
Mapreduce程式設計1之WordCount
阿新 • • 發佈:2019-02-16
Mapreduce是hadoop的計算框架,對資料的處理操作都要在這裡程式設計來實現功能。
這是我學習的第一個程式,也算是入門程式,相當於其他語言的helloworld,雖然還有很多不懂的地方,但相信通過以後的學習能夠懂更多東西。
WordCount
實現的功能就是統計單詞出現的次數,涉及到一個文字測試檔案test.txt
Mapreduce分為Map(對映)和Reduce(化簡)。在使用Mapreduce程式設計之前第一步就需要將資料抽象成鍵值對的形式,世間萬物都可以用鍵值對來標識,沒有約束。接著map函式會以鍵值對輸入,經過map函式的處理,產生一系列新的鍵值對作為中間值到本地。Mapreduce計算框架會自動將這些鍵值對做聚合
{key1,value1}–>{key2,list{values}}–>{key3,value3}
對於單詞計數來說這個過程可以表示如下
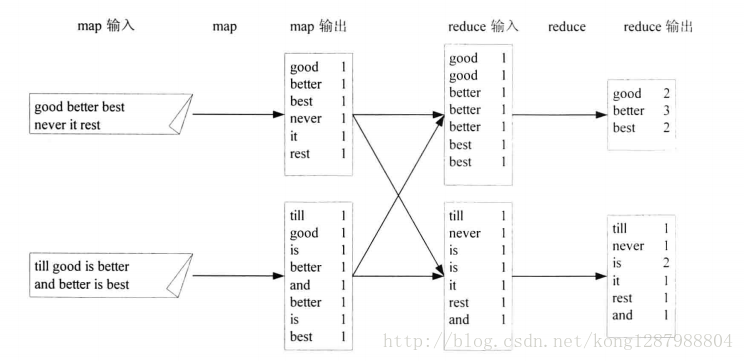
首先hadoop的hdfs會把檔案邏輯分割槽成DataNode個數的邏輯分片,然後每個分片都會按你定好的規則來完成任務job,也就是你寫的mapreduce了。
這道題首先要對這個檔案預處理,按行來解析,每行都利用java的StringTokenizer來分離成單詞。然後把分離的單詞作為key1,把定死的值1作為value1,意思就是這個單詞,一次。把這些零碎的鍵值對都丟到map的輸出就好啦,虛擬空間假象圖大概是這樣……

之後把這一堆東西丟給reduce,它會預設給這些東西排序並聚合,所謂的聚合就是把key值相同的的合併,value值聚在一塊(*並不是把value加一塊),也就形成了reduce的輸入key2,list
<values> 大概就是這種構建狀態:

再之後我們在reduce中做的操作就是整理這些鍵值對作為標準輸出key3,value3鍵值對:

大概的思路已經清晰了,接下來上程式碼:
TokenizerMapper
package com.hellohadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import IntSumReducer
package com.hellohadoop;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException {
int sum=0;
for(IntWritable val:values){
sum+=val.get();
}
result.set(sum);
context.write(key, result);
}
}
WordCount
package com.hellohadoop;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String args[]) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
if (args.length != 2) {
System.out.println("Usage:wordcount<in><out>");
System.exit(2);
}
Job job = new Job(conf, "wordcount");
job.setJarByClass(WordCount.class);
// 指定Mapper類
job.setMapperClass(TokenizerMapper.class);
// 指定Reduce類
job.setReducerClass(IntSumReducer.class);
// 設定reduce函式輸出key的類
job.setOutputKeyClass(Text.class);
// 設定reduce函式輸出value的類
job.setOutputValueClass(IntWritable.class);
// 指定輸入路徑
FileInputFormat.addInputPath(job, new Path(args[0]));
// 指定輸出路徑
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 提交任務
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
只寫想法和程式碼,具體程式碼內容自行體會嘿嘿