
梅爾頻率倒譜系數(MFCC) 學習筆記
最近學習音樂自動標註的過程中,看到了有關使用MFCC提取音訊特徵的內容,特地在網上找到資料,學習了一下相關內容。此筆記大部分內容摘自博文 http://blog.csdn.net/zouxy09/article/details/9156785 有小部分標註和批改時我自己加上的,以便今後查閱。
語音訊號處理之(四)梅爾頻率倒譜系數(MFCC)
在任意一個Automatic speech recognition 系統中,第一步就是提取特徵。換句話說,我們需要把音訊訊號中具有辨識性的成分提取出來,然後把其他的亂七八糟的資訊扔掉,例如背景噪聲啊,情緒啊等等。
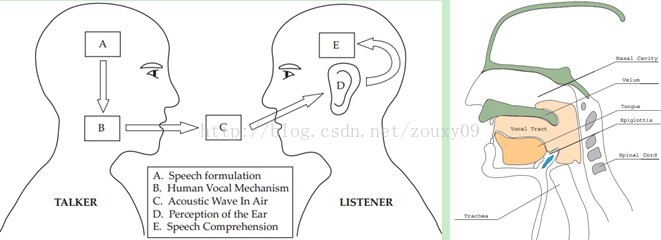
搞清語音是怎麼產生的對於我們理解語音有很大幫助。人通過聲道產生聲音,聲道的shape(形狀?)決定了發出怎樣的聲音。聲道的shape包括舌頭,牙齒等。如果我們可以準確的知道這個形狀,那麼我們就可以對產生的音素phoneme進行準確的描述。聲道的形狀在語音短時功率譜的包絡中顯示出來。而MFCCs就是一種準確描述這個包絡的一種特徵。
MFCCs(Mel Frequency Cepstral Coefficents)是一種在自動語音和說話人識別中廣泛使用的特徵。它是在1980年由Davis和Mermelstein搞出來的。從那時起。在語音識別領域,MFCCs在人工特徵方面可謂是鶴立雞群,一枝獨秀,從未被超越啊(至於說Deep Learning的特徵學習那是後話了)。
好,到這裡,我們提到了一個很重要的關鍵詞:聲道的形狀,然後知道它很重要,還知道它可以在語音短時功率譜的包絡中顯示出來。哎,那什麼是功率譜?什麼是包絡?什麼是MFCCs?它為什麼有效?如何得到?下面咱們慢慢道來。
一、聲譜圖(Spectrogram)
我們處理的是語音訊號,那麼如何去描述它很重要。因為不同的描述方式放映它不同的資訊。那怎樣的描述方式才利於我們觀測,利於我們理解呢?這裡我們先來了解一個叫聲譜圖的東西。
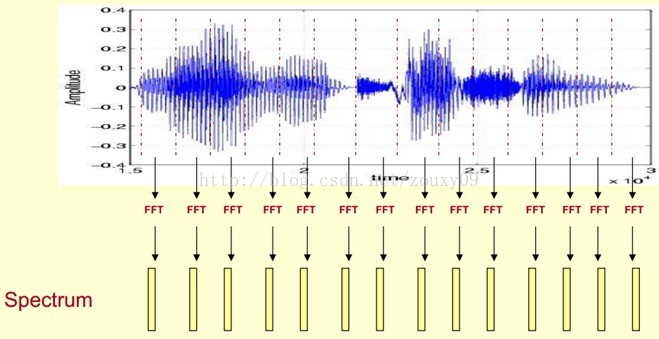
這裡,這段語音被分為很多幀,每幀語音都對應於一個頻譜(通過短時FFT計算),頻譜表示頻率與能量的關係。在實際使用中,頻譜圖有三種,即線性振幅譜、對數振幅譜、自功率譜(對數振幅譜中各譜線的振幅都作了對數計算,所以其縱座標的單位是dB(分貝)。這個變換的目的是使那些振幅較低的成分相對高振幅成分得以拉高,以便觀察掩蓋在低幅噪聲中的週期訊號)。
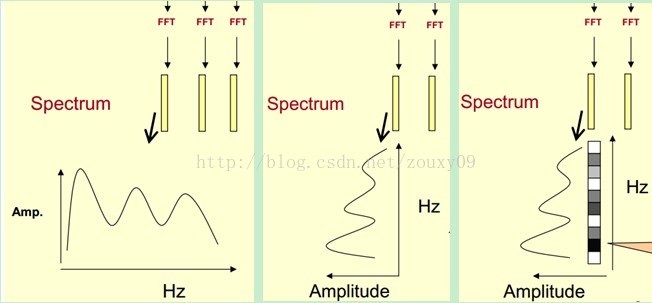
我們先將其中一幀語音的頻譜通過座標表示出來,如上圖左。現在我們將左邊的頻譜旋轉90度。得到中間的圖。然後把這些幅度對映到一個灰度級表示(也可以理解為將連續的幅度量化為256個量化值?),0表示黑,255表示白色。幅度值越大,相應的區域越黑。這樣就得到了最右邊的圖。那為什麼要這樣呢?為的是增加時間這個維度,這樣就可以顯示一段語音而不是一幀語音的頻譜,而且可以直觀的看到靜態和動態的資訊。優點稍後呈上。
這樣我們會得到一個隨著時間變化的頻譜圖,這個就是描述語音訊號的spectrogram聲譜圖。
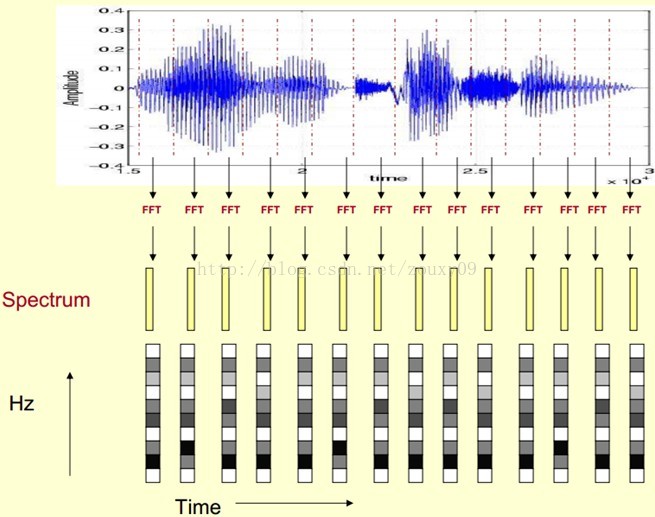
下圖是一段語音的聲譜圖,很黑的地方就是頻譜圖中的峰值(共振峰formants)。
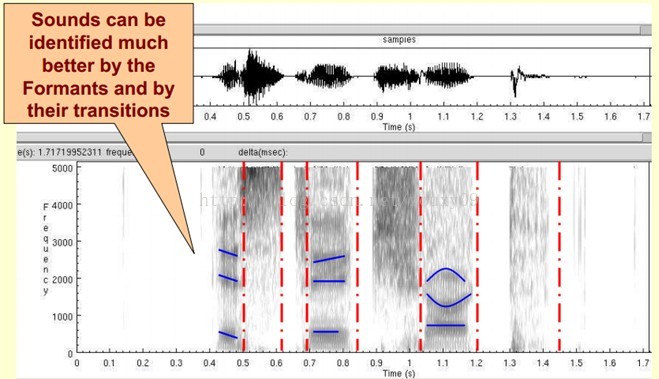
那我們為什麼要在聲譜圖中表示語音呢?
首先,音素(Phones)的屬性可以更好的在這裡面觀察出來。另外,通過觀察共振峰和它們的轉變可以更好的識別聲音。隱馬爾科夫模型(Hidden Markov Models)就是隱含地對聲譜圖進行建模以達到好的識別效能。還有一個作用就是它可以直觀的評估TTS系統(text to speech)的好壞,直接對比合成的語音和自然的語音聲譜圖的匹配度即可。
| 通過對語音進行分幀進行時頻變換,得到每一幀的FFT頻譜再將各幀頻譜按照時間順序排列起來,得到時間-頻率-能量分佈圖。很直觀的表現出語音訊號隨時間的頻率中心的變化。 |
二、倒譜分析(Cepstrum Analysis)
下面是一個語音的頻譜圖。峰值就表示語音的主要頻率成分,我們把這些峰值稱為共振峰(formants),而共振峰就是攜帶了聲音的辨識屬性(就是個人身份證一樣)。所以它特別重要。用它就可以識別不同的聲音。
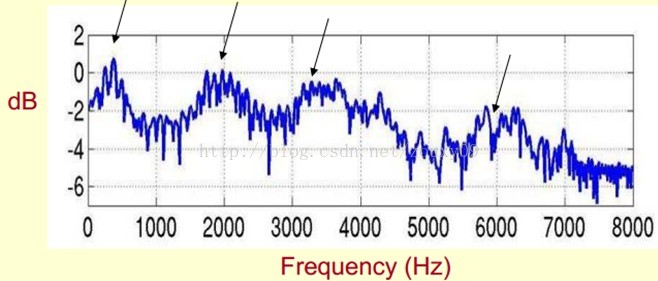
既然它那麼重要,那我們就是需要把它提取出來!我們要提取的不僅僅是共振峰的位置,還得提取它們轉變的過程。所以我們提取的是頻譜的包絡(Spectral Envelope)。這包絡就是一條連線這些共振峰點的平滑曲線。
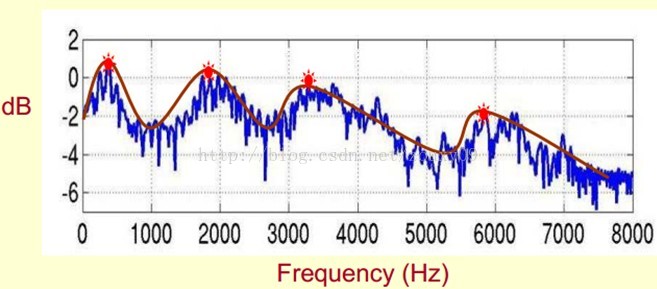
我們可以這麼理解,將原始的頻譜由兩部分組成:包絡和頻譜的細節。這裡用到的是對數頻譜,所以單位是dB。那現在我們需要把這兩部分分離開,這樣我們就可以得到包絡了。
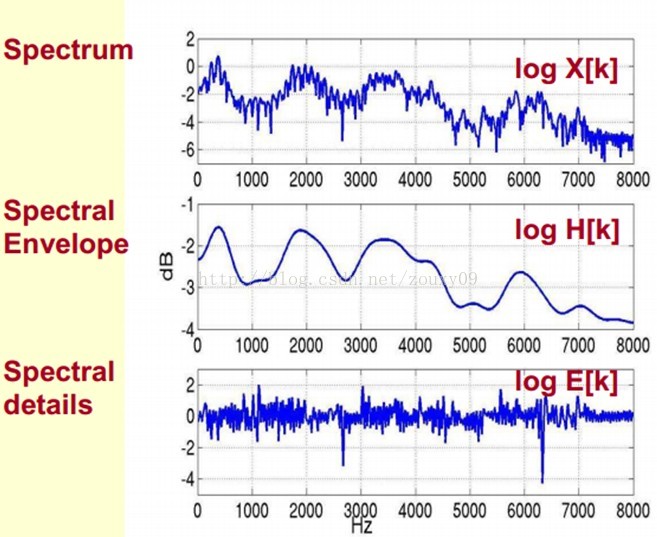
那怎麼把他們分離開呢?也就是,怎麼在給定log X[k]的基礎上,求得log H[k] 和 log E[k]以滿足log X[k] = log H[k] + log E[k]呢?
為了達到這個目標,我們需要Play a Mathematical Trick。這個Trick是什麼呢?就是對頻譜做FFT。在頻譜上做傅立葉變換就相當於逆傅立葉變換Inverse FFT (IFFT)。需要注意的一點是,我們是在頻譜的對數域上面處理的,這也屬於Trick的一部分。這時候,在對數頻譜上面做IFFT就相當於在一個偽頻率(pseudo-frequency)座標軸上面描述訊號。
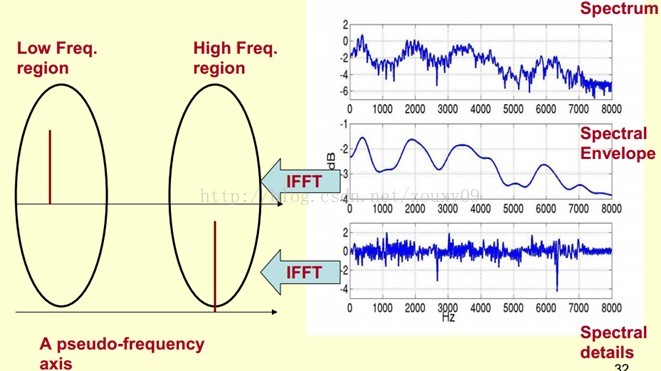
由上面這個圖我們可以看到,包絡是主要是低頻成分(這時候需要轉變思維,這時候的橫軸就不要看成是頻率了,咱們可以看成時間),我們把它看成是一個每秒4個週期的正弦訊號。這樣我們在偽座標軸上面的4Hz的地方給它一個峰值。而頻譜的細節部分主要是高頻。我們把它看成是一個每秒100個週期的正弦訊號。這樣我們在偽座標軸上面的100Hz的地方給它一個峰值。
把它倆疊加起來就是原來的頻譜訊號了。
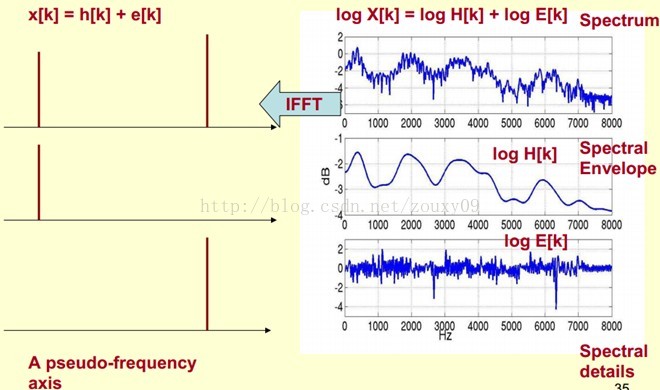
在實際中咱們已經知道log X[k],所以我們可以得到了x[k]。那麼由圖可以知道,h[k]是x[k]的低頻部分,那麼我們將x[k]通過一個低通濾波器就可以得到h[k]了!沒錯,到這裡咱們就可以將它們分離開了,得到了我們想要的h[k],也就是頻譜的包絡。
x[k]實際上就是倒譜Cepstrum(這個是一個新造出來的詞,把頻譜的單詞spectrum的前面四個字母順序倒過來就是倒譜的單詞了)。而我們所關心的h[k]就是倒譜的低頻部分。h[k]描述了頻譜的包絡,它在語音識別中被廣泛用於描述特徵。
那現在總結下倒譜分析,它實際上是這樣一個過程:
1)將原語音訊號經過傅立葉變換得到頻譜:X[k]=H[k]E[k];
只考慮幅度就是:|X[k] |=|H[k]||E[k] |;
2)我們在兩邊取對數:log||X[k] ||= log ||H[k] ||+ log ||E[k] ||。
3)再在兩邊取逆傅立葉變換得到:x[k]=h[k]+e[k]。
這實際上有個專業的名字叫做同態訊號處理。它的目的是將非線性問題轉化為線性問題的處理方法。對應上面,原來的語音訊號實際上是一個卷性訊號(聲道相當於一個線性時不變系統,聲音的產生可以理解為一個激勵通過這個系統),第一步通過卷積將其變成了乘性訊號(時域的卷積相當於頻域的乘積)。第二步通過取對數將乘性訊號轉化為加性訊號,第三步進行逆變換,使其恢復為卷性訊號。這時候,雖然前後均是時域序列,但它們所處的離散時域顯然不同,所以後者稱為倒譜頻域。
總結下,倒譜(cepstrum)就是一種訊號的傅立葉變換經對數運算後再進行傅立葉反變換得到的譜。它的計算過程如下:

以下部分還未整理
三、Mel頻率分析(Mel-Frequency Analysis)
好了,到這裡,我們先看看我們剛才做了什麼?給我們一段語音,我們可以得到了它的頻譜包絡(連線所有共振峰值點的平滑曲線)了。但是,對於人類聽覺感知的實驗表明,人類聽覺的感知只聚焦在某些特定的區域,而不是整個頻譜包絡。
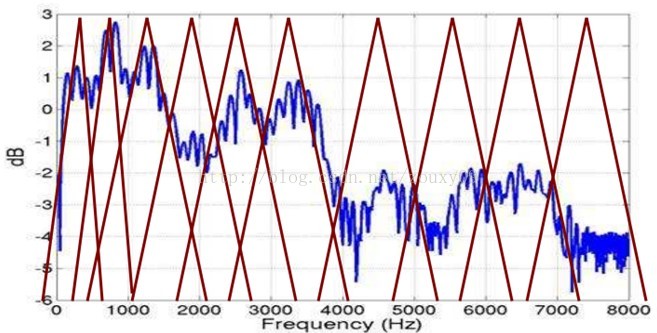
而Mel頻率分析就是基於人類聽覺感知實驗的。實驗觀測發現人耳就像一個濾波器組一樣,它只關注某些特定的頻率分量(人的聽覺對頻率是有選擇性的)。也就說,它只讓某些頻率的訊號通過,而壓根就直接無視它不想感知的某些頻率訊號。但是這些濾波器在頻率座標軸上卻不是統一分佈的,在低頻區域有很多的濾波器,他們分佈比較密集,但在高頻區域,濾波器的數目就變得比較少,分佈很稀疏。
人的聽覺系統是一個特殊的非線性系統,它響應不同頻率訊號的靈敏度是不同的。在語音特徵的提取上,人類聽覺系統做得非常好,它不僅能提取出語義資訊, 而且能提取出說話人的個人特徵,這些都是現有的語音識別系統所望塵莫及的。如果在語音識別系統中能模擬人類聽覺感知處理特點,就有可能提高語音的識別率。
梅爾頻率倒譜系數(Mel Frequency Cepstrum Coefficient, MFCC)考慮到了人類的聽覺特徵,先將線性頻譜對映到基於聽覺感知的Mel非線性頻譜中,然後轉換到倒譜上。
將普通頻率轉化到Mel頻率的公式是:
由下圖可以看到,它可以將不統一的頻率轉化為統一的頻率,也就是統一的濾波器組。
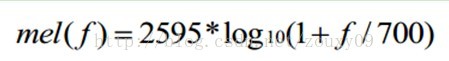
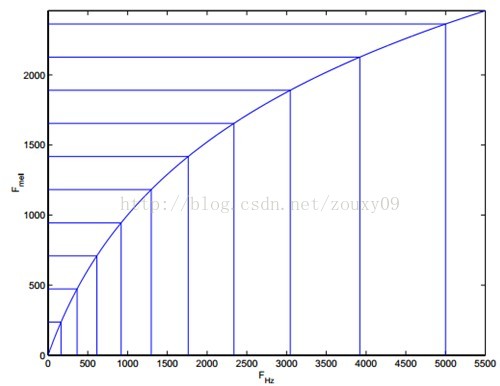
在Mel頻域內,人對音調的感知度為線性關係。舉例來說,如果兩段語音的Mel頻率相差兩倍,則人耳聽起來兩者的音調也相差兩倍。
四、Mel頻率倒譜系數(Mel-Frequency Cepstral Coefficients)
我們將頻譜通過一組Mel濾波器就得到Mel頻譜。公式表述就是:log X[k] = log (Mel-Spectrum)。這時候我們在log X[k]上進行倒譜分析:
1)取對數:log X[k] = log H[k] + log E[k]。
2)進行逆變換:x[k] = h[k] + e[k]。
在Mel頻譜上面獲得的倒譜系數h[k]就稱為Mel頻率倒譜系數,簡稱MFCC。
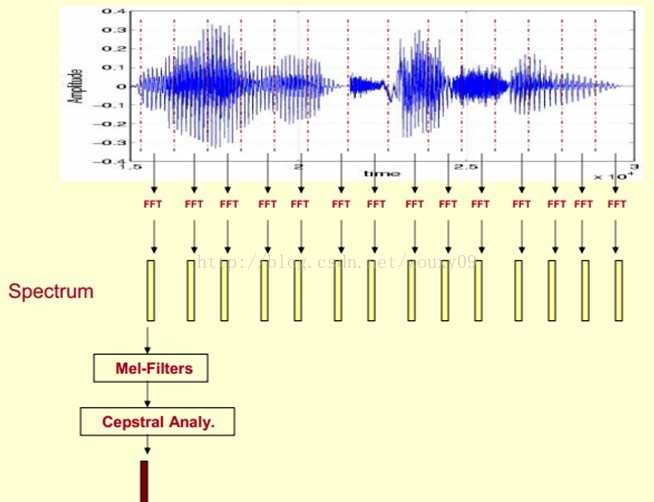
現在咱們來總結下提取MFCC特徵的過程:(具體的數學過程網上太多了,這裡就不想貼了)
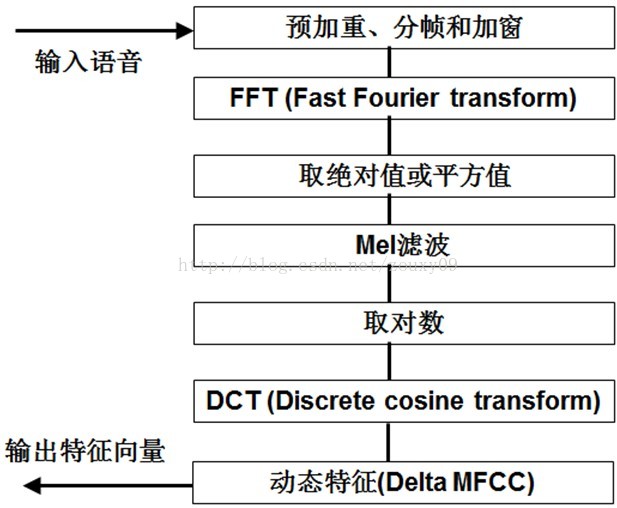
1)先對語音進行預加重、分幀和加窗;(加強語音訊號效能(信噪比,處理精度等)的一些預處理)
2)對每一個短時分析窗,通過FFT得到對應的頻譜;(獲得分佈在時間軸上不同時間窗內的頻譜)
3)將上面的頻譜通過Mel濾波器組得到Mel頻譜;(通過Mel頻譜,將線形的自然頻譜轉換為體現人類聽覺特性的Mel頻譜)
4)在Mel頻譜上面進行倒譜分析(取對數,做逆變換,實際逆變換一般是通過DCT離散餘弦變換來實現,取DCT後的第2個到第13個係數作為MFCC係數),獲得Mel頻率倒譜系數MFCC,這個MFCC就是這幀語音的特徵;(倒譜分析,獲得MFCC作為語音特徵)
這時候,語音就可以通過一系列的倒譜向量來描述了,每個向量就是每幀的MFCC特徵向量。
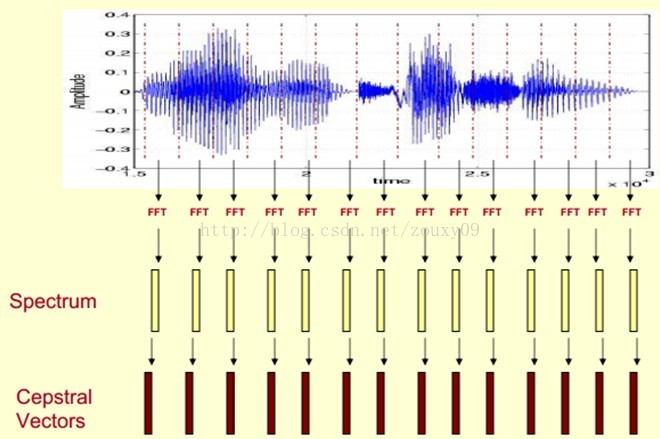
這樣就可以通過這些倒譜向量對語音分類器進行訓練和識別了。
五、參考文獻
[1]這裡面還有一個比較好的教程:
[2]本文主要參考:cmu的教程:
[3] C library for computing Mel Frequency Cepstral Coefficients (MFCC)