
機器學習(八)——感知器學習演算法(The perceptron learning algorithm)
現在,讓我們簡要地談論一個歷史上曾經令人很感興趣的演算法,當學習到學習理論章節的時候我們將還會提到這個。試想一下修改logistic迴歸的方法,來“迫使”它能夠輸出除了0或1亦或是其它以外的輸出值。為了達到這個目的,自然而然地會想到去改變閾值函式 gg 的定義:
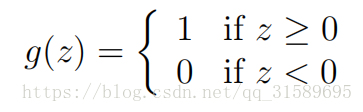
接下來,如果我們和前面一樣令 hθ(x)=g(θTx)hθ(x)=g(θTx) ,但卻使用修改了定義的函式 gg ,如果我們使用的是這個更新規則:
θj:=θj+α(y(i)−hθ(x(i)))x(i)jθj:=θj+α(y(i)−hθ(x(i)))xj(i)
這樣我們就得到了感知器學習演算法。
在 19世紀60 年代,這個“感知器(perceptron)”被認為是對大腦中單個神經元工作方法的一個粗略建模。考慮到這個演算法比較簡單,我們後續在本課程中講學習理論的時候也會作為分析的起點來講一講。但一定要注意,雖然這個感知器學習演算法可能看上去表面上跟我們之前講的其他演算法挺相似,但實際上這是一個和logistic迴歸以及最小二乘線性迴歸等演算法在種類上都完全不同的演算法;尤其重要的是,很難去對感知器的預測賦予有意義的概率解釋,也很難作為一種最大似然估計演算法來推導感知器學習演算法。相關推薦
機器學習(八)——感知器學習演算法(The perceptron learning algorithm)
現在,讓我們簡要地談論一個歷史上曾經令人很感興趣的演算法,當學習到學習理論章節的時候我們將還會提到這個。試想一下修改logistic迴歸的方法,來“迫使”它能夠輸出除了0或1亦或是其它以外的輸出值。為了達到這個目的,自然而然地會想到去改變閾值函式 gg 的定義:接下來,如果我
【深度學習】深入理解優化器Optimizer演算法(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
1.http://doc.okbase.net/guoyaohua/archive/284335.html 2.https://www.cnblogs.com/guoyaohua/p/8780548.html 原文地址(英文論文):https://www.cnblogs.c
Digression:The perceptron learning algorithm(感知機學習演算法)
''' Author :Chao Liu Data:2013/12/9 Algorithm: perceptron ''' import numpy import matplotlib.pyplot as plt ''' decision function ''' def h_function(W,x):
閒談:感知器學習演算法(The perceptron learning algorithm)
這一節我們簡單地介紹歷史上的著名演算法——感知器演算法,這在後面的學習理論中也會有所提及。設想我們改變邏輯迴歸演算法,“迫使”它只能輸出-1或1抑或其他定值。在這種情況下,之前的邏輯函式ggg就會變成閾值函式signsignsign: sign(z)={1if
感知機演算法(Perceptron Learning Algorithm)和程式碼實現(Python)
PLA演算法是機器學習中最為基礎的演算法,與SVM和Neural Network有著緊密的關係。 &n
PLA演算法的理解(perceptron learning algorithm)
最近在學習臺大林軒田教授的課程,一開始就講到了perceptron learning algorithm,這個演算法是用來對線性可分資料進行分類的。要注意這裡是線性可分的資料,這個也是PLA演算法的侷限的地方,如果PLA演算法運用線上性不可分的資料中的時候,演算法將會無限迴圈下去,還有就
(轉載)深度學習基礎(1)——感知器
原文地址:https://zybuluo.com/hanbingtao/note/581764 轉載在此的目的是自己做個筆記,日後好複習,如侵權請聯絡我!! 深度學習是什麼? 在人工智慧領域,有一個方法叫機器學習。在機器學習這個方法裡,有一類演算法叫神經網路。神經網路如下圖所示: 上圖的每
深度學習入門筆記系列(三)——感知器模型和 tensorboard 的使用方法
本系列將分為 8 篇 。今天是第三篇 。主要講講感知器模型和 tensorboard 的基本使用方法 。 1. 感知器模型 因為小詹之前寫過一篇感知器模型的介紹 ,這裡就不贅述了 。有需要鞏固的點選如下連結跳轉即可 : 2. tensorboard Tenso
機器學習方法(八):隨機取樣方法整理(MCMC、Gibbs Sampling等)
轉載請註明出處:Bin的專欄,http://blog.csdn.net/xbinworld 本文是對參考資料中多篇關於sampling的內容進行總結+搬運,方便以後自己翻閱。其實參考資料中的資料寫的比我好,大家可以看一下!好東西多分享!PRML的第11章也是sampling,
機器學習算法一:感知器學習
描述 down display 得到 更新 begin 機器 min ria 問題描述: 給定線性可分數據集:T={(x1,y1),(x2,y2),...,(xN,yN)},存在超平面S:$w\cdot x+b=0$ $ \left\{\begin{matrix} w\
機器學習實戰(Machine Learning in Action)學習筆記————06.k-均值聚類演算法(kMeans)學習筆記
機器學習實戰(Machine Learning in Action)學習筆記————06.k-均值聚類演算法(kMeans)學習筆記關鍵字:k-均值、kMeans、聚類、非監督學習作者:米倉山下時間:2018-11-3機器學習實戰(Machine Learning in Action,@author: Pet
Ubuntu作業系統學習筆記2(vi文字編輯器、程序的基本狀態及其轉換)
文字編輯器是對純文字檔案進行編輯、檢視、修改等操作的應用程式。vi編輯器具有文字編輯的所有功能,並且執行速度快,具有強大的編輯功能,廣泛的適用性和靈活性。 一、vi文字編輯器 1、vi編輯器的啟動與退出 (1)啟動 格式:vi [檔名] 檔名有以下情況: 未指定檔
Go語言學習第八課-結構體與包(Go語言的面向物件)
接下來講解一下Go語言中的面向物件思想程式設計。在Go語言面向物件與其它面嚮物件語言有著很大的差別。首先Go語言的不存在繼承和多型,而且不存在建構函式。並且Go語言不採用class來實現類,而是採用結構體加指標實現。不得不說,這讓類的定義變得很複雜,但是又不失合理
Python學習之windows音樂播放器之路(一)
1.python讀取檔案操作 與函式返回值: def getFilePath(): try: f = open("C:\\Users\\tangjing\\Desktop\\t
《Microsoft SQL Server 2008 Analysis Services Step by Step》學習筆記八:使用帳戶智慧(上)
導讀:本文介紹如何使用賬戶智慧(Account Intelligence) 本文末尾提供兩個專案原始碼:AdventureWorks_BI_Begin5和AdventureWorks_BI_End5,顧名思義,開始和完成。另外,包括資料庫檔案SSAS2008SBS_Da
Python3《機器學習實戰》01:k-近鄰演算法(完整程式碼及註釋)
執行平臺: Windows Python版本: Python3 IDE: Anaconda3 # -*- coding: utf-8 -*- """ Created on Sun Apr 29 20:32:03 2018 @author: Wang
機器學習——聚類(clustering):K-means演算法(非監督學習)
1、歸類 聚類(clustering):屬於非監督學習(unsupervised learning),是無類別標記(class label) 2、舉例 3、K-means演算法 (1)K-means演算法是聚類(clustering)中的經典演算法,資料探勘的十大經典演算
vi(vim)編輯器 學習筆記
vi是非圖形化的編輯器 vim是vi的加強版。 三種使用模式 一般模式使用者可以進行游標的移動,刪除字元以及複製 編輯模式下,使用者可以插入或者刪除字元 命令模式下,可以儲存檔案或者退出編輯器 移動操作 向下移動游標:下箭頭,j,空格 向上移動游標:
機器學習教程之1-感知器(Perceptron)的sklearn實現
0.概述 優點: 簡單且易於實現 缺點: 1.感知器模型 如果資料是線性可分的,並且是二分類的,則可以以下函式模型表示輸入到輸出的關係: 2.感知器學習策略 將所有誤分點到超平
機器學習系列之樸素貝葉斯演算法(監督學習-分類問題)
''' @description :一級分類:監督學習,二級分類:分類(離散問題),三級分類:貝葉斯演算法 演算法優點: a 樸素貝葉斯模型發源於古典數學理論,有穩定的分類效率 b 對缺失的資料不太敏感,演算法也比較簡