
複習筆記——計算機組成原理
2014年12月考研前一週寫的筆記。。。
放在這裡,希望對其他人有幫助。。。===============================================
寫到一半時,發現這個公開課的資料挺全的:
http://share.onlinesjtu.com/course/view.php?id=3#
教材,視訊,ppt,還有swf。。。
===============================================
0.準備
1.組成原理比體系結構更偏向於硬體或者實現
2.IEEE754
float,1,8,32,階數偏移127(也就是實際範圍是-127~128)和一般的移碼偏移2^n不同,尾數是原碼
double,1,11,52
3.原碼和補碼運算
a.移位
邏輯移位,符號位不特殊對待
算數移位,符號位特殊對待
迴圈移位
例子:
| (右移2位) | (左移2位) | |
| 原數 | 1000000000000000 | 1000000000000000 |
| 邏輯移位 | 0010000000000000 | 0000000000000000 |
| 算術移位 | 1110000000000000 | 1000000000000000 |
b.溢位判斷
一個符號位:倆個同號數相加,若結果符號變換,則為溢位
兩個符號位:結果的兩個符號位不同,則為溢位
兩者等價,還有一種比較符號位進位和最高位進位的方法,不過該方法和2等價,只是不同的表述而已。
c.乘法
原碼乘法:
符號位異或,去掉符號位的運算同手工
補碼乘法:
可以當初無符號數,按手工演算法算
也可以按照Booth演算法(該演算法在乘數中有連續的1時,比較有效,其實該方法也可以用在原碼乘法中)
d.除法
原碼除法:
恢復餘數:符號位異或,其他位手工
不恢復餘數
補碼除法:
同不恢復餘數發,只是上商時,0還是1,有些變化(其實也和原碼運算一樣,和除數同號上1,不同號上0)
4.浮點加減
a.對階
b.位數求和
c.規格化(尾數“溢位”右規,階碼溢位才是真的溢位)
1.cpu和指令集
1.1定址方式,主要是基址定址和變址定址【9】
變址定址,是把在指令字中給出的一個數值(稱為變址偏移量)與一個被稱為變址暫存器的內容相加之和作為運算元的地址,用於讀寫儲存器。
基地址定址,是指把在程式中所用的地址與一個特定的暫存器(稱為基地址暫存器)的內容相加之和作為運算元的地址或指令的地址。兩者相似,但使用上有差別。
基址定址:其中的形式地址是可變的,基址暫存器的內容是一定的
變址定址:形式地址不變,變址暫存器的內容可變 因此它可用於處理陣列問題
1.2指令週期
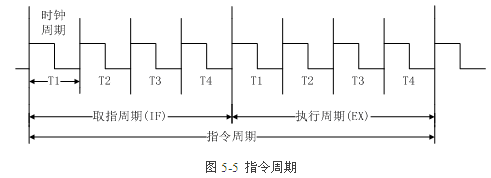
1.3硬佈線和微程式控制
硬佈線:RISC,指令少,邏輯電路。
微程式控制:CISC,用微程式來執行指令。
1.4流水和資料相關
資料相關(寫後讀(Read-After-Write,RAW)相關、讀後寫(Write-After-Read,WAR)相關、寫後寫(Write-After-Write,WAW)
資源相關(同時使用硬碟?)
控制相關(跳轉分支,if...else...)
靜態流水線:同一時間內,多功能結構只能按一種功能的連線方式工作。
動態流水線:同一時間內,可以有多種功能的連線方式同時工作。
2.儲存
0.準備
存取時間和存取週期
存取時間是執行一次讀操作或寫操作的時間,分為讀出時間和寫入時間。
讀出時間為從主存接收到有效地址到資料穩定為止的時間;
寫入時間是從主存接收到有效地址開始到資料寫入被寫單元為止的時間。
存取週期是指儲存器進行兩次連續獨立的讀或寫操作所需的最小的時間間隔。
通常,存取週期大於存取時間。
1.cache
a.直接相連,全相聯,組相聯【3】
為了能理解得更加透徹,把儲存器比作一家大超市,超市裡面的東西就是一個個位元組或者資料。為了讓好吃好玩受歡迎的東西能夠容易被看到,超市可以將這些東西集中在一塊放在一個專門的推薦櫃檯中,這個櫃檯就是快取。如果僅僅是把這些貨物放在櫃檯中即完事,那麼這種就是完全關聯的方式。可是如果想尋找自己想要的東西,還得在這些推薦貨物中尋找,而且由於位置不定,甚至可能把整個推薦櫃檯尋找個遍,這樣的效率無疑還是不高的。於是超市老總決定採用另一種方式,即將所有推薦貨物分為許多類別,如“果醬餅乾”,“巧克力餅乾”,“核桃牛奶”等,櫃檯的每一層存放一種貨物。這就是直接關聯的訪問原理。這樣的好處是容易讓顧客有的放矢,尋找更快捷,更有效。但這種方法還是有其缺點,那就是如果需要果醬餅乾的顧客很多,需要巧克力餅乾的顧客相對較少,顯然對果醬餅乾的需求量會遠多於對巧克力餅乾的需求量,可是放置兩種餅乾的空間是一樣大的,於是可能出現這種情況:存放的果醬餅乾的空間遠不能滿足市場需求的數量,而巧克力餅乾的存放空間卻被閒置。為了克服這個弊病,老闆決定改進存貨方法:還是將貨物分類存放,不過分類方法有所變化,按“餅乾”,“牛奶”,“果汁”等類別存貨,也就是說,無論是什麼餅乾都能存入“ 餅乾”所用空間中,這種方法顯然提高了空間利用的充分性,讓儲存以及查詢方法更有彈性。
b.替換演算法【4】
隨機
先進先出
最近不經常使用:
LFU演算法認為應將一段時間內被訪問次數最少的那行資料換出。為此,每行設定一個計數器。新行建立後從0開始計數,每訪問一次,被訪問行的計數器增1。當需要替換時,對這些特定行的計數值進行比較,將計數值最小的行換出,同時將這些特定行的計數器都清零。這種演算法將計數週期限定在對這些特定行兩次替換之間的間隔內,因而不能嚴格反映近期訪問情況。
LRU:
LRU演算法將近期內長時間未被訪問過的行換出。為此,每行也設定一個計數器,但它們是Cache每命中一次,命中行計數器清零,其他各行計數器增1。當需要替換時,比較各特定行的計數值,將計數值最大的行換出。這種演算法保護了剛複製到Cache中的新資料行,符合Cache工作原理,因而使Cache有較高的命中率。
c.寫回和寫分配
全寫法:cache和記憶體同時寫入。非寫分配:寫資料,cache未命中,直接寫記憶體,不把資料調入記憶體。
寫回法:只寫入cache。要有標誌位,資料被替換時,寫回記憶體,存在衝突的風險。寫分配:寫資料,cache未命中,資料調入記憶體。
2.虛擬儲存器
a. 頁【5】,段【6】,段頁【7】
去看百度百科。。。
b.快表TLB【8】
聯想暫存器
TLB和CPU裡的一級、二級快取之間不存在本質的區別,只不過前者快取頁表資料,而後兩個快取實際資料。
3.匯流排
1.匯流排仲裁【11】
分佈:分散式總裁有些像計算機網路
集中:鏈式查詢,計時器查詢,獨立請求
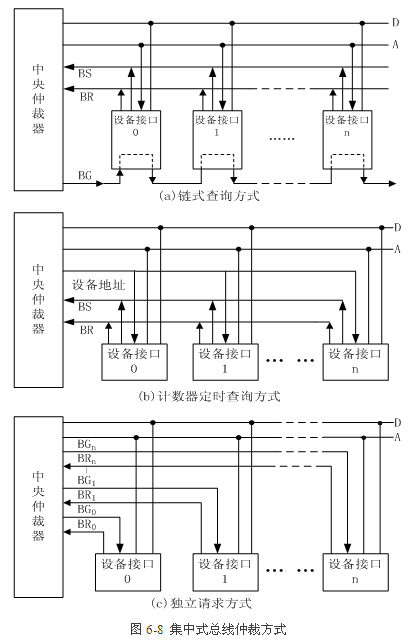
2.匯流排操作和定時【12】【13】(不同領域,同步和非同步指的東西好像是不同的)
同步:
非同步:不互鎖,半互鎖,全互鎖【14】
半同步:
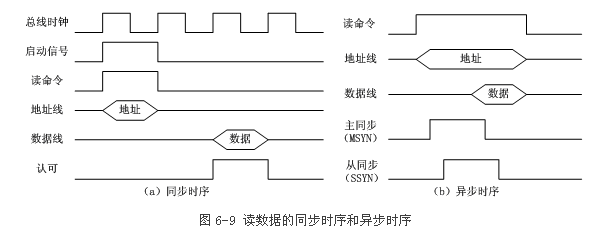
同步和非同步的區別:同步需要時鐘訊號,在時鐘上升沿或下降沿傳送的訊號才有效?
也就是說,verilog寫cpu的時候,如果用時鐘訊號和計數器相結合,片內匯流排就用的是同步通訊?
計算機網路上,傳輸的訊號中沒有時鐘訊號,所以肯定是非同步通訊?
4.IO
4.0.磁碟地址
驅動器號::柱面(磁軌)號::盤面號::扇區號
4.1中斷和程式查詢
4.2.中斷
4.1.1內部中斷,外部中斷
4.1.2中斷和響應,是否開中斷,指令執行週期結束響應
4.1.3中斷處理過程,多重中斷,遮蔽字(對應位為1則被遮蔽),
4.3.DMA
cpu預處理,設定IO裝置和DMA
外設準備好後,DMA控制器向cpu申請匯流排使用許可權(DMA請求)
DMA傳輸結束,向cpu發出中斷訊號
4.4通道
附:
1.Booth 乘法原理【1】
考慮一個由若干個 0 包圍著若干個 1 的正的二進位制乘數,比如 00111110,積可以表達為:

其中,M 代表被乘數。變形為下式可以使運算次數可以減為兩次:

事實上,任何二進位制數中連續的 1 可以被分解為兩個二進位制數之差:

因此,我們可以用更簡單的運算來替換原數中連續為 1 的數字的乘法,通過加上乘數,對部分積進行移位運算,最後再將之從乘數中減去。它利用了我們在針對為零的位做乘法時,不需要做其他運算,只需移位這一特點,這很像我們在做和 99 的乘法時利用 99 = 100 − 1 這一性質。 這種模式可以擴充套件應用於任何一串數字中連續為 1 的部分(包括只有一個 1 的情況)。那麼,


布斯演算法遵從這種模式,它在遇到一串數字中的第一組從 0 到 1 的變化時(即遇到 01 時)執行加法,在遇到這一串連續 1 的尾部時(即遇到 10 時)執行減法。這在乘數為負時同樣有效。當乘數中的連續 1 比較多時(形成比較長的 1 串時),布斯演算法較一般的乘法演算法執行的加減法運算少。
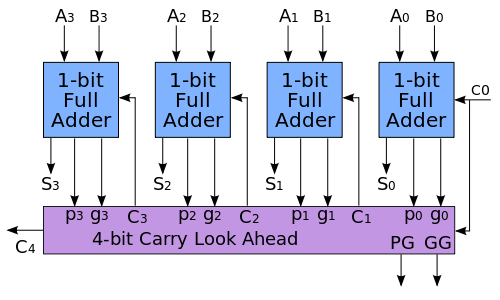
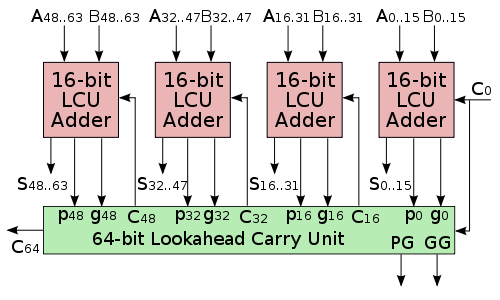
2.並行進位加法器【2】為了減少多位二進位制數加減計算所需的時間,工程師設計了一種比脈動進位加法器速度更快的加法器電路,這種加法器被稱為“超前進位加法器(carry-lookahead adder)”。
下面簡述超前進位加法器的主要原理。[6][1]:255-262我們先來考慮構成多位加法器的單個全加器從其低一位獲得的進位訊號 ,我們可以將它變換為
,我們可以將它變換為 。現在為二級制數的每一位構建兩個新訊號:
。現在為二級制數的每一位構建兩個新訊號:
- 生成(Generate)訊號:

- 傳輸(Propagate)訊號:

於是,某位全加器從低一位獲得的進位可以表示為 ,例如次低位全加器從最低位獲得的進位為
,例如次低位全加器從最低位獲得的進位為 ,而從最低位開始第三位的那個全加器獲得的進位訊號則為
,而從最低位開始第三位的那個全加器獲得的進位訊號則為 。在多位脈動進位加法器中,C2必須連線到低一位的進位輸出訊號,如果使用這種方式構成多位全加器,則邏輯閘的延遲會發生累加,導致降低電路的計算效率下降。超前進位加法器採取的方式是,將C1的邏輯函式代入到C2,即
。在多位脈動進位加法器中,C2必須連線到低一位的進位輸出訊號,如果使用這種方式構成多位全加器,則邏輯閘的延遲會發生累加,導致降低電路的計算效率下降。超前進位加法器採取的方式是,將C1的邏輯函式代入到C2,即 ,於是,這一位的進位輸出就只取決於x1、y1、x0、y0、c0幾個訊號,而這幾個訊號都是計算電路外部的已知訊號,而非低一位的計算結果。上面考慮的是從最低位開始第三位的情況。採用類似的代入方法,可以用各位的生成訊號Gi、傳輸訊號Pi,以及最低位從外部獲取的進位訊號C0來表示多位全加器的所有進位訊號。
,於是,這一位的進位輸出就只取決於x1、y1、x0、y0、c0幾個訊號,而這幾個訊號都是計算電路外部的已知訊號,而非低一位的計算結果。上面考慮的是從最低位開始第三位的情況。採用類似的代入方法,可以用各位的生成訊號Gi、傳輸訊號Pi,以及最低位從外部獲取的進位訊號C0來表示多位全加器的所有進位訊號。
通過列出多位加法器各位的進位輸出,可以發現高位的進位輸出表達式(積之和式)涉及的變數更多,對應的邏輯電路連線會變得更復雜,而且在實際應用中會遭遇邏輯閘的扇入問題。因此有必要對位數過高的全加器進行邏輯劃分,如將六十四位全加器分為四個十六位超前進位加法器來實現(如右圖)。多位二進位制數加法器的標準晶片通常具有超前進位的組成形式,例如7400系列的7483、74283晶片
3.流水【10】
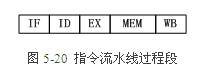
3.1.指令流水線過程段
圖5-20表示流水CPU中一個指令週期的任務分解。假設指令週期包含取指令(IF)、指令譯碼(ID)、指令執行(EX)、訪存取數(MEM)、結果寫回(WB)5個子過程(過程段),流水線由這5個串聯的過程段組成,各個過程段之間設有高速緩衝暫存器,以暫時儲存上一過程段子任務處理的結果,在統一的時鐘訊號控制下,資料從一個過程段流向相鄰的過程段。
3.2.非流水計算機工作方式
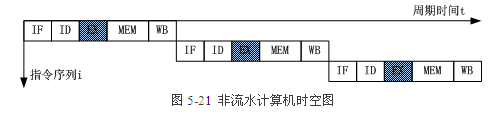
對於非流水計算機而言,上一條指令的5個子過程全部執行完畢後才能開始下一條指令,每隔5個時鐘週期才有一個輸出結果。因此,圖5-21中用了15個時鐘週期才完成3條指令,每條指令平均用時5個時鐘週期。
非流水線工作方式的控制比較簡單,但部件的利用率較低,系統工作速度較慢。
3.3.標量流水計算機工作方式
標量(Scalar)流水計算機是隻有一條指令流水線的計算機。
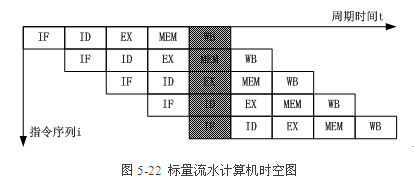
對標量流水計算機而言,上一條指令與下一條指令的5個子過程在時間上可以重疊執行,當流水線滿載時,每一個時鐘週期就可以輸出一個結果。因此,圖5-22中僅用了9個時鐘週期就完成了5條指令,每條指令平均用時1.8個時鐘週期。
採用標量流水線工作方式,雖然每條指令的執行時間並未縮短,但CPU執行指令的總體速度卻能成倍提高。當然,作為速度提高的代價,需要增加部分硬體才能實現標量流水。
3.4.超標量流水計算機工作方式
一般的流水計算機因只有一條指令流水線,所以稱為標量流水計算機。所謂超標量(Superscalar)流水計算機,是指它具有兩條以上的指令流水線。圖5-23表示超標量流水計算機的時空圖。

當流水線滿載時,每一個時鐘週期可以執行2條以上的指令。因此,圖5-23中僅用了9個時鐘週期就完成了10條指令,每條指令平均用時0.9個時鐘週期。
超標量流水計算機是時間並行技術和空間並行技術的綜合應用。
參考資料:
【01】http://zh.wikipedia.org/wiki/%E5%B8%83%E6%96%AF%E4%B9%98%E6%B3%95%E7%AE%97%E6%B3%95
【02】http://zh.wikipedia.org/wiki/%E5%8A%A0%E6%B3%95%E5%99%A8
【03】http://baike.baidu.com/view/907.htm
【04】http://baike.baidu.com/view/3871278.htm
【05】http://baike.baidu.com/view/3224034.htm
【06】http://baike.baidu.com/view/3227088.htm
【07】http://baike.baidu.com/view/3227786.htm
【08】http://baike.baidu.com/view/129737.htm
【09】http://cop.cjlu.edu.cn/forum.php?mod=viewthread&tid=197
【10】http://share.onlinesjtu.com/mod/tab/view.php?id=300
【11】http://share.onlinesjtu.com/mod/tab/view.php?id=258
【12】http://share.onlinesjtu.com/mod/tab/view.php?id=259
【13】http://bbs.csdn.net/topics/370019505
【14】http://blog.csdn.net/ce123_zhouwei/article/details/6933329