
Sunday演算法---簡單高效的字串匹配演算法
說到字串匹配演算法,估計大夥立馬就想到了KMP演算法,誰讓KMP這麼經典呢,各種演算法教材裡必然有KMP啊。但是KMP演算法太複雜了,求next崩潰到cry。難道就沒有比KMP更簡單更高效的演算法,no,有的,這就是本文要說的Sunday演算法。KMP演算法是個70後,Sunday演算法是正宗的90後,哈哈。
演算法慢的主要原因就是無謂的重複操作太多,像暴力查詢子串這種就是。
而Sunday演算法用了一種很聰明的方法,儘可能的跳過更多的不可能匹配的位置。
先不講原理,直接從例子看:
文字串S如下

模式串T如下
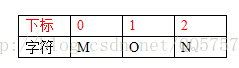
期望從S中找到T的位置。
設有指向文字串S的遊標i,指向模式串T的遊標j。初始i = 0, j = 0
1:i = 0, j= 0
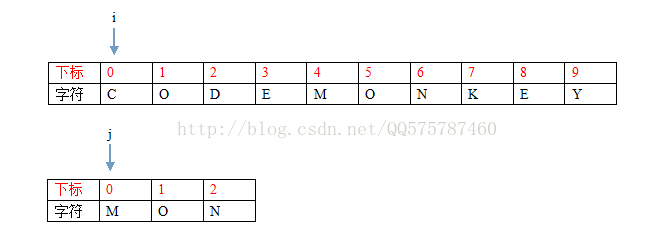
S[i] != T[j], 所以需要向右移動i然後重新和T的開頭匹配,那麼我們移動多少個字元呢?
現在讓我們腦洞大開,從S和T在當前位置末尾對齊的下一個位置看起,也就是目前的S[3]位置,S[3] = E。
開始向右移動T。
---->移動一個字元,S[3]和T[2]對齊,
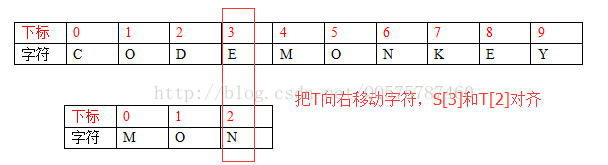
明顯這個位置是不可能匹配成功的,因為S[3] != T[2]。
---->移動兩個字元,S[3]和T[1]對齊。
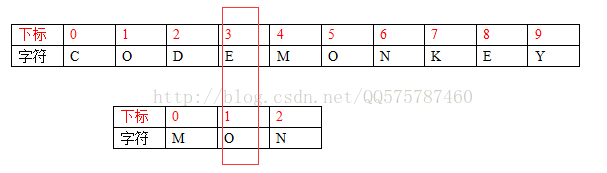
同理,這也不可能匹配成功。
---->移動三個字元,S[3]和T[0]對齊。
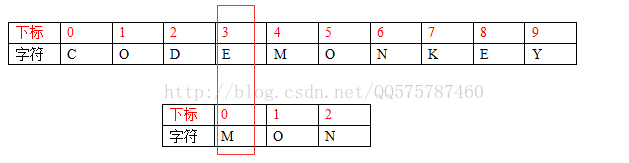
同理,這也不可能匹配成功。
是不是稍微有點感覺了,好,現在來稍微總結下思路。
當在位置i(S的遊標),j(T的遊標)不匹配時,找到對齊後的下一個位置pos的字元C,然後把T中最後一個出現字元C的位置,和S的pos位置對齊,然後重新開始驗證匹配,這樣才有可能匹配。如果T中不存在字元C,說明T的任何一個位置都不能和S的pos位置匹配,那麼只能從S的pos+1的位置開始和T[0]開始匹配了。
現在按這種方法,來演示一遍。
第一步:i = 0, j = 0
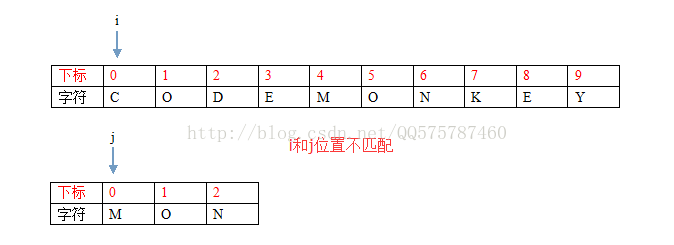
i和j的位置不匹配,找到對齊後的下一個位置pos = 3,字元為E,由於T中不存在字元E,所有設定i = 4(pos的下一個位置), j = 0(j從頭匹配)
第二步:i = 4, j = 0
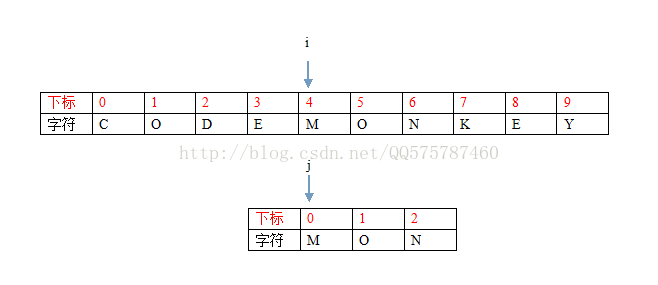
SHIT,突然發現自己選擇的例子很搞糟,直接匹配成功,所以,大夥自己親自動手比劃一下吧。