
QA問答系統中的深度學習技術實現
應用場景
智慧問答機器人火得不行,開始研究深度學習在NLP領域的應用已經有一段時間,最近在用深度學習模型直接進行QA系統的問答匹配。主流的還是CNN和LSTM,在網上沒有找到特別合適的可用的程式碼,自己先寫了一個CNN的(theano),效果還行,跟論文中的結論是吻合的。目前已經應用到了我們的產品上。
原理
參看《Applying Deep Learning To Answer Selection: A Study And An Open Task》,文中比較了好幾種網路結構,選擇了效果相對較好的其中一個來實現,網路描述如下:
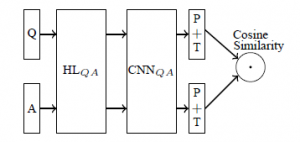
Q&A共用一個網路,網路中包括HL,CNN,P+T和Cosine_Similarity,HL是一個g(W*X+b)的非線性變換,CNN就不說了,P是max_pooling,T是啟用函式Tanh,最後的Cosine_Similarity表示將Q&A輸出的語義表示向量進行相似度計算。
詳細描述下從輸入到輸出的矩陣變換過程:
- Qp:[batch_size, sequence_len],Qp是Q之前的一個表示(在上圖中沒有畫出)。所有句子需要截斷或padding到一個固定長度(因為後面的CNN一般是處理固定長度的矩陣),例如句子包含3個字ABC,我們選擇固定長度sequence_len為100,則需要將這個句子padding成ABC<a><a>...<a>(100個字),其中的<a>就是新增的專門用於padding的無意義的符號。訓練時都是做mini-batch的,所以這裡是一個batch_size行的矩陣,每行是一個句子。
-
Q:[batch_size, sequence_len, embedding_size]。句子中的每個字都需要轉換成對應的字向量,字向量的維度大小是embedding_size,這樣Qp就從一個2維的矩陣變成了3維的Q
- HL層輸出:[batch_size, embedding_size, hl_size]。HL層:[embedding_size, hl_size],Q中的每個句子會通過和HL層的點積進行變換,相當於將每個字的字向量從embedding_size大小變換到hl_size大小。
- CNN+P+T輸出:[batch_size, num_filters_total]。CNN的filter大小是[filter_size, hl_size],列大小是hl_size,這個和字向量的大小是一樣的,所以對每個句子而言,每個filter出來的結果是一個列向量(而不是矩陣),列向量再取max-pooling就變成了一個數字,每個filter輸出一個數字,num_filters_total個filter出來的結果當然就是[num_filters_total]大小的向量,這樣就得到了一個句子的語義表示向量。T就是在輸出結果上加上Tanh啟用函式。
-
Cosine_Similarity:[batch_size]。最後的一層並不是通常的分類或者回歸的方法,而是採用了計算兩個向量(Q&A)夾角的方法,下面是網路損失函式。
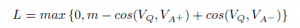 ,m是需要設定的引數margin,VQ、VA+、VA-分別是問題、正向答案、負向答案對應的語義表示向量。損失函式的意義就是:讓正向答案和問題之間的向量cosine值要大於負向答案和問題的向量cosine值,大多少,就是margin這個引數來定義的。cosine值越大,兩個向量越相近,所以通俗的說這個Loss就是要讓正向的答案和問題愈來愈相似,讓負向的答案和問題越來越不相似。
,m是需要設定的引數margin,VQ、VA+、VA-分別是問題、正向答案、負向答案對應的語義表示向量。損失函式的意義就是:讓正向答案和問題之間的向量cosine值要大於負向答案和問題的向量cosine值,大多少,就是margin這個引數來定義的。cosine值越大,兩個向量越相近,所以通俗的說這個Loss就是要讓正向的答案和問題愈來愈相似,讓負向的答案和問題越來越不相似。
實現
程式碼點選這裡,使用的資料是一份英文的insuranceQA,下面介紹程式碼重點部分:
字向量。本文采用字向量的方法,沒有使用詞向量。使用字向量的目的主要是為了解決未登入詞的問題,這樣在測試的時候就很少會遇到Unknown的字向量的問題了。而且字向量的效果也不一定比詞向量的效果差,還省去了分詞的各種麻煩。先用word2vec生成一份字向量,相當於我們在做pre-training了(之後測試了隨機初始化字向量的方法,效果差不多)
原理中的步驟2。這裡沒有做HL層的變換,實際測試中,增加HL層有非常非常小的提升,所以在這裡就省去了改步驟。
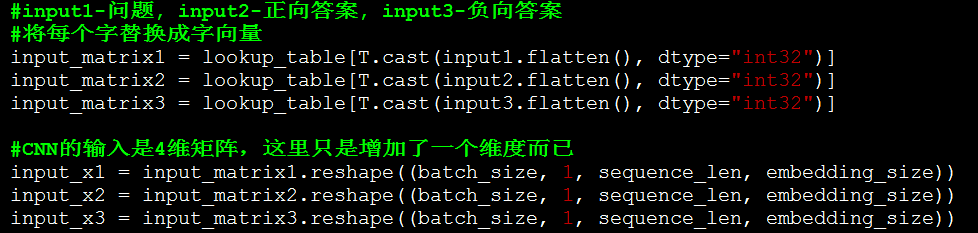
CNN可以設定多種大小的filter,最後各種filter的結果會拼接起來。

原理中的步驟4。這裡執行卷積,max-pooling和Tanh啟用。

生成的ouputs_1是一個python的list,使用concatenate將list的多個tensor拼接起來(list中的每個tensor表示一種大小的filter卷積的結果)
原理中的步驟5。計算問題、正向答案、負向答案的向量夾角

生成Loss損失函式和Accuracy。
核心的網路構建程式碼就是這些,其他的程式碼都是訓練資料、驗證資料的讀入,以及theano構建訓練時的一些常規程式碼。
如果需要增加HL層,可參照如下的程式碼。Whl即是HL層的網路,將input和Whl點積即可。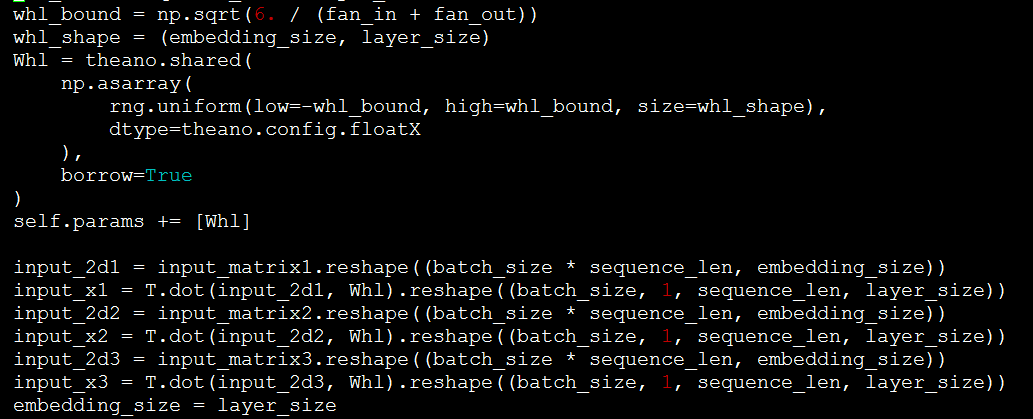
dropout的實現。

結果
使用上面的程式碼,Test 1的Top-1 Accuracy可以達到61%-62%,和論文中的結論基本一致了,至於論文中提到的GESD、AESD等方法沒有再測試了,執行較慢,其他資料集也沒有再測試了。
下面是國外友人用一個叫keras的工具(封裝的theano和tensorflow)弄的類似程式碼,Test 1的Top-1準確率在50%左右,比他這個要高:)
http://benjaminbolte.com/blog/2016/keras-language-modeling.html
| TEST SET | TOP-1 ACCURACY | MEAN RECIPROCAL RANK |
|---|---|---|
| Test 1 | 0.4933 | 0.6189 |
| Test 2 | 0.4606 | 0.5968 |
| Dev | 0.4700 | 0.6088 |
另外,原始的insuranceQA需要進行一些處理才能在這個程式碼上使用,具體參看github上的說明吧。
一些技巧
- 字向量和詞向量的效果相當。所以優先使用字向量,省去了分詞的麻煩,還能更好的避免未登入詞的問題,何樂而不為。
- 字向量不是固定的,在訓練中會更新。
- Dropout的使用對最高的準確率沒有很大的影響,但是使用了Dropout的結果更穩定,準確率的波動會更小,所以建議還是要使用Dropout的。不過Dropout也不易過度使用,比如Dropout的keep_prob概率如果設定到0.25,則模型收斂得更慢,訓練時間長很多,效果也有可能會更差,設定會差很多。我這版程式碼使用的keep_prob為0.5,同時保證準確率和訓練時間。另外,Dropout只應用到了max-pooling的結果上,其他地方沒有再使用了,過多的使用反而不好。
- 如何生成訓練集。每個訓練case需要一個問題+一個正向答案+一個負向答案,很明顯問題和正向答案都是有的,負向答案的生成方法就是隨機取樣,這樣就不需要涉及任何人工標註工作了,可以很方便的應用到大資料集上。
- HL層的效果不明顯,有很微量的提升。如果HL層的大小是200,字向量是100,則HL層相當於將字向量再放大一倍,這個感覺沒有多少資訊可利用的,還不如直接將字向量設定成200,還省去了HL這一層的變換。
- margin的值一般都設定得比較小。這裡用的是0.05
- 如果將Cosine_similarity這一層換成分類或者回歸,印象中效果是不如Cosine_similarity的(具體資料忘了)
- num_filters越大並不是效果越好,基本到了一定程度就很難提升了,反而會降低訓練速度。
- 同時也寫了tensorflow版本程式碼,對比theano的,效果差不多。
- Adam和SGD兩種訓練方法比較,Adam訓練速度貌似會更快一些,效果基本也持平吧,沒有太細節的對比。不過同樣的網路+SGD,theano好像訓練要更快一些。
- Loss和Accuracy是比較重要的監控引數。如果寫一個新的網路的話,類似的指標是很有必要的,可以在每個迭代中評估網路是否正在收斂。因為除錯比較麻煩,所以通過這些引數能評估你的網路寫對沒,引數設定是否正確。
- 網路的引數還是比較重要的,如果一些引數設定不合理,很有可能結果千差萬別,記得最初用tensorflow實現的時候,應該是dropout設定得太小,導致效果很差,很久才找到原因。所以調參和微調網路還是需要一定的技巧和經驗的,做這版程式碼的時候就經歷了一段比較痛苦的調參過程,最開始還懷疑是網路設計或是程式碼有問題,最後總結應該就是引數沒設定好。
結語
如果關注這個東西的人多的話,後面還可以有tensorflow版本的QA CNN,以及LSTM的程式碼奉上:)
補充
tensorflow的CNN程式碼已新增到github上,點選這裡
Contact: [email protected] weibo:碼壇奧沙利文