, with minimal inter-dependencies — Code that does similar things belongs together. This allows us to identify components or features based on the file structure, and detect what features or components are affected by a certain pull request.
We can also use other factors to help in this task. Code quality monitors already lookout for specific expressions like # TODO or # HACK. We can also do the same and check for the presence of words such as authentication password to derive the type of changes to the code.
Based on this knowledge we can dynamically create a set of checklist according to which rules are activated by the Pull request. Additionally we can also assign a risk level to each of those checks to evaluate the overall risk of the changes being made — and even add labels like high-risk to the PRs that in turn the can trigger other workflows like running extra test suits.
An example of one of such rules is shown bellow:
risk_checks:
- level: 3
description: "You have made changes to authentication code!"
repositories:
- main-web-app
required_checks:
- base_changes_review
- ensure_tests
- security_check_logging
- security_check_elevation
extra_checks:
- do_this_extra_optional_thing
filters:
exclude_changes_in_dir:
changes_in_dir:
- "app/controllers/authentication.rb"
- "app/models/authorization.rb"
- "app/lib/auth/*"
...
keywords:
- password
- authentication
- authenticated
- authorization
...
Implementation
This idea came up while working on a small patch for ruby on rails. We were warmly welcomed by Rails-bot, which listens to github web-hooks and makes a couple of checks for the opened pull requests — For example, it labels the pull request according to the changes that were made (ActiveRecord, ActiveStorage, etc), and welcomes each contributor who opens their first pull request in the Rails project.
Rails-bot was a fork from Rust-lang-nursery — Highfive project, which in turn was a fork of Servo — highfive project. All these had very specific handlers implemented, so there was a bit of a cleanup to do.
In a couple of hours we forked the servo highfive project, stripped it of all checks we were not interested in having, wrapped it around a flask app, created a new handler for risk management with configurations in yaml, migrated the project to Python3, deployed it on Heroku and…
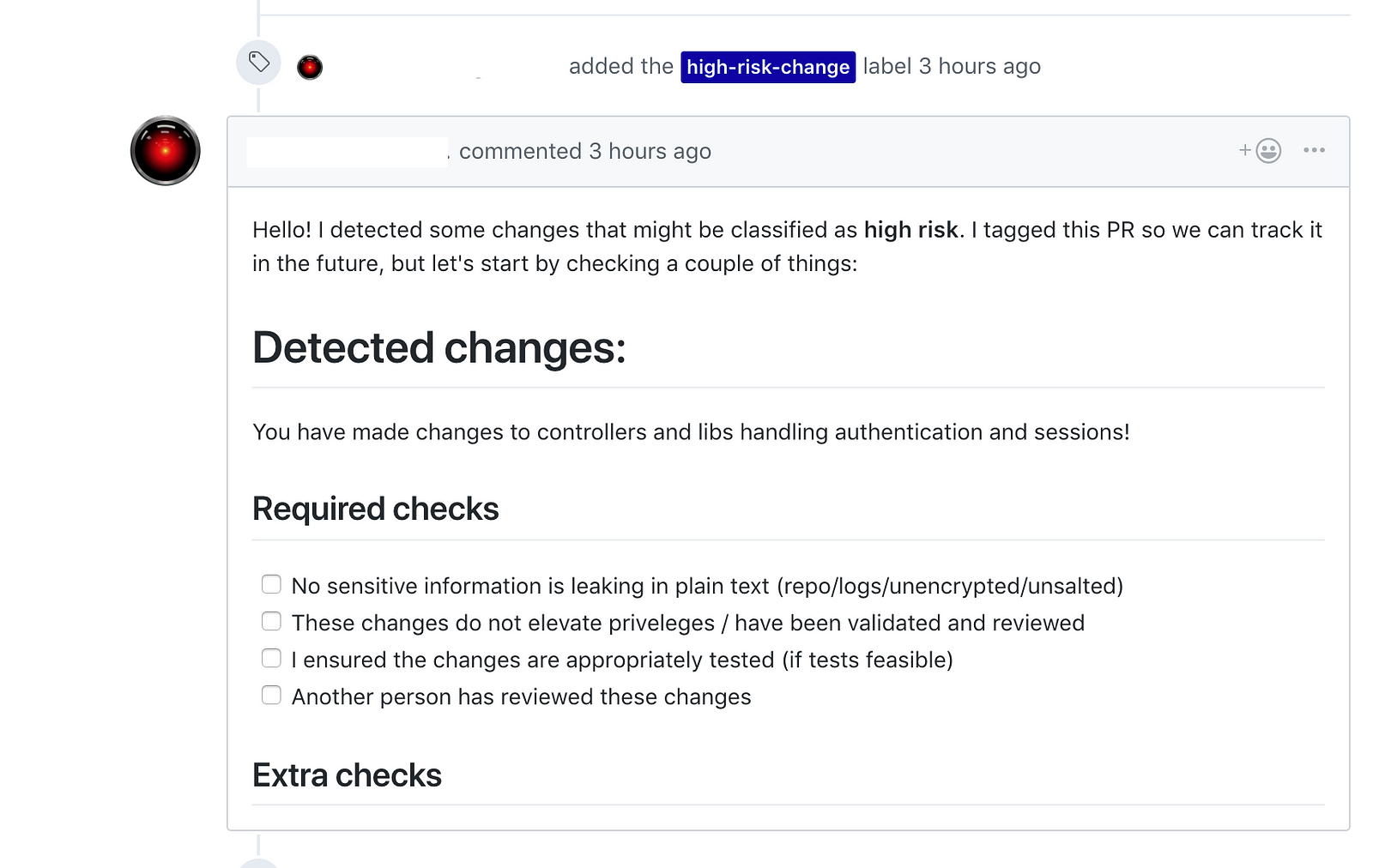
As of now, Jonas is helping us by labelling pull requests according to the risk level of the change, management of labels, and dynamically generating checklist for pull requests.
His heuristics are still in their infancy, but they are growing by the day. Jonas is helping us remove some of the manual aspects of change management while writing code, and giving some heads up to new developers about files that might pose additional risks.
It also shows that it is possible to automate and streamline a day to day process with just a couple of hours of work.