
深度動態序列人臉表情識別——論文筆記
人臉表情識別分為動態序列識別和靜態圖片識別,本文只與動態序列有關
這裡也有一篇推送解析的這篇文章,但是不全,很多提到的文章沒有翻譯,不過只作為概覽的話倒是可以
深度學習 + 動態序列人臉表情識別綜述
研究背景與意義
人臉表情識別已經成為一個人機互動領域的研究熱點,涉及到心理學、統計學、生物學、計算機學等學科,是一個比較新穎並且有研究前景的方向。應用可以推廣到疲勞駕駛監督、人機互動、醫療、安全等領域。
例如在智慧商場領域,通過攝像頭捕獲顧客,分析其面部表情解讀出顧客的情緒資訊,用於分析顧客在商場的體驗滿意度;商品推薦系統可以參考人們在瀏覽各類商品時的表情進行 分析並進而判斷其喜愛程度,將喜愛程度值加入推薦系統以便向消費者推薦更受 歡迎的商品。人機互動中機器人也可通過使用者面部表情來判斷使用者的情緒和心理,做到人性化服務;在公共安全領域,視訊巡檢時發現情緒波動物件,會給予危險級別警示,提前排除隱患,識別幼兒情緒變化,辨別是否存在誘拐行為,及時保護無行為能力的人。在智慧交通領域,面部表情識別系統能分析駕駛人是否疲勞駕駛,自動報警提示駕駛人休息;通過採集駕駛人聲音的語速和麵部表情判斷是否酒後駕駛,自動在交警系統中報警。在醫療領域,表情分析可作為輔助手段幫助醫生對病人的精神狀態、心理狀態做出分析,提高診斷的準確率。在刑事犯罪領域,通過對嫌疑人表情資訊、肢體語言的分析,可以進行測謊判別、嫌疑人分析等。
心理學家Mehrabiadu指出在人們交流過程中,面部表情傳達了55%的有用資訊,佔感情資訊總量的一半以上。1971年Ekman提出7種最基本的表情,分別是高興、悲傷、驚訝、生氣、厭惡、恐懼和中性。近年來由於深度學習超強的特徵學習能力,大量基於深度學習的人臉表情識別方法被提出。
人臉表情識別步驟
人臉表情識別主要步驟有三步:預處理、人臉表情特徵學習和特徵分類。

人臉表情識別一般步驟
預處理
人臉對齊
拿到訓練資料後,第一步是檢測人臉,然後去掉背景和無關區域。Viola-Jones 人臉檢測器是一個經典的廣泛使用的人臉檢測方法,在許多工具箱中都有實現(例如 OpenCV 和 Matlab)。得到人臉邊界框後,原影象可以裁剪至面部區域。人臉檢測之後,可以利用人臉關鍵點標定進一步提高 FER 的效果。根據關鍵點座標,人臉可以由放射變換顯示到統一的預定義模版上,減少旋轉和麵部變形帶來的變化。目前最常用的人臉標定方法是 IntraFace,在許多深度 FER 中得到了應用。該方法使用級聯人臉關鍵點定位,即 SDM,可以準確預測 49 個關鍵點。部分研究用到了MoT(mixtures of trees)結構模型來找特徵點位置。近來,深度學習方法如多工級聯卷積網路MTCNN在人臉對齊點表現優越。為了在複雜環境下實現更好的人臉對齊,Yu將三個探測子:JDA探測子、DCNN探測子和MoT探測子結合來相互補償。
資料增強
深度神經網路需要足夠的訓練資料才能保證在給定識別任務上的泛化效能。然而用於 FER 的公開資料庫一邊都達不到這樣的訓練資料量,因此資料增強就成了深度表情識別系統非常重要的一個步驟。資料增強可以分為兩類:線下資料增強和線上資料增強。
深度 FER 的線下資料增強主要是通過一些影象處理操作來擴充資料庫。最常用的方法包括隨機干擾和變形,例如旋轉、水平翻轉、縮放等。這些處理可以生成更多的訓練樣本,從而讓網路對出現偏移和旋轉的人臉更健壯。除了基本的影象操作,也可以利用 CNN 或 GAN 來生成更多的訓練資料。
線上資料增強方法一般都整合在深度學習工具箱中,來降低過擬合的影響。在訓練過程中,輸入樣本會被隨機中心裁剪,並且水平翻轉,得到比原訓練資料庫大 10 倍的資料庫。
人臉歸一化
光照和頭部姿態變化會有損 FER 的表現,因此我們介紹兩類人臉歸一化方法來減輕這一影響:光照歸一化和姿態歸一化。
光照歸一化:INFace 工具箱是目前最常用的光照歸一化工具。研究表明直方圖均衡化結合光照歸一化技巧可以得到更好的人臉識別準確率。光照歸一化方法主要有三種:基於各向同性擴散歸一化(isotropic diffusion-basednormalization)、基於離散餘弦變換歸一化(DCT-based normalization)和高斯差分(DoG)。
姿態歸一化:一些 FER 研究利用姿態歸一化產生正面人臉視角,其中最常用的方法是 Hassner 等人提出的:在標定人臉關鍵點之後,生成一個 3D 紋理參考模型,然後估測人臉部件,隨後,通過將輸入人臉反投影到參考座標系上,生成初始正面人臉。最近,也有一系列基於生成式對抗網路GAN 的深度模型用於生成正面人臉(FF-GAN,TP-GAN,DR-GAN)。
人臉表情特徵學習
卷積神經網路CNN
CNN 對人臉位置變化和尺度變化有更強的健壯性,而且對於未見人臉姿態變化比多層感知器有更好的表現。
深度置信網路DBN
DBN 由 Hinton 等人提出,可學習提取訓練資料的深度層級表示。DBN 訓練有兩個步驟:預訓練和微調。首先用逐層貪婪訓練方法初始化深度網路,可以在不需要大量標註資料的情況下防止區域性最優解。然後,用有監督的梯度下降對網路的引數和輸出進行微調。
深度自編碼器DAE
深度自編碼器通過最小化重構誤差來對輸入進行重構。DAE 有許多變體:降噪自編碼器,可從部分損壞的資料中恢復原始未損壞資料;稀疏自編碼網路,增強學習得到的特徵表示的稀疏性;壓縮式自編碼器,增加活動相關正則項以提取區域性不變特徵;卷積自編碼器,使用卷積層代替 DAE 中的隱藏層。
遞迴神經網路RNN
RNN 是聯結主義模型,能夠捕捉時域資訊,更適合於序列資料預測。訓練 RNN 用到的是時間反向傳播演算法BPTT。由 Hochreiter 和 Schmidhuber 提出的 LSTM 是一種特殊形式的 RNN,用於解決傳統 RNN 訓練時出現的梯度消失和爆炸問題。
人臉表情分類
在學習深度特徵之後,FER 的最後一步是識別測試人臉的表情屬於基本表情的哪一類。深度神經網路可以端到端地進行人臉表情識別。一種方法是在網路的末端加上損失層,來修正反向傳播誤差,每個樣本的預測概率可以直接從網路中輸出。另一種方法是利用深度神經網路作為提取特徵的工具,然後再用傳統的分類器,例如 SVM 和隨機森林,對提取的特徵進行分類。
人臉表情資料集(視訊序列)
Database | Samples | Subjects | 來源 | Elicit | Expression distribution |
CK+ | 593 | 123 | 實驗室 | 擺拍 自然 | 7種+恥辱 |
MMI | 2900videos | 25 | 實驗室 | 擺拍 | 7種 |
AFEW 7.0 | 1809 | 電影 | 擺拍、自然 | 7種 | |
Oulu-CASIA | 2880 | 80 | 實驗室 | 擺拍 | 6種(無中性) |
研究現狀
幀聚合
相比於靜態圖片中的表情識別,連續動態視訊序列中能包含更多的關於表情變化的微小資訊。但由於給定的視訊幀中各具有不同的表情強度,直接測量目標資料集中的每幀誤差不能產生令人滿意的效果,很多方法用於聚合每個序列的網路輸出幀,以實質上改善 FER 效能。我們將這些方法分為兩類:決策層幀聚合和特徵層幀聚合。
決策層幀聚合:
Kahou等人提出一種決策層幀聚合,將所有幀的n-class概率向量聯結成一個序列,構造一個n*10的特徵向量用於後續分類。因為序列有不同幀數,按照圖示方法提出兩種聚合方法。

如圖,(a)對於超過 10 幀的序列,將總幀數按時間分為 10 個獨立幀組,將其概率向量平均。(b)對於少於 10 幀的序列,通過均勻重複幀,將序列擴張至 10 個幀。
特徵層幀聚合:
Liu等人提取了給定序列的影象特徵,然後應用了三個模型:特徵向量(線性子空間),協方差矩陣,和多維高斯分佈。Bargal提出了統計(STAT)編碼模型來計算並聯結所有幀的特徵維度的平均值、方差、最小值、最大值。

Bargal論文中網路特徵層幀聚合
為了改善STAT編碼,Knyazev等首次移除最大值特徵,然後計算並平均每幀的特徵變化,最後計算平均每個神經元的一維傅立葉特徵變換來加入光譜特徵。
表情強度網路
Zhao等人提出了峰值引導的深度網路(PPDN),用於強度不變的表情識別。PPDN 將來自同一個人的一對峰值和非峰值的同類表情影象作為輸入,然後利用 L2 範數損失來最小化兩張圖片之間的距離。作者用峰值梯度抑制(PGS)作為反向傳播機制,用非峰值表情的特徵逼近峰值表情的特徵。同時在 L2 範數最小化中忽略峰值表情的梯度資訊來避免反轉。

Zhao提出的PPDN網路。訓練時,PPDN聯合優化兩幅表情圖片的L2 範數損失和交叉熵損失來訓練。測試時,PPDN使用一副靜態圖片作為輸入來預測。
Kim利用一個序列中五種不同強度級別((onset,onset to apex transition, apex, apex to offset transition andoffset)使用五個損失函式來調整空間特徵學習,其中兩個損失函式被用來較少表情分類錯誤和類間表情變化。為了表達連續時間內的表情變化,兩個損失函式用來減少強度分類錯誤和類間強度變化,這樣每類表情包含不同強度的聚類。為了保持強度的連貫,一個損失函式用來編碼中間強度。Kim同時提出了一個卷積編碼-解碼網路來產生參考臉,結合contrastive metric loss 和 reconstruction loss來為不同目標濾除無關資訊。
深度空間 - 時間 FER 網路
時空 FER 網路將一個時間視窗中的一系列幀作為表情強度未知的輸入,並利用影象序列中的紋理資訊和時間依賴性進行更細微的表情識別。
RNN + C3D:
Graves首次將雙向LSTM用於提取3D人臉模型中的人臉表情。C3D是用權重能由時間軸分享的3D卷積核而不是傳統的2D核,廣泛用於動態人臉表情識別來抓取時空特徵。Liu 等人提出的 3DCNN-DAP 模型。輸入 n 幀序列與 3D 濾波器做卷積,13*c*k 部分濾波器對應 13 個人為定義的面部區域,用於卷積 k 個特徵圖,生成 c 個表情類別對應的面部活動區域檢測圖。
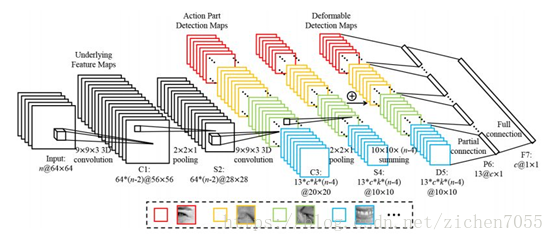
Liu提出的3DCNN-DAP模型
面部關鍵點軌跡:
心理學研究表明主要面部(眼睛、鼻子、嘴巴)的動態變化包含最多表情的描述資訊,因此提出面部關鍵點軌跡來捕捉連續序列中面部的動態變化。
Jung將卷積神經網路與深度神經網路結合起來形成新的DTAGN網路,卷積神經網路基於影象序列訓練,深度神經網路基於時間的面部標誌點訓練,聯合訓練 DTAN(屬於“RNN-C3D”)和 DTGA(“屬於面部關鍵點軌跡”),最後將兩個網路提取的面部特徵點結合成一個一維軌跡向量,輸入到分類器中進行表情識別。Yan受這個方法的啟發,通過將序列中所有幀的歸一化軌跡特徵作為CNN的輸入一起來提取特徵,使用雙向RNN學習時序相關性。Hasani用人臉特徵點和殘差單元的輸入向量的乘積結合軌跡特徵來代替原始的3D Inception-ResNet網路的殘差單元,最後與LSTM單元級聯。

Jung提出的聯合微調方法DTAGN網路
Zhang提出了時域網路 PHRNN 用於關鍵點追蹤,來分析表情序列,提取了表情從開始到結束的三幀序列(onset、apex、offset), 將人臉影象不做分割直接放入網路中,提取眉毛、眼睛、鼻子、嘴巴的特徵點分別放入四個子網中提取低層特徵,在上層網路中融合成高層特徵訓練,並結合空域網路 MSCNN (多訊號卷積網路)用於身份不變特徵,對面部表情的識別訊號和驗證訊號來增加不同表情間的差異而減少身份資訊的差異,使訓練出來的特徵與表情相關,與人的性別、年齡無關。兩個網路分別訓練後進行概率融合來識別表情。
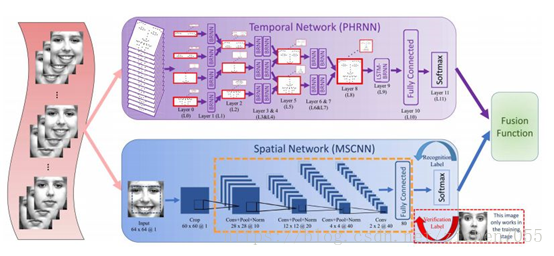
Zhang提出的PHRNN + MSCNN
級聯網路:先提取特徵,然後將特徵輸入到時序網路(如LSTM)中。
Baccouche提出了一種卷積稀疏自動編碼來非監督的提取稀疏並平移不變的特徵,然後訓練LSTM分類器用於學習特徵的時間演變。Ouyang提出一種更靈活的網路ResNet-LSTM,允許低層CNN網路中的節點直接與LSTM相連來捕捉時空資訊。除將LSTM與CNN全連線層相連,Kankanamge提出將CNN最後一層卷積層的特徵直接輸入到LSTM中獲取長範圍的相關,不損失全域性相關性。
網路整合:訓練多個時空特徵網路,最後將各個網路的輸出融合。
Simonyan等人提出將雙流 CNN 用於視訊動作識別,其中一個 CNN 網路用於提取視訊幀光流資訊,另一個 CNN 用於提取靜止影象的表面資訊,然後將兩個網路的輸出融合。該網路結構對 FER 領域也有所啟發。Sun提出一個多通道網路從表情臉提取空間資訊,從中性到表情的變化間提取時間資訊即光流,並研究了三種特徵融合策略:score average fusion, SVM-basedfusion 和 neural-network-based fusion.
困難與挑戰
由於 FER 研究將其主要關注點轉移到具有挑戰性的真實場景條件下,許多研究人員利用深度學習技術來解決這些困難,如光照變化、遮擋、非正面頭部姿勢、身份偏差和低強度表情識別。Ranzato提出了一個深度生成模型,使用mPoT作為深度置信網路DBN的第一層來模擬畫素級表示,然後訓練DBN給輸入分配合適的畫素分佈,遮擋的畫素可以被使用條件分佈序列重建的第一層畫素表示來填滿。He採用熱紅外線影象來消除光照影響進行人臉表情識別。
考慮到 FER 是一個數據驅動的任務,並且訓練一個足夠深的網路需要大量的訓練資料,深度 FER 系統面臨的主要挑戰是在質量和數量方面都缺乏訓練資料。
由於不同年齡、文化和性別的人以不同的方式做出面部表情,因此理想的面部表情資料集應該包括豐富的具有精確面部屬性標籤的樣本影象,不僅僅是表情,還有其他屬性,例如年齡、性別、種族,這將有助於跨年齡、跨性別和跨文化的深度 FER 相關研究。另一方面,對大量複雜的自然場景影象進行精準標註是構建表情資料庫一個明顯的障礙。合理的方法是在專家指導下進行可靠的眾包,或者可以用專家修正過的全自動標註工具提供大致準確的標註。
需要考慮的另一個主要問題是,儘管目前表情識別技術已經被廣泛研究,但是我們所定義的表情只涵蓋了特定種類的一小部分,而不能代表現實互動中人類可以做出的所有表情。目前有兩個新的模型可以用來描述更多的情緒:FACS 模型,通過結合不同的面部肌肉活動單元來描述面部表情的可視變化;維度模型提出了兩個連續值的變數,即評價值和喚起程度(Valence-arousal),連續編碼情緒強度的微小變化。
除此之外,不同的資料庫之間的偏差和表情類別的不平衡分佈是深度 FER 領域中要解決的另外兩個問題。對於資料庫之間的偏差問題,可以用深度域適應和知識蒸餾來解決。對於表情類別不平衡問題,一種解決方案是利用資料增強和合成來平衡預處理階段中的類分佈。另一種選擇是在訓練期間給深度網路增加代價敏感的損失層。