
PLA演算法的理解(perceptron learning algorithm)
最近在學習臺大林軒田教授的課程,一開始就講到了perceptron learning algorithm,這個演算法是用來對線性可分資料進行分類的。要注意這裡是線性可分的資料,這個也是PLA演算法的侷限的地方,如果PLA演算法運用線上性不可分的資料中的時候,演算法將會無限迴圈下去,還有就是即使我們的資料是線性可分的,我們也不知道PLA演算法什麼時候才能找到一個最優的解,可能迴圈操作幾次就可以得到,也有可能需要很多次才能找到最優解,其實在不知道的情況下,我們無法預計演算法需要計算多久,這樣其實是開銷很大的,後續我們基於貪心演算法(greedy algorithm)對PLA演算法進行了改進,我們每一次的計算都保留當前的最優解,意思就是找到一個相對最優解,然後我們不斷去更新優化這個最優解。
首先我們PLA演算法是用來求解分類的那條分界線的,也就是求解我們
向量,假設我們的資料集為
,我們可以用這條線將我們的資料X分成正負兩個部分,用數學表示式可以將假設函式h(x)表示成:
我們將分界線的向量和資料集進行內積運算,然後減去一個閾值,最後加上一個sign函式將資料進行分類操作,結果1表示正類,-1表示負類。在這個公式裡這個閾值看著比較礙眼,我們可以將閾值項threshold看作是w0和x0相乘,w0看做是-threshold,x0看做是1,那麼整個公式可以表示成:
由上述數學公式我們可以得到
,在假設函式h(x)中,X是已知的資料集,要求W的向量,
的值會把我們資料集分成正負兩個類,PLA的演算法就是在不斷地糾正我們的分類錯誤,糾正的方法如下所示:
- 正類+1被預測到了負類-1
這個時候,x的實際指向是正方向,也就是說y=+1,但是預測到了-1,也就是說 ,這裡x的指向表示y的布林值,我們可以用向量圖來表示:
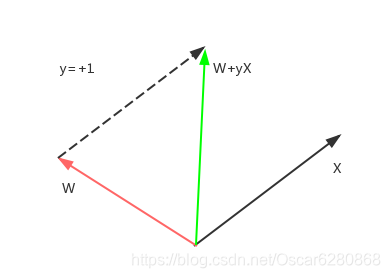
在上圖中X是正類,但是與預測的W向量夾角大於90度,所以 ,我們如何來糾正這個向量呢?我們可以將W和X向量相加,這裡需要注意的是X還需要乘以一個y,來表示向量的方向,同時也表示W分割線調整的方向。這個時候y=+1,所以我們新調整的W是W+X,如圖所示,紅色的向量表示預測錯誤的向量,我們加上實際的X向量,就可以得到調整之後的綠色的向量,可以看到綠色的向量相比紅色的向量更加靠近X向量了,夾角也小於90度,這樣就可以糾正原來的錯誤預測了。 - 負類-1被預測到了正類+1
同樣的道理,X的向量指向負的情況下,但是由於預測錯誤,W向量和X向量夾角小於90度,所以 ,我們同樣需要y*X來調整新的預測,我們可以得到下圖:
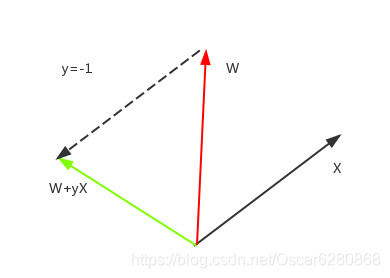
由上圖可以看出,黑色的向量X和紅色的向量W,由於夾角小於90度,所以 ,這個時候需要調整新的W向量,這個時候y=-1,所以W+yX=W-X,就相當於是兩個向量相減,得到新的調整之後的綠色的向量,這樣新調整的向量與原有的X向量的夾角大於90度,那麼 ,這樣錯誤就糾正了。
有了上面就正錯誤點的方法,我們可以不斷地更新W,直到找到最優解,用虛擬碼可以表示成:
init w(0)=0
for t = 0,1,2,3,...:
for i = 1,2,3,4,...,n:
w(t+1) = w(t) + y(i) * x(i)
end
//直到所有的點都被正確分類,我們就停止更新W
有的朋友就會有疑問了,會不會有這個迴圈停不下來的情況,答案是不會的,這個演算法到最後一定是會停下來的。下面我們就來證明一下。首先我們假設有一條理想的分割線
,因為
和
一定是同號的,那麼
一定是大於0的,所以可以得到: