
人臉表情識別實驗——fer2013
阿新 • • 發佈:2019-02-09
2018年7月21日22:43:57更新
轉化好的圖片資料集,百度雲分享見文章末尾。
人臉表情識別——fer2013
一、實驗概覽
第一篇文獻中有網路結構圖,但根據我做實驗的情況來看,這篇論文水分較大,達不到論文中所說的分類精度。第二篇內容比第一篇詳細很多,很值得參考。
二、實驗過程
1、準備資料集
下載fer2013之後,解壓出的是csv格式的資料,我們需要先將資料轉換成圖片。
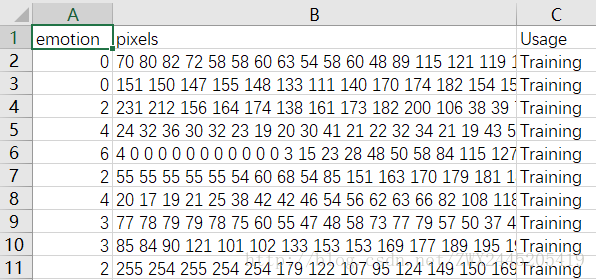
step 1: 從fer2013.csv中提取出訓練集、驗證集和測試集
convert_fer2013.py:
# -*- coding: utf-8 -*- 注意:在Windows平臺中,需要在csv.writer()中加上lineterminator='\n'不然在生存的csv檔案中,每行之間會有空行,影響後續操作。在Linux平臺中不需要這樣做。
step 2: 將csv中的資料轉化成圖片

convert_csv2gray:
# -*- coding: utf-8 -*-
import csv
import os
from PIL import Image
import numpy as np
datasets_path = r'.\datasets'
train_csv = os.path.join(datasets_path, 'train.csv')
val_csv = os.path.join(datasets_path, 'val.csv')
test_csv = os.path.join(datasets_path, 'test.csv')
train_set = os.path.join(datasets_path, 'train')
val_set = os.path.join(datasets_path, 'val')
test_set = os.path.join(datasets_path, 'test')
for save_path, csv_file in [(train_set, train_csv), (val_set, val_csv), (test_set, test_csv)]:
if not os.path.exists(save_path):
os.makedirs(save_path)
num = 1
with open(csv_file) as f:
csvr = csv.reader(f)
header = next(csvr)
for i, (label, pixel) in enumerate(csvr):
pixel = np.asarray([float(p) for p in pixel.split()]).reshape(48, 48)
subfolder = os.path.join(save_path, label)
if not os.path.exists(subfolder):
os.makedirs(subfolder)
im = Image.fromarray(pixel).convert('L')
image_name = os.path.join(subfolder, '{:05d}.jpg'.format(i))
print(image_name)
im.save(image_name)
生成的資料集目錄結構如下:
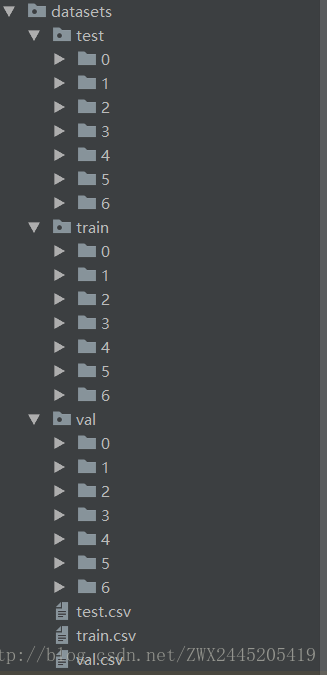
2、訓練網路
- 網路結構如下:

我在網路中的每一層後面都加入了BN,這樣訓練速度和效果都有提升,80次迭代的測試集acc=0.615
2. 程式碼如下:
# -*- coding: utf-8 -*-
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
import os
from torchvision import datasets, transforms
import time
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(42),
transforms.RandomHorizontalFlip(),
transforms.Grayscale(),
transforms.ToTensor(),
# transforms.Normalize()
]),
'test': transforms.Compose([
# transforms.Resize(256),
transforms.CenterCrop(42),
transforms.Grayscale(),
transforms.ToTensor(),
# transforms.Normalize()
])
}
data_dir = r".\datasets"
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'test']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=32, shuffle=True, num_workers=4)
for x in ['train', 'test']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'test']}
class_names = image_datasets['train'].classes
use_gpu = torch.cuda.is_available()
def imshow(inp, title=None):
inp = inp.numpy().transpose(1, 2, 0)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(10)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.bn_x = nn.BatchNorm2d(1)
self.conv1 = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=5, stride=1, padding=2)
self.bn_conv1 = nn.BatchNorm2d(32, momentum=0.5)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=32, kernel_size=4, stride=1, padding=1)
self.bn_conv2 = nn.BatchNorm2d(32, momentum=0.5)
self.conv3 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2)
self.bn_conv3 = nn.BatchNorm2d(64, momentum=0.5)
self.fc1 = nn.Linear(in_features=5 * 5 * 64, out_features=2048)
self.bn_fc1 = nn.BatchNorm1d(2048, momentum=0.5)
self.fc2 = nn.Linear(in_features=2048, out_features=1024)
self.bn_fc2 = nn.BatchNorm1d(1024, momentum=0.5)
self.fc3 = nn.Linear(in_features=1024, out_features=7)
def forward(self, x):
x = self.bn_x(x)
x = F.max_pool2d(F.tanh(self.bn_conv1(self.conv1(x))), kernel_size=3, stride=2, ceil_mode=True)
x = F.max_pool2d(F.tanh(self.bn_conv2(self.conv2(x))), kernel_size=3, stride=2, ceil_mode=True)
x = F.max_pool2d(F.tanh(self.bn_conv3(self.conv3(x))), kernel_size=3, stride=2, ceil_mode=True)
x = x.view(-1, self.num_flat_features(x))
x = F.tanh(self.bn_fc1(self.fc1(x)))
x = F.dropout(x, training=self.training, p=0.4)
x = F.tanh(self.bn_fc2(self.fc2(x)))
x = F.dropout(x, training=self.training, p=0.4)
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
def test_model():
inputs, labels = next(iter(dataloaders['train']))
print(inputs.size())
if use_gpu:
inputs, labels = Variable(inputs.cuda()), Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
# out = torchvision.utils.make_grid(inputs)
#
# imshow(out, title=[class_names[x] for x in classes])
model = Model()
if use_gpu:
model = model.cuda()
print(model)
outputs = model(inputs)
print(outputs)
def train_model(model, criterion, optimizer, num_epochs=25):
since = time.time()
best_model_wts = model.state_dict()
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
for phase in ['train', 'test']:
if phase == 'train':
# scheduler.step()
model.train(True)
else:
model.train(False)
running_loss = 0.0
running_corrects = 0
for data in dataloaders[phase]:
inputs, labels = data
if use_gpu:
inputs, labels = Variable(inputs.cuda()), Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
optimizer.zero_grad()
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.data[0]
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
if phase == 'test' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = model.state_dict()
print()
time_elapsed = time.time() - since
print('Training complete in {:0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best test Acc: {:4f}'.format(best_acc))
model.load_state_dict(best_model_wts)
torch.save(model, 'best_model.pkl')
torch.save(model.state_dict(), 'model_params.pkl')
if __name__ == '__main__':
# test_model()
model = Model()
if use_gpu:
model = model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
train_model(model, criterion, optimizer, num_epochs=100)
實驗未最終完成,後面再補充。