
python中使用k-means對鳶尾花資料集聚類
阿新 • • 發佈:2019-01-28
程式碼和結果:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
X = iris.data[:, 2:4] ##表示我們只取特徵空間中的後兩個維度
print(X.shape)
#繪製資料分佈圖
plt.scatter(X[:, 0], X[:, 1], c = "red", marker='o', label='see')
plt.xlabel('petal length')
plt.ylabel('petal width' 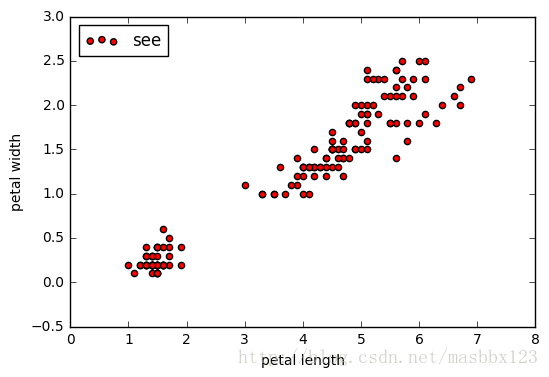
estimator = KMeans(n_clusters=3)#構造聚類器
estimator.fit(X)#聚類
label_pred = estimator.labels_ #獲取聚類標籤
#繪製k-means結果
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
plt.scatter(x0[:, 0], x0[:, 1], c = "red", marker='o', label='label0')
plt.scatter(x1[:, 0 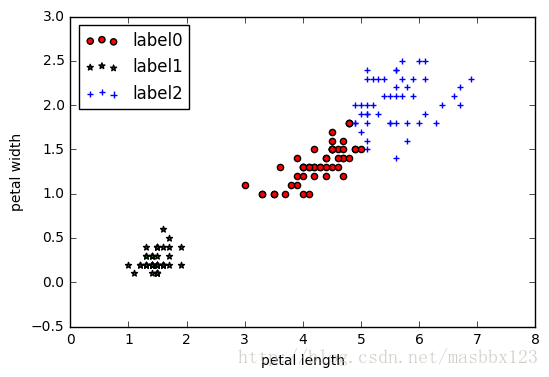
光看這2個特徵,那聚類算是非常完美了