深度學習的多gpu並行嘗試——qjzcy的部落格
深度學習的多gpu並行嘗試——工作學習中的一點體會
目錄
一、 深度學習並行常用方法
二、 程式碼解析
三、 實驗結果
四、 一些細節
(一)並行常用方法:
一般有兩種方法,一種是模型並行,另一種是資料並行。
模型並行:
由於bp網路的過程是個序列的過程,所以模型並行主要用在一個gpu的視訊記憶體不能把所有的圖結構都儲存下來,於是我們把一個完整的網路切分成不同塊放在不同gpu上執行,每個gpu可能只處理某一張圖的幾分之一。
比如下圖LSTM模型分別放在了6個gpu上:

資料並行:
我們對每個gpu使用同樣的網路結構:對資料進行切分在不同的gpu上執行,每個gpu的計算結果同步或者非同步的更新模型引數。
資料並行可行性的思考:
一般來說深度學習的網路結構是個序列的過程,我們很容易有一種感覺非同步更新會不會對引數更新造成困擾,比如在一個梯度方向上原來要更新1,結果每個gpu都過來更新1,6個gpu就更新了6,這不是糾枉過正?另外一種想法是本來深度學習的模型中我們就希望會有一些隨機的擾動,
(二)程式碼解析
for i in xrange(FLAGS.num_gpus): #對每個gpu構建深度學習的圖結構
2. with tf.device('/gpu:%d' % i): #指定對哪個gpu執行構圖
3. with tf.name_scope('%s_%d' % (cifar10.TOWER_NAME, i)) as scope:
4. loss = tower_loss(scope)
5. (三)實驗結果
今天太晚,先挖坑吧
(四) 一些細節
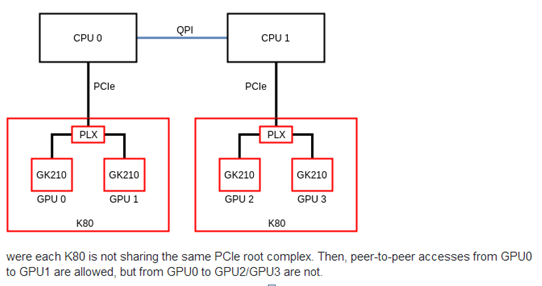
在設定多gpu的過程中發現tensorflow有這個提示,雖然並不影響執行,好奇心網上找了一下。大概是這麼個意思如下圖二,gpu0,1和gpu2,3並不能端對端直接交換資料,需要通過Qpi匯流排,顯然這樣效率要比端對端來的低。所以我們應該瞭解我們的GPU那些能端對端傳遞資料,儘量讓資料在能端對端的gpu中處理,減少匯流排資料傳輸。
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 0 to device ordinal 2
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 0 to device ordinal 3
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 1 to device ordinal 2
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 1 to device ordinal 3
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 2 to device ordinal 0
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 2 to device ordinal 1
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 3 to device ordinal 0
I tensorflow/core/common_runtime/gpu/gpu_init.cc:59] cannot enable peer access from device ordinal 3 to device ordinal 1