
Hadoop資料型別講解
序列化
所謂序列化(serialization),是指將結構化物件轉化為位元組流,以便在網路上傳輸或寫到磁碟進行永久儲存。反序列化(deserialization)是指將位元組流轉回結構化物件的過程。
序列化在分散式資料處理的兩大領域經常出現:程序間通訊和永久儲存。
在Hadoop中,系統中多個節點上程序間的通訊是通過“遠端過程呼叫”(RPC)實現的。RPC協議將訊息序列化成二進位制流後傳送到遠端節點,遠端節點接著將二進位制流反序列化為原始訊息。
Hadoop使用自己的序列化格式Writable,它格式緊湊,速度快,但很難用Java以外的語言進行擴充套件或使用。因為Writable是Hadoop的核心(大多數MapReduce程式都會為鍵和值使用它)。
資料型別
資料型別都實現Writable介面,以便用這些型別定義的資料可以被序列化進行網路傳輸和檔案傳輸。
基本資料型別
BooleanWritable:標準布林型數值 ByteWritable:單位元組數值
DoubleWritable:雙位元組數值 FloatWritable:浮點型
IntWritable:整形數 LongWritable:長整數型
實現介面的問題
1)在Hadoop中所有的Key/Value型別必須實現Writable介面,有兩個方法,分別用於讀(反序列化)和寫(序列化)。
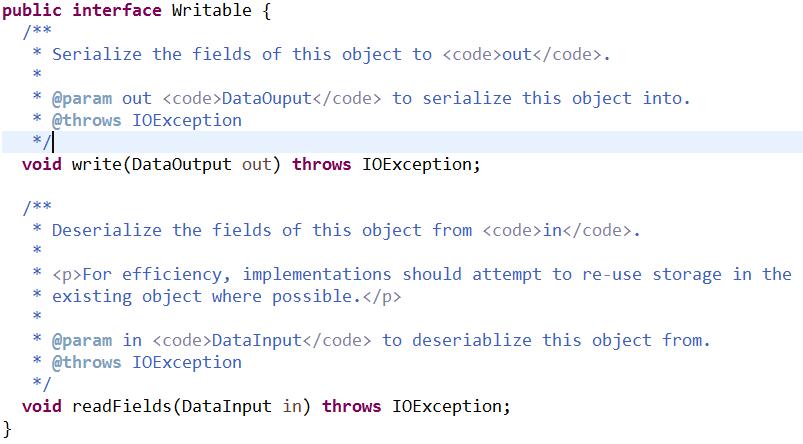
2)所有的key,必須實現Comparable介面,在MapReduce過程中需要對key/value對進行反覆的排序,預設情況下依據key進行排序,我們要實現compara To()方法。所以,通過key既要實現Writable介面,又要實現Comparable介面。Hadoop中提供了一個公共的介面 WritableComparable 。
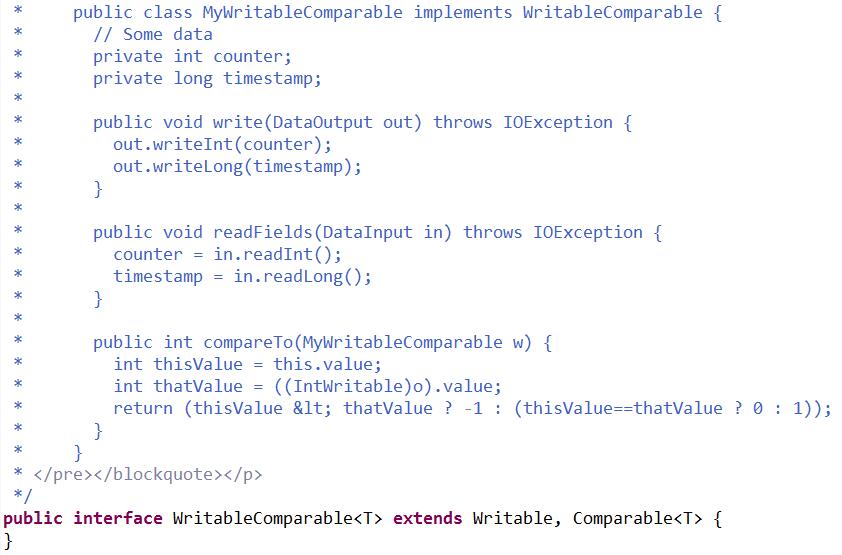
3)由於需要序列化、反序列化、比較,對Java物件需要重寫以下幾個方法:
I,equals()
II,hashCode()
III,toString()
4)資料型別,必須有一個預設的無參構造方法,為了方便反射,進行建立物件。
5)在自定義資料型別中,建議使用Java原生資料型別,最好不要使用Hadoop對原生型別封裝好的資料型別。
RawComparator
對MapReduce來說,型別的比較是非常重要的,因為中間有個基於鍵的排序階段,hadoop提供的一個優化介面是繼承自Java Comparator的RawComparator介面:
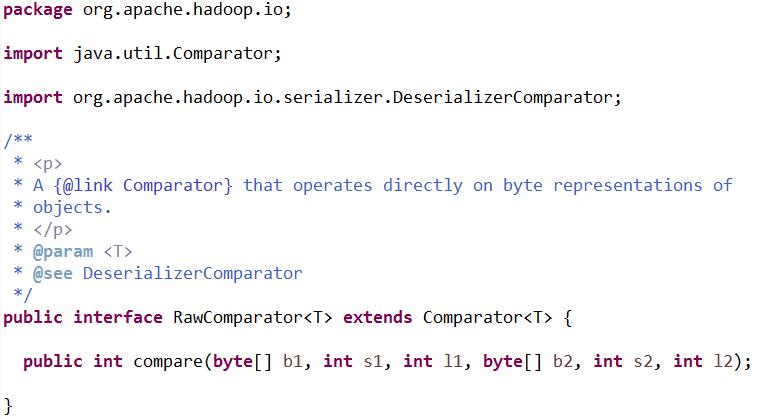
該介面允許其實現直接比較資料流中的記錄,無需先把資料流反序列化成物件(比如,一開始資料流就是陣列,那麼可以直接用來比較),這樣便避免了新建物件的額外開銷。例如,我們根據IntWritable介面實現的comparator實現了compare()方法,該方法可以從每個位元組陣列b1和b2中讀取給定起始位置(s1和s2)以及長度(l1和l2)的一個整數進而直接比較。
自定義Comparator類
在Hadoop中有一個針對Writable資料型別,進行實現的一個通用實現類WritableComparator類。所有的資料型別,只需要繼承通用類,再根據需要的具體功能複寫相應的compare()方法。
對於自定義Comparator類,需要以下幾步:
1)推薦Comparator類定義在資料型別內部,靜態內部類,實現WritableComaprator類。
2)重寫預設無參構造方法,方法內必須呼叫父類有參構造方法。
3)過載父類的compare()方法,依據具體功能進行復寫。
4)向WritableComparator類中註冊自定義的Comparator類
涉及的介面與類
WritableComparator
WritableComparator是對繼承自WritableComparable類的RawComparator類的一個通用實現。它提供兩個主要功能,第一,它提供了對原始compare()方法的一個預設實現,該方法能夠反序列化將在流中進行比較的物件,並呼叫物件的compare()方法。第二,它充當是RawComparator例項的工廠(已註冊Writable的實現)。
NullWritable
NullWritable是Writable的一個特殊型別,它的序列化長度為0,它並不從資料流中讀取資料,也不寫入資料。它充當佔位符,例如:在mapReduce中,如果你不需要使用鍵或值,就可以將鍵或值宣告為NullWritable——結果是儲存常量空值,如果希望儲存一系列數值,與鍵/值對相對,NullWritable也可以用作在SequenceFile中的鍵。它是一個不可變的單例項型別:通過呼叫NullWritable.get()方法可以獲取這個例項。
ObjectWritable and GenericWritable
ObjectWritable是對Java基本型別(String,enum,Writable,null或這些型別組成的陣列)的一個通用封裝。它在Hadoop RPC中用於對方法的引數和返回值型別進行封裝和解封裝。
當一個欄位中包含多個型別時,ObjectWritable是非常實用的,例如:如果SequenceFile中的值包含多個型別,就可以將值型別宣告為ObjectWritable,並將每個型別封裝在一個ObjectWritable中。作為一個通用的機制,每次序列化都寫封裝型別的名稱,這非常浪費空間。如果封裝的型別數量比較少並且能夠提前知道,那麼可以通過使用靜態型別的陣列,並使用對序列化後的型別的引用加入位置索引提高效能。這是GenericWritable類採取的方法,並且你可以在繼承的子類中指定需要支援的型別。