
值得一提:關於 HDFS 的 file size 和 block size
一個常被問到的一個問題是: 如果一個HDFS上的檔案大小(file size) 小於塊大小(block size) ,那麼HDFS會實際佔用Linux file system的多大空間?
答案是實際的檔案大小,而非一個塊的大小。下面做一個實驗:
1、往hdfs裡面新增新檔案前,hadoop在linux上面所佔的空間為 464 MB:

2、往hdfs裡面新增大小為2673375 byte(大概2.5 MB)的檔案:
2673375 derby.jar
3、此時,hadoop在linux上面所佔的空間為 467 MB——增加了一個實際檔案大小(2.5 MB)的空間,而非一個block size(128 MB)

4、使用hadoop dfs -stat檢視檔案資訊:

這裡就很清楚地反映出: 檔案的實際大小(file size)是2673375 byte, 但它的block size是128 MB。
5、通過NameNode的web console來檢視檔案資訊:
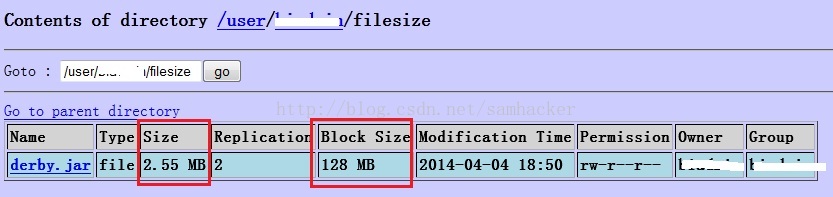
結果是一樣的: 檔案的實際大小(file size)是2673375 byte, 但它的block size是128 MB。
6、不過使用‘hadoop fsck’檢視檔案資訊,看出了一些不一樣的內容—— ‘1(avg.block size 2673375 B)’:
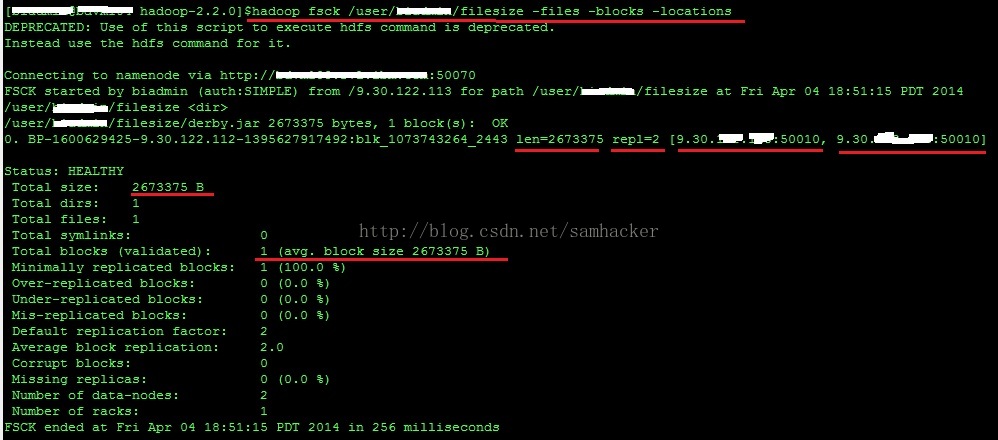
值得注意的是,結果中有一個 ‘1(avg.block size 2673375 B)’的字樣。這裡的 'block size' 並不是指平常說的檔案塊大小(Block Size)—— 後者是一個元資料的概念,相反它反映的是檔案的實際大小(file size)。以下是Hadoop Community的專家給我的回覆:
“The fsck is showing you an "average blocksize", not the block size metadata attribute of the file like stat shows. In this specific case, the average is just the length of your file, which is lesser than one whole block.”
最後一個問題是: 如果hdfs佔用Linux file system的磁碟空間按實際檔案大小算,那麼這個”塊大小“有必要存在嗎?
其實塊大小還是必要的,一個顯而易見的作用就是當檔案通過append操作不斷增長的過程中,可以通過來block size決定何時split檔案。以下是Hadoop Community的專家給我的回覆:
“The block size is a meta attribute. If you append tothe file later, it still needs to know when to split further - so it keeps that value as a mere metadata it can use to advise itself on write boundaries.”