
我讀DenseNet
阿新 • • 發佈:2019-01-29
背景
之前聽說過DenseNet,再次被提起是因為七月初上交大主辦的SSIST 2017,Yann Lecun的一頁PPT,將其地位放置到如此之高,查了一下是CVPR 2017的一篇Oral,於是下定決心好好拜讀一下。1

文章地址:https://arxiv.org/abs/1608.06993
程式碼地址:Torch版本,TensorFlow版本,MxNet版本,Caffe版本,
方法
我們回顧一下ResNet,大意就是本層的啟用值與本層的輸入,作為本層的輸出。換一種方式理解,第
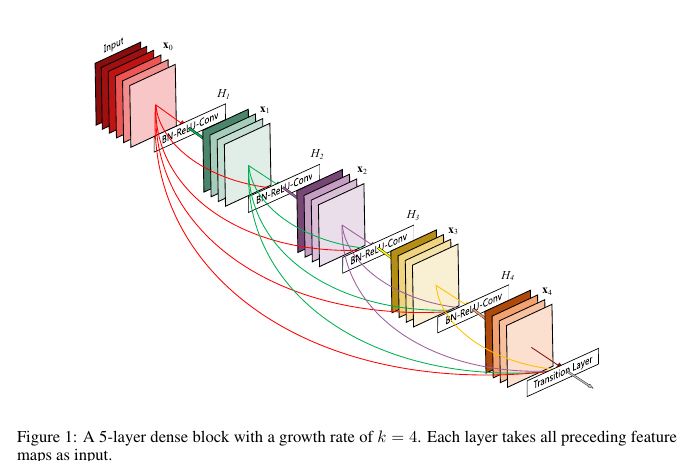
- 與傳統的卷積網路相比,需要更少的引數就能得到相同的效果。這裡指出一點,引數少並不意味計算量降低,實驗前向速度並未比ResNet降低。作者給出的原因是每層的輸入包括之前的所有層,所以可以避免傳統網路中冗餘的層;
- Densenet改變了傳統網路反向傳遞時,梯度(資訊)傳播方式,由線性變成樹狀反向,這樣的好處就在於減少了梯度消失的可能,並且加速訓練,有利於更深層網路的訓練;
- 作者發現稠密的網路結構有類似正則功能,在小資料集合上更好的避免過擬合。
實現
對於輸入影象 l(·)

作者又嘗試了
Hl(·) 是BN+ReLU+Conv(1x1)+BN+ReLU+Conv(3x3)的組合,這種網路記為Densenet-B- 假設Dense模組之間的卷積輸出channels個數是模組輸出層數的
θ 倍,如果θ<1 網路記為Densenet-C,一般我們設θ=0.5 - 同時上面兩種情況記為網路Densenet-BC
網路引數不放了,直接結果:


