
機器學習教程之1-感知器(Perceptron)的sklearn實現
0.概述
優點:
簡單且易於實現
缺點:
1.感知器模型
如果資料是線性可分的,並且是二分類的,則可以以下函式模型表示輸入到輸出的關係:
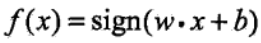
2.感知器學習策略
將所有誤分點到超平面距離之和表示為代價函式:
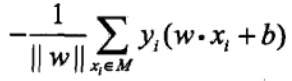
不考慮
,得到感知器的代價函式:

說明:李航的書用L(w,b)表示代價函式,而Ng教程用J()表示代價函式。
3.感知器學習演算法


4.程式碼
# @Author: Tianze Tang
# @Date: 2017-07-10
# @Email: [email protected]
# @Last modified by: Tianze Tang 
5.總結

6.參考資料
相關推薦
機器學習教程之1-感知器(Perceptron)的sklearn實現
0.概述 優點: 簡單且易於實現 缺點: 1.感知器模型 如果資料是線性可分的,並且是二分類的,則可以以下函式模型表示輸入到輸出的關係: 2.感知器學習策略 將所有誤分點到超平
機器學習(八)——感知器學習演算法(The perceptron learning algorithm)
現在,讓我們簡要地談論一個歷史上曾經令人很感興趣的演算法,當學習到學習理論章節的時候我們將還會提到這個。試想一下修改logistic迴歸的方法,來“迫使”它能夠輸出除了0或1亦或是其它以外的輸出值。為了達到這個目的,自然而然地會想到去改變閾值函式 gg 的定義:接下來,如果我
機器學習教程 之 引數搜尋:GridSearchCV 與 RandomizedSearchCV || 以阿里IJCAI廣告推薦資料集與XGBoostClassifier分類器為例
在使用一些比較基礎的分類器時,需要人為調整的引數是比較少的,比如說K-Neighbor的K和SVM的C,通常而言直接使用sklearn裡的預設值就能取得比較好的效果了。 但是,當使用一些大規模整合的演算法時,引數的問題就出來了,比如說 XGBoost的引數大概
機器學習教程 之 Boosting 與 bagging:整合學習框架
整合學習是機器學習演算法中非常耀眼的一類方法,它通過訓練多個基本的分類器(如支援向量機、神經網路、決策樹等),再通過基本分類器的決策融合,構成一個完整的具有更強學習分辨能力的學習器。在整合學習中,那些基本學習器一般被稱為為“弱學習器“,機器學習的目的就是通過整合
Spark2.0機器學習系列之1:基於Pipeline、交叉驗證、ParamMap的模型選擇和超引數調優
Spark中的CrossValidation Spark中採用是k折交叉驗證 (k-fold cross validation)。舉個例子,例如10折交叉驗證(10-fold cross validation),將資料集分成10份,輪流將其中9份
機器學習教程 之 整合學習演算法: 深入刨析AdaBoost
Boosting 是一族可以將弱學習器提升為強學習器的演算法。這族演算法的工作機制類似:先從初始訓練集訓練出一個基學習器,再根據基學習器的表現對訓練樣本分佈進行調整,使得先前基學習器做錯的訓練樣本在後續受到更多的關注,然後基於調整後的樣本分佈來訓練下一個基學習器
機器學習教程之13-決策樹(decision tree)的sklearn實現
0.概述 決策樹(decision tree)是一種基本的分類與迴歸方法。 主要優點:模型具有可讀性,分類速度快。 決策樹學習通常包括3個步驟:特徵選擇、決策樹的生成和決策樹的修剪。 1.決策樹模型與學習 節點:根節點、子節點;內部節點(inter
Python機器學習筆記:SVM(4)——sklearn實現
上一節我學習了SVM的推導過程,下面學習如何實現SVM,具體的參考連結都在第一篇文章中,SVM四篇筆記連結為: Python機器學習筆記:SVM(1)——SVM概述 Python機器學習筆記:SVM(2)——SVM核函式 Python機器學習筆記:SVM(3)——證明SVM Python機器學習筆記:SV
斯坦福機器學習教程學習筆記之1
本系列部落格主要摘自中國海洋大學黃海廣博士翻譯整理的機器學習課程的字幕及筆記,在我的學習過程中幫助很大,在此表示誠摯的感謝! 本系列其他部分: 一、引言 監督學習(Supervised Learning):分類問題、迴歸問題等。 無監督學習(Unsupervi
機器學習演算法之自適應線性感知器演算法
自適應線性感知器演算法 原理推導 python實現 import numpy as np import matplotlib.pyplot as plt #隨機生成x和y, n=100, m=2 x = np.random.randn(1
機器學習筆記(1) 感知機演算法 之 實戰篇
我們在上篇筆記中介紹了感知機的理論知識,討論了感知機的由來、工作原理、求解策略、收斂性。這篇筆記中,我們親自動手寫程式碼,使用感知機演算法解決實際問題。 先從一個最簡單的問題開始,用感知機演算法解決OR邏輯的分類。 import numpy as np import matplotlib.pyplot as
機器學習筆記之(4)——Fisher分類器(線性判別分析,LDA)
本博文為Fisher分類器的學習筆記~本博文主要參考書籍為:《Python大戰機器學習》Fisher分類器也叫Fisher線性判別(Fisher Linear Discriminant),或稱為線性判別分析(Linear Discriminant Analysis,LDA)。
機器學習演算法之隨機森林(1)pyspark.mllib中的RF
spark的persist操作可以使得資料常駐記憶體,而機器學習最主要的工作——迭代,需要頻繁地存取資料,這樣相比hadoop來說,天然地有利於機器學習。 ———- 單機版。 至於叢集的搭建——現在手頭最多兩臺電腦,後面再折騰。 1、安裝pysaprk
《深入理解Java虛擬機器》學習筆記之垃圾收集器與記憶體分配策略
一、概述 GC(Garbage Collection)需要完成的三件事 (1)哪些記憶體需要回收 (2)什麼時候回收 (3)如何回收 GC主要面向Java堆和方法區中的記憶體 原因:這部份
周志華 《機器學習》之 第七章(貝葉斯分類器)概念總結
貝葉斯分類器是利用概率的知識完成資料的分類任務,在機器學習中使用貝葉斯決策論實施決策的基本方法也是在概率的框架下進行的,它是考慮如何基於這些概率和誤判損失來選擇最優的類別標記。 1、貝葉斯決策論 條件風險:假設有N種可能的類別標記,Y={c1,c2,c3
[機器學習] 貝葉斯分類器1
貝葉斯分類的先導知識 條件概率 所謂條件概率,它是指某事件B發生的條件下,求另一事件A的概率,記為P(A|B)P(A|B),它與P(A)P(A)是不同的兩類概率。 舉例: 考察有兩個小孩的家庭, 其樣本空間為Ω=[bb,bg,gb,gg]Ω=[bb,b
STM32CubeMX學習教程之四:定時器中斷
完整原始碼下載:https://github.com/simonliu009/STM32CubeMX-TIM1-Interrupt軟體:STM32CubeMX V4.25.0 System Workbench V2.4韌體庫版本:STM32Cube FW_F1 V1.6.1
機器學習入門之《統計學習方法》筆記整理——感知機
從頭開始學習李航老師的《統計學習方法》,這本書寫的很好,非常適合機器學習入門。 如果部分顯示格式有問題請移步Quanfita的部落格檢視 目錄 感知機模型 什麼是感知機?感知機是二類分類的線性分類模型,其輸入為例項的特徵向量
深度學習1--感知器
# -*- coding: utf-8 -*- """ Created on Thu Apr 12 18:01:30 2018 @author: SS """ ''' and 感知器的實現 用到的函式 包括: 初始化: __init__ 列印:__str__ 預測:pr
阿里雲機器學習技術分享1——影象識別之TensorFlow實現方法【視訊+PPT】
阿里雲AI之影象識別技術是如何實現的!?視訊+PPT乾貨奉上 講師簡介:趙昆 阿里巴巴機器學習技術專家 歡迎加入阿里雲機器學習大家庭,**釘釘群:11768691** , QQ群:567810612 一、阿里雲機器學習之影象識別實踐-基礎篇: 觀看視訊:http://cl