
Introduction to TensorFlow Lite
TensorFlow Lite is TensorFlow’s lightweight solution for mobile and embedded devices. It enables on-device machine learning inference with low latency and a small binary size. TensorFlow Lite also supports hardware acceleration with theAndroid Neural Networks API.
TensorFlow Lite uses many techniques for achieving low latency such as optimizing the kernels for mobile apps, pre-fused activations, and quantized kernels that allow smaller and faster (fixed-point math) models.
Most of our TensorFlow Lite documentation is on Github for the time being.
What does TensorFlow Lite contain?
TensorFlow Lite supports a set of core operators, both quantized and float, which have been tuned for mobile platforms. They incorporate pre-fused activations and biases to further enhance performance and quantized accuracy. Additionally, TensorFlow Lite also supports using custom operations in models.
TensorFlow Lite defines a new model file format, based on FlatBuffers. FlatBuffers is an open-sourced, efficient cross platform serialization library. It is similar to protocol buffers, but the primary difference is that FlatBuffers does not need a parsing/unpacking step to a secondary representation before you can access data, often coupled with per-object memory allocation. Also, the code footprint of FlatBuffers is an order of magnitude smaller than protocol buffers.
TensorFlow Lite has a new mobile-optimized interpreter, which has the key goals of keeping apps lean and fast. The interpreter uses a static graph ordering and a custom (less-dynamic) memory allocator to ensure minimal load, initialization, and execution latency.
TensorFlow Lite provides an interface to leverage hardware acceleration, if available on the device. It does so via the Android Neural Networks library, released as part of Android O-MR1.
Why do we need a new mobile-specific library?
Machine Learning is changing the computing paradigm, and we see an emerging trend of new use cases on mobile and embedded devices. Consumer expectations are also trending toward natural, human-like interactions with their devices, driven by the camera and voice interaction models.
There are several factors which are fueling interest in this domain:
-
Innovation at the silicon layer is enabling new possibilities for hardware acceleration, and frameworks such as the Android Neural Networks API make it easy to leverage these.
-
Recent advances in real-time computer-vision and spoken language understanding have led to mobile-optimized benchmark models being open sourced (e.g. MobileNets, SqueezeNet).
-
Widely-available smart appliances create new possibilities for on-device intelligence.
-
Interest in stronger user data privacy paradigms where user data does not need to leave the mobile device.
-
Ability to serve ‘offline’ use cases, where the device does not need to be connected to a network.
We believe the next wave of machine learning applications will have significant processing on mobile and embedded devices.
TensorFlow Lite developer preview highlights
TensorFlow Lite is available as a developer preview and includes the following:
-
A set of core operators, both quantized and float, many of which have been tuned for mobile platforms. These can be used to create and run custom models. Developers can also write their own custom operators and use them in models.
-
A new FlatBuffers-based model file format.
-
On-device interpreter with kernels optimized for faster execution on mobile.
-
TensorFlow converter to convert TensorFlow-trained models to the TensorFlow Lite format.
-
Smaller in size: TensorFlow Lite is smaller than 300KB when all supported operators are linked and less than 200KB when using only the operators needed for supporting InceptionV3 and Mobilenet.
-
Pre-tested models:
All of the following models are guaranteed to work out of the box:
-
Inception V3, a popular model for detecting the dominant objects present in an image.
-
MobileNets, a family of mobile-first computer vision models designed to effectively maximize accuracy while being mindful of the restricted resources for an on-device or embedded application. They are small, low-latency, low-power models parameterized to meet the resource constraints of a variety of use cases. They can be built upon for classification, detection, embeddings and segmentation. MobileNet models are smaller but lower in accuracy than Inception V3.
-
On Device Smart Reply, an on-device model which provides one-touch replies for an incoming text message by suggesting contextually relevant messages. The model was built specifically for memory constrained devices such as watches & phones and it has been successfully used to surface Smart Replies on Android Wear to all first-party and third-party apps.
-
-
Quantized versions of the MobileNet model, which runs faster than the non-quantized (float) version on CPU.
-
New Android demo app to illustrate the use of TensorFlow Lite with a quantized MobileNet model for object classification.
-
Java and C++ API support
Note: This is a developer release, and it’s likely that there will be changes in the API in upcoming versions. We do not guarantee backward or forward compatibility with this release.
Getting Started
We recommend you try out TensorFlow Lite with the pre-tested models indicated above. If you have an existing mode, you will need to test whether your model is compatible with both the converter and the supported operator set. To test your model, see the documentation on GitHub.
Retrain Inception-V3 or MobileNet for a custom data set
The pre-trained models mentioned above have been trained on the ImageNet data set, which consists of 1000 predefined classes. If those classes are not relevant or useful for your use case, you will need to retrain those models. This technique is called transfer learning, which starts with a model that has been already trained on a problem and will then be retrained on a similar problem. Deep learning from scratch can take days, but transfer learning can be done fairly quickly. In order to do this, you'll need to generate your custom data set labeled with the relevant classes.
The TensorFlow for Poets codelab walks through this process step-by-step. The retraining code supports retraining for both floating point and quantized inference.
TensorFlow Lite Architecture
The following diagram shows the architectural design of TensorFlow Lite:

Starting with a trained TensorFlow model on disk, you'll convert that model to the TensorFlow Lite file format (.tflite)
using the TensorFlow Lite Converter. Then you can use that converted file in your mobile application.
Deploying the TensorFlow Lite model file uses:
-
Java API: A convenience wrapper around the C++ API on Android.
-
C++ API: Loads the TensorFlow Lite Model File and invokes the Interpreter. The same library is available on both Android and iOS.
-
Interpreter: Executes the model using a set of kernels. The interpreter supports selective kernel loading; without kernels it is only 100KB, and 300KB with all the kernels loaded. This is a significant reduction from the 1.5M required by TensorFlow Mobile.
-
On select Android devices, the Interpreter will use the Android Neural Networks API for hardware acceleration, or default to CPU execution if none are available.
You can also implement custom kernels using the C++ API that can be used by the Interpreter.
Future Work
In future releases, TensorFlow Lite will support more models and built-in operators, contain performance improvements for both fixed point and floating point models, improvements to the tools to enable easier developer workflows and support for other smaller devices and more. As we continue development, we hope that TensorFlow Lite will greatly simplify the developer experience of targeting a model for small devices.
Future plans include using specialized machine learning hardware to get the best possible performance for a particular model on a particular device.
Next Steps
For the developer preview, most of our documentation is on GitHub. Please take a look at the TensorFlow Lite repositoryon GitHub for more information and for code samples, demo applications, and more.
原文地址:https://www.tensorflow.org/mobile/tflite/
http://blog.csdn.net/superloveboy/article/details/78556868?locationNum=9&fps=1
Google基於TensorFlow針對移動和嵌入式裝置輕量級的機器學習框架。
-
輕量級
啟用具有較小二進位制大小並且快速初始化/啟動裝置上機器學習模型。
-
跨平臺
可以執行設計跑到許多不同的平臺上,從Android和IOS上開始
-
快速
針對移動裝置進行了優化,包括顯著提高的模型載入時間,並支援硬體加速
目前越來越多的移動裝置採用專用的定製硬體來更有效地處理機器學習工作負載。 TensorFlow Lite支援Android神經網路API,可充分利用這些新的加速器。
當加速裝置不支援時,TensorFlow Lite退回到CPU上執行,確保你的模型仍然可以在大量裝置上快速執行。
架構
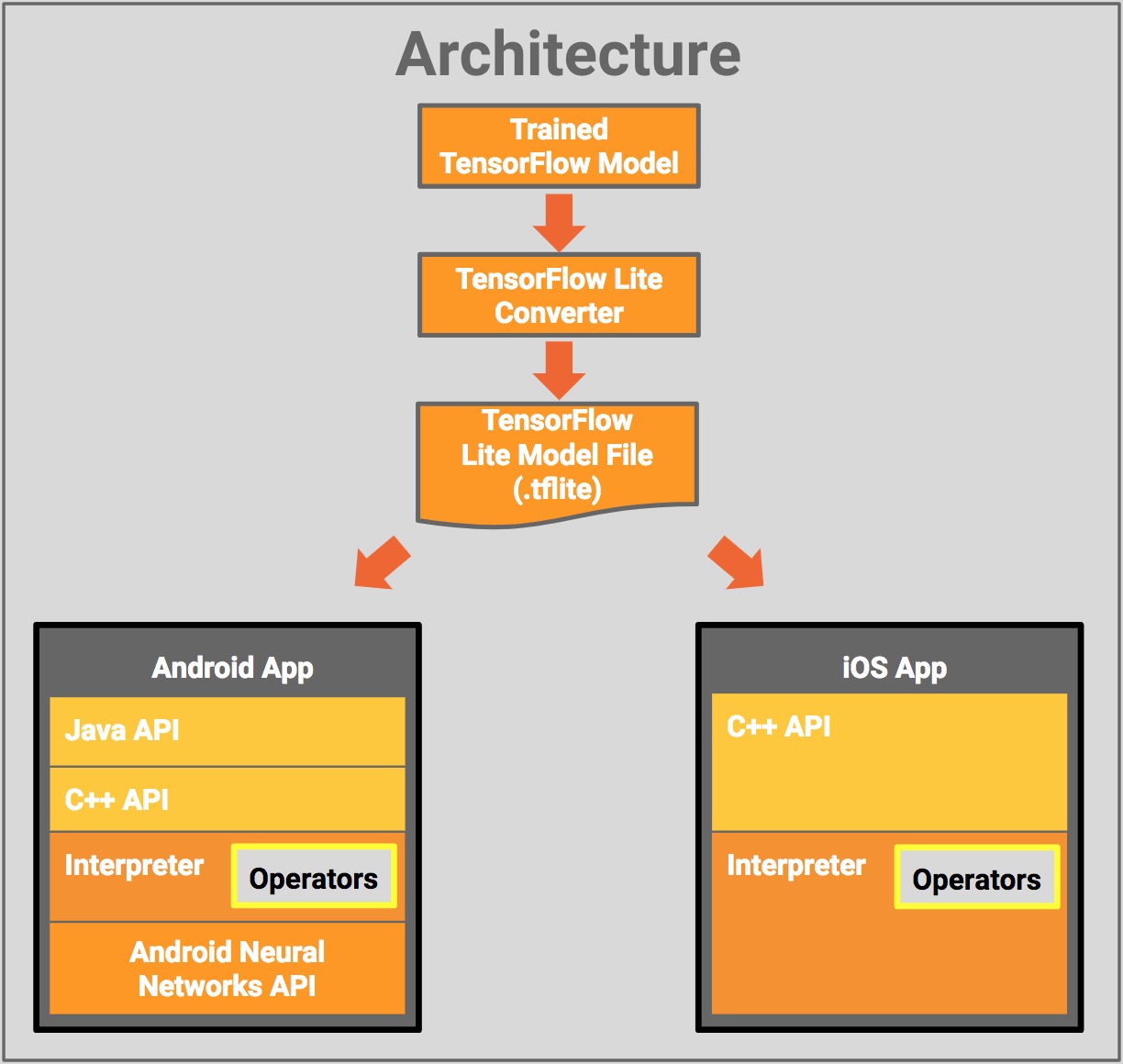
模組元件:
-
TensorFlow Model:儲存在硬碟上一個訓練好的TensorFlow 模型。
-
TensorFlow Lite Converter:將模型轉化為TensorFlow Lite檔案格式的程式。
-
TensorFlow Lite Model File:對基於FlatBuffers的模型檔案格式做了優化,使其速度最快,規格最小。
TensorFlow Lite Model File 可以部署到移動APP上,在
-
Java API : Android上C++API的便捷封裝
-
C++ API : 載入TensorFlowLite 模型檔案並呼叫直譯器。在Android和IOS上呼叫同樣的類庫。
-
Interpreter : 使用一組運算子來執行模型。直譯器支援選擇操作載入;如果沒有運算子載入,只支援70KB,載入所有的運算子之後為300KB。與TensorFlow Mobile所需的1.5M相比,這是一個明顯的降低(使用一個普通操作符集)。
-
在選擇安卓裝置上,解析器支援Android神經網路API來進行硬體加速。或者預設使用CPU,如果沒有可用的加速器的話
開發者可以使用C++API來實現自定義的kernels。
Models
TensorFlow Lite 在移動裝置已經支援大量的訓練好的模型和優化好的模型。
-
能夠識別1000種不同物件類的視覺模型,在移動裝置和嵌入式裝置上高效執行而設計。
-
影象識別模型,和MobileNet有相似的功能,提供高精度,但相對也是更大
-
裝置會話模型,可以即時回覆聊天訊息。在Android Wear上使用此功能。
Inception v3和MobileNet在ImageNet資料集上訓練。你可以很容易地利用遷移學習對你自己的影象資料集進行再訓練。
博主困了,下面這段不翻譯了
What About TensorFlow Mobile?
As you may know, TensorFlow already supports mobile and embedded deployment of models through the TensorFlow Mobile API. Going forward, TensorFlow Lite should be seen as the evolution of TensorFlow Mobile, and as it matures it will become the recommended solution for deploying models on mobile and embedded devices. With this announcement, TensorFlow Lite is made available as a developer preview, and TensorFlow Mobile is still there to support production apps.
The scope of TensorFlow Lite is large and still under active development. With this developer preview, we have intentionally started with a constrained platform to ensure performance on some of the most important common models. We plan to prioritize future functional expansion based on the needs of our users. The goals for our continued development are to simplify the developer experience, and enable model deployment for a range of mobile and embedded devices.
We are excited that developers are getting their hands on TensorFlow Lite. We plan to support and address our external community with the same intensity as the rest of the TensorFlow project. We can’t wait to see what you can do with TensorFlow Lite.
For more information, check out the TensorFlow Lite documentation pages.
Stay tuned for more updates.
Happy TensorFlow Lite coding!