hadoop shell命令操作
先看我伺服器情況:
shizhan01有 ResourceManager 和 NameNode
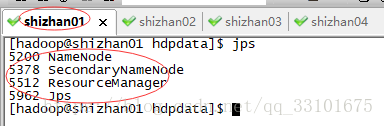
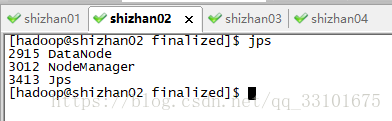
shizhan02 03 04裡是我的 NodeManager 和 DataNode
訪問 http://shizhan01:50070
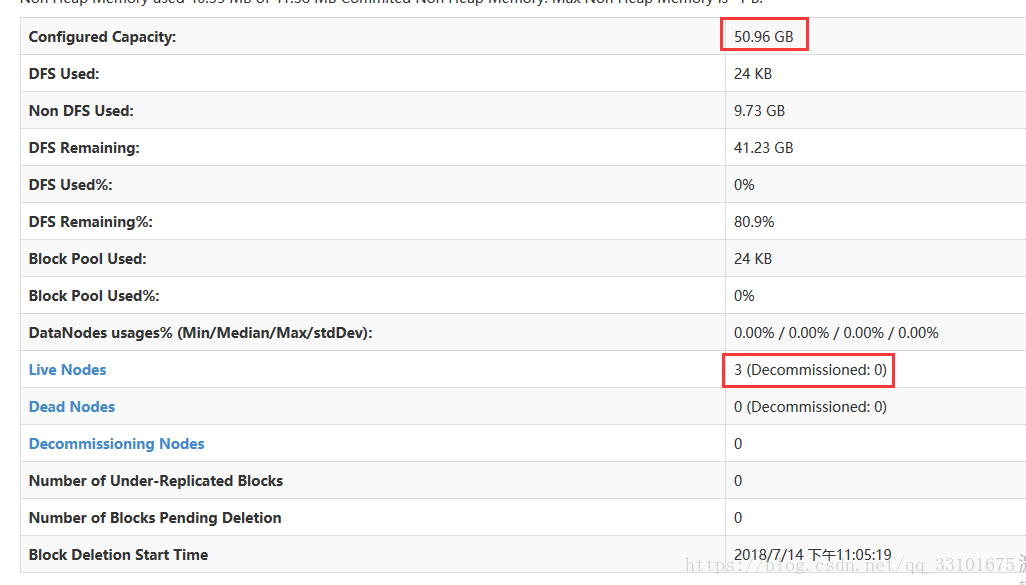
DataNode是存放資料的,hdfs把我的資料都存成兩份(我們在hdfs-site.xml裡配置的是2),如果資料太大
超過128M時,hdfs就會把我的資料給拆開,按偏移量0-128M的存一份,剩下的存一份。
我們來複現一下這個理論。
先看一下hdfs的根目錄有哪些東西,執行
hadoop fs -ls /
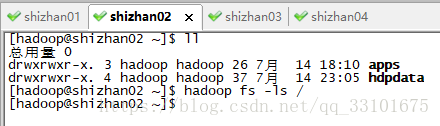
可以看到啥都沒有,那我們在shizhan02上上傳一下檔案
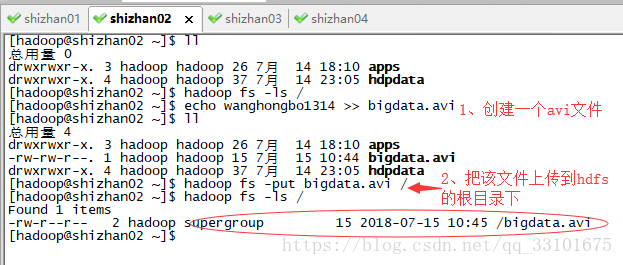
我們建立了一個檔案,把他上傳到hdfs根目錄,然後ls可以看到檔案
當然我們看 圖形介面的客戶端,也能看到我們上傳的 bigdata.avi 檔案,看下圖
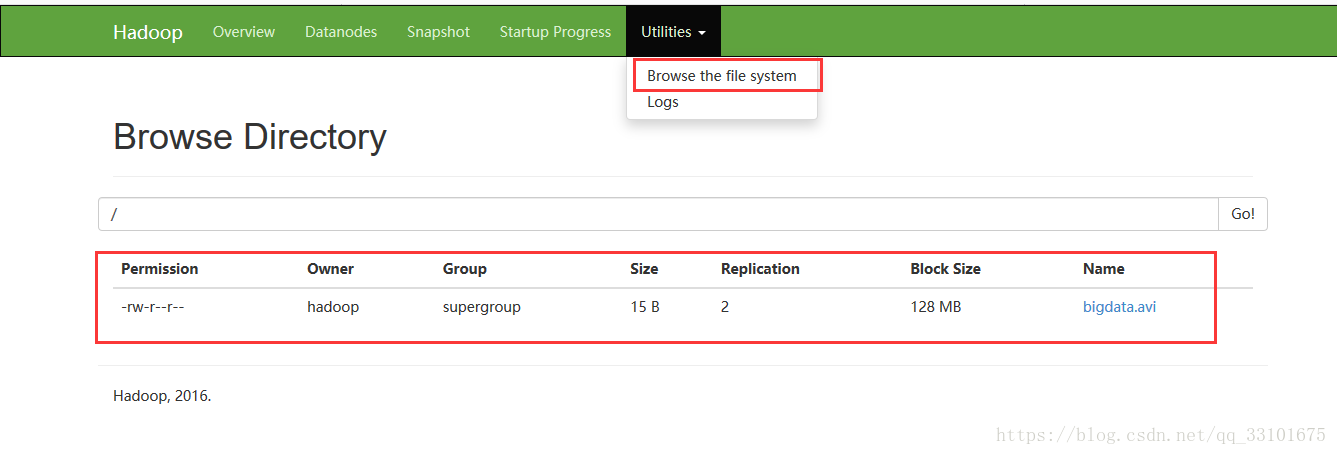
其實我們把檔案上傳到hdfs,hdfs就會把我們的檔案 重新命名,存到兩個地方;
也就是說我們把現在的bigdata刪除也沒事,因為hdfs已經把檔案存起來了。
那存到了什麼地方呢?

這個是我們之前在core-site.xml 裡配的hadoop.tmp.dir目錄
hdfs把我們的bigdata.avi檔案重新命名成 blk_1073741825(塊_id),放在這個目錄下
/home/hadoop/hdpdata/dfs/data/current/BP-1186906364-192.168.116.128-1531575944333/current/finalized/subdir0/subdir0
那因為是存兩份,我們再去其他伺服器裡找下
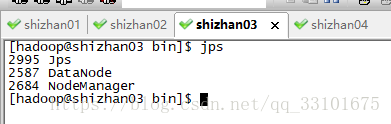
shizhan03 裡沒有

shizhan04裡有

那這就驗證了我們上面說的,hdfs把我們的檔案重新命名,存了兩份,分別在兩臺伺服器上。
那我們再來驗證下當檔案超過128M了之後的情況:
我在發現shizhan01伺服器上有個hadoop的安裝包 超過了128M
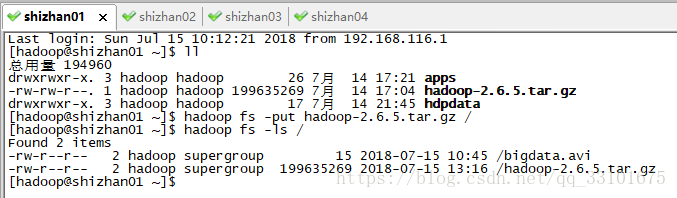
那我們就把這個安裝包上傳到hdfs裡
圖形介面裡也能看到
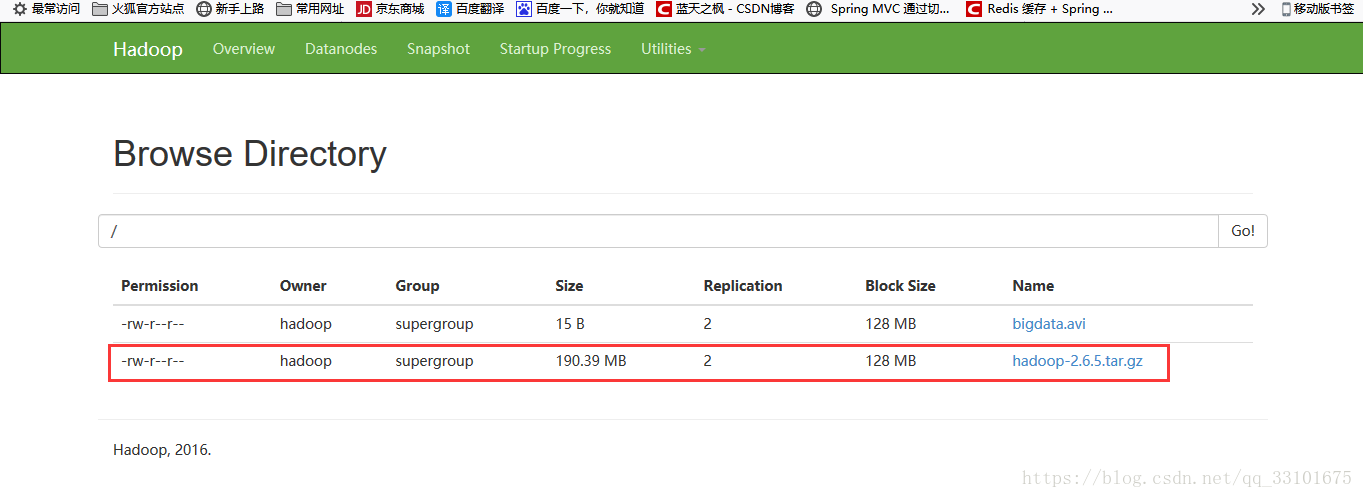
因為超過了128M,所以檔案是被hdfs拆分了,我們來找一下
shizhan02上

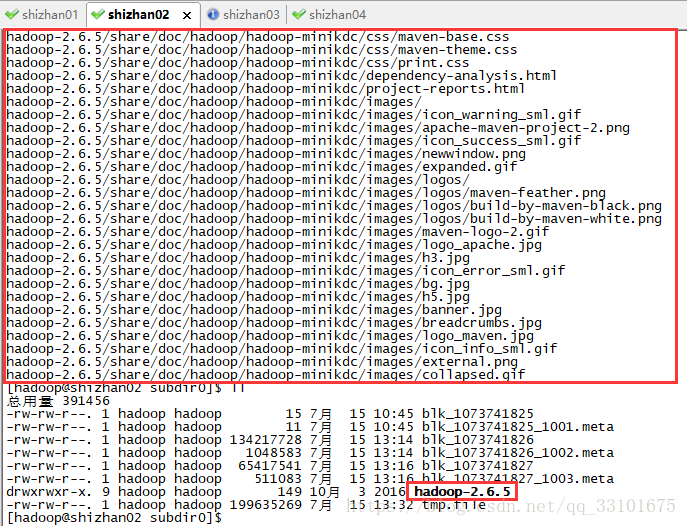
blk_1073741825是我們之前上傳的bigdata檔案,下面的26 27是我們上傳的hadoop安裝包,因為大於128M,
所以被拆分成兩個檔案
由下圖可知,副本被存在了shizhan03上

那shizhan04上,肯定就不會有啦,看下圖,25是我們之前存的 bigdata檔案

既然hadoop的安裝包上傳到hdfs裡,由於大於128M導致被拆分,那如果我們把拆分的檔案合起來,還能解壓嘛?
我們來試一下,我們把26 和27檔案都追加到一個 tmp.file檔案裡,最後看這個tmp.file檔案能否被解壓
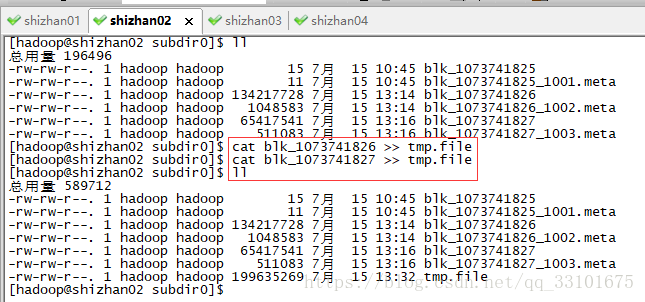
解壓 tmp.file檔案,發現是可以解壓的