
基於大資料做文字分析
在對大資料的認識中,人們總結出它的4V特徵,即容量大、多樣性、生產速度快和價值密度低,為此產生出大量的技術和工具,推動大資料領域的發展。為了利用好大資料,如何有效的從其中提取有用特徵,也是重要的一方面,工具和平臺化必須依靠正確的資料模型和演算法才能凸顯出其重要的價值。
現在就文字分析作為案例來分析資料處理技術在大資料領域的作用和影響。首先討論文字分析的三種模型:詞袋模型、TF-IDF短語加權表示和特徵雜湊。
“Bag ofwords,也叫做“詞袋”,在資訊檢索中,Bag of wordsmodel假定對於一個文字,忽略其詞序和語法、句法,將其僅僅看做是一個詞集合或者說是詞的一個組合,文字中每個詞的出現都是獨立的,不依賴於其他詞是否出現或者說當這篇文章的作者在任意一個位置選擇一個詞彙都不受前面句子的影響而獨立選擇的。”
其處理過程如下:
· 分詞:將分本分割為詞的集合。
· 刪除停用詞,比如the、and、but等。
· 提取詞幹,即將各個詞簡化為其基本形式,也就是歸一化。
· 向量化,用向量表示處理好的詞,二元向量是最為簡單的表示方式,用1/0來表示是否存在某個詞。隨著詞數量的增加,比如幾百萬,使用稀疏矩陣僅僅記錄該詞是否出現過,從而節省記憶體和磁碟空間、計算時間。
這種假設雖然對自然語言進行了簡化,便於模型化,但是其假定在有些情況下是不合理的,例如在新聞個性化推薦中,採用Bagof words的模型就會出現問題。例如使用者甲對“南京醉酒駕車事故”這個短語很感興趣,採用bagof words忽略了順序和句法,認為使用者甲對“南京”、“醉酒”、“駕車”和“事故”感興趣,因此可能推薦出和“南京”、“公交車”、“事故”相關的新聞,這顯然是不合理的。
下面介紹兩種SparkMLlib包含的兩種特徵提取技術。
“TF-IDF,詞頻-逆文字頻率。其中,詞頻基於單詞在文字中出現的頻率為每一個詞賦予一個權值,逆文字頻率則基於單詞在所有文件中的頻率計算得出。”
這一技術設計的初衷在於字詞的重要性隨著它在檔案中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降,這樣的設計均在於更好的表達此詞或者短語的類別區分能力。適合用來分類TF-IDF加權的各種形式常被搜尋引擎應用,作為檔案與使用者查詢之間相關程度的度量或評級。
“特徵雜湊使用雜湊方程對特徵賦予向量下標,它需要預先選擇特徵向量的大小。”
如果特徵數量爆炸式增長,就需要進行降維處理,比如聚類、PCA等,但這些方法在特徵量和樣本量都很大的時候其計算量很大,在文字和分類資料上有一種簡單高效的高維資料處理技術就是特徵雜湊。
特徵雜湊法的目標是把原始的高維特徵向量壓縮成較低維特徵向量,且儘量不損失原始特徵的表達能力。其優勢在於不需要構建對映且儲存在記憶體,不需要預先掃描一遍資料集;它很容易實現且非常快,因為其維度遠遠小於資料集,限制了模型訓練和預測時記憶體的使用量。
TF-IDF不是訓練機器學習模型,而是做特徵提取或者轉化,經常用來作為降維、分類和迴歸等的預處理步驟。
利用Spark可以根據如下幾步進行計算:
Step1. 使用HashingTF,利用特徵雜湊技術把每個輸入文字的詞項應設為一次詞頻向量的下標。
tf=hashingTF.transform(tokens)
Step2. 使用一個全域性變數IDP向量把詞頻向量轉換為TF-IDF向量。
idf=new IDF().fit(tf)
tfidf=idf.transform(tf)
Trident是基於Storm進行實時流處理的高階抽象,提供了對實時流的聚集、投影、過濾等操作,大大簡化了Storm任務開發的工作量。另外,Trident提供了原語處理針對資料庫或其他持久化儲存的有狀態的、增量的更新操作。
一個Trident任務可以有多個數據源,每個資料來源都是以TridentState的形式定義在任務中。
現在利用Trident實現關於詞頻重要性的TF-IDF的計算,實現一個TridentTopology並定義一個Stream資料管道如下:
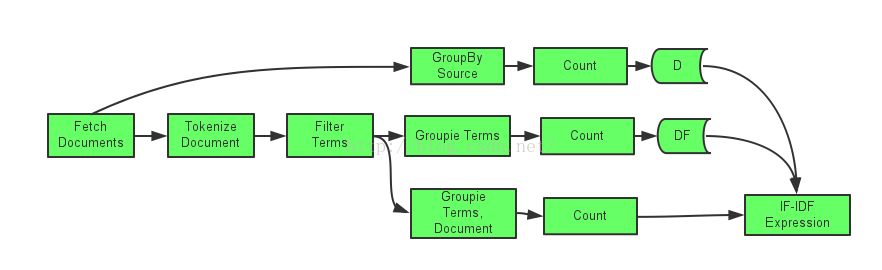
tf-idf計算公式如下:
tf-idf=tf(t,d)*log(D/1+df(t)
其中,tf(t,d)計算單詞t 在文件d中出現的頻率,df(t)計算單詞t在所有文件中出現的頻率,D計算文件總計。
其具體實現如下:
TridentState dfState=termStream.groupBy(newFileds(“term”))
.persistentAggregate(getStateFactory(“df”),newcount(),new Fields(“df”));
TridentState dState=termStream.groupBy(newFileds(“source”))
.persistentAggregate(getStateFactory(“d”),newcount(),new Fields(“d”));
Stream tfidfStream =termStream. groupBy(newFileds(“documentId”,”term”))
.persistentAggregate(new count(),new Fields(“tf”))
.each(newFileds(“term”,“documentId”,”tf”),newTfidfExpresssion(),new Fields(“tfidf”));