
MapReduce程式設計例項之WordCount
阿新 • • 發佈:2019-01-26
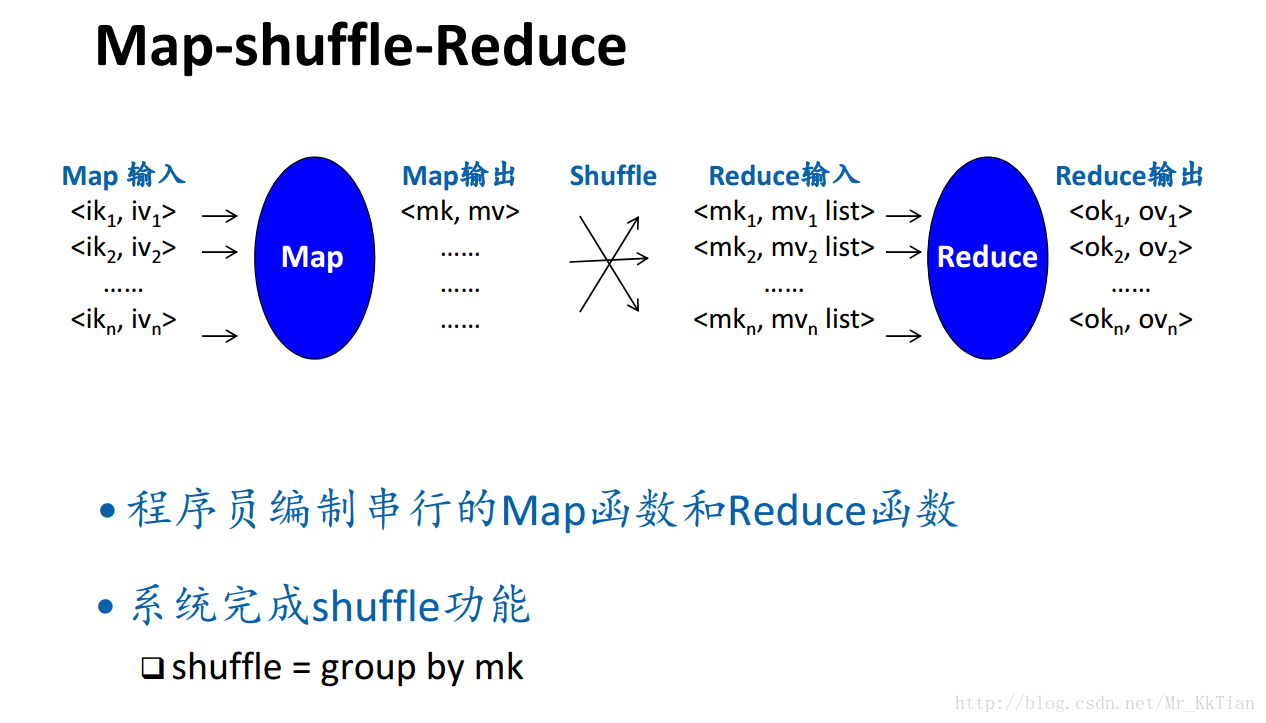
1.MapReduce計算框架
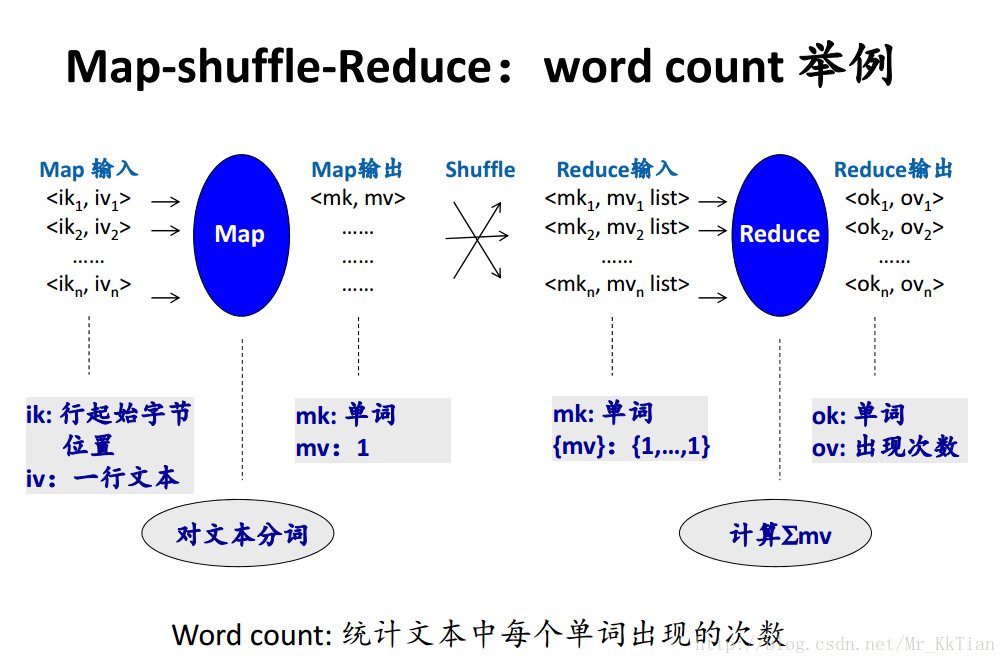
2.例項WordCount
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache