
Linear Regression with multiple variables(多元變數的線性迴歸問題)
前言
這一章還是緊接上一章的內容,在上一章,我們詳細地討論了關於一個變數的線性迴歸問題,而在我們的實際問題中,一般都不止一個變數,就比如上一章討論的預測房價問題,房價不僅只跟房子的大小有關,還跟它有幾間房間,幾層樓等等有關,所以我們需要涉及到的是多元變數的問題,在這一章,我講詳細地給大家介紹多元變數地線性迴歸問題。
最後還是那句話,如果內容有什麼錯誤的理解,希望大家不吝賜教,指正,謝謝!
第三章 多元的線性迴歸問題
3.1 多元變數和單個變數的異同
在前面,我們討論的問題如圖1所示,我們對它做出假設h(x)=
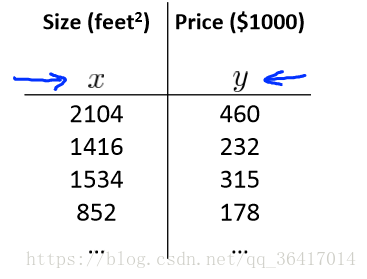
圖1 Price只和Size有關
而現在我們需要討論的問題如圖2所示,這個時候price不僅只和size有關,而和其他因素有關,所以之前我們用來假設的h(x)=就不對,這個時候我們需要重新定義一個h(x)=
,在這個表示式中,我們定義
,則h(x)=
,我們用矩陣的形式來重新整理下這個表示式,
,
,
,這個時候問題就簡單化了,我們把
看作一個整體,就是一個(n+1)*1維的一個矩陣變數,所以上式的變數就是一個
,還有之前我們需要討論的Cost Function(代價函式):J(
)=
即J()=
,Gradient descent:
(simultaneously update
,for j=0,1,2,...,n),
即
,注意
3.2 Feature Scaling(特徵的縮放)
理想的情況下,我們是希望每個feature都是在同一個scale,而實際中例如:x1=size (0-2000 feet^2),x2=number of bedrooms (1-5),這個時候J()如圖2所示,收斂會比較慢。關於這個原因是因為當一個特徵的範圍比較大時,在這個特徵求的梯度會很小,而學習速率
因為受其他特徵的約束不能設太大,所以導致J(
)收斂的速度會比較慢。

圖2 不做處理的J(
而我們如果做一下處理,進行比例的縮放,例如:,
,這個時候0<=x1<=1,0<=x2<=1,即x1、x2在同一個範圍內了,這個時候J(
)的收斂趨勢可能是如圖3所示,收斂會比較快,不會走很多的折線。

圖3 經過處理後的J()
我們所希望的是讓每個feature都大約在-1<=xi<=1範圍內,x0=1所以不需要處理,但是其實“1”這個值並不是絕對的,我們對資料進行放縮的目的是讓資料的取值範圍儘量保證在一個接近的範圍內,但也不一定要相同,比如:x1:0~3、x2:-2~0.5等等也都是可以的,不會很大程度上影響J()的收斂程度,但是如果有x3:-100~100、x4:-0.0001~0.0001,這個時候,就是不行的,這範圍相差太大,就會有影響了。
下面給大家介紹一個更加靠譜的縮放方法:Mean normalization(均值歸一化),,
即每個特徵的平均值,s即特徵值的最大值減去最小值,例如
,
,這個時候-0.5<=x1<=0.5,-0.5<=x2<=0.5。
3.3 Learning rate(學習速率)
Gradient descent:,和前一章問題一樣,怎樣來選擇
的大小,使J(
)減小的速度儘量快並收斂到最小值。當
比較小時,J(
)通過多次的迭代會不斷減小,最終減小到一個很小值,但太小,減小速度也是比較慢;當
太大時,J(
)通過多次的迭代可能不會減小反而增大,如圖4所示。

圖4 當太大時
3.4 Features and polynomial regression(特徵與多項式迴歸)
對於房子的價格預測問題,h(x)=0+
1*frontage+
2*depth,這個時候我們引入了兩個變數frontage、depth,而我們在實際中可以用size=frontage*depth來代替兩個變數,這個時候h(x)=
0+
1*size,問題就會變得簡單,根據價格price(y)和size(x)的關係,如圖5所示,在前面的介紹中,我們一直都是在用線性關係來描述y和x的關係,但是從這個圖中可以看出,用線性關係來描述顯然是不夠準確的,從影象前面的走向似乎是一個二次函式,不妨我們設h(x)=
0+
1*x+
2*x^2,但是二次函式是一個關於對稱軸對稱的圖形,表明到了後面,會是下降的趨勢,而根據實際情況可知,price是不會下降的,所以我們可以猜想h(x)=
0+
1*x+
2*x^2+
3*x^3,這個時候若令h(x)=
0+
1*x+
2*x^2+
3*x^3=
0+
1*(size)+
2*(size)^2+
3*(size)^3,所以x1=(size)、x2=(size)^2、x3=(size)^3,而似乎我們還有另外一個更好的函式關係來描述兩者的關係:h(x)=
0+
1*(size)+
2*
等等,想告訴大家的是在選擇函式時,是不止有線性關係可以考慮的,還有其他的函式關係可以考慮,可能比線性關係更接近實際關係。

圖5 price(y)和size(x)的關係
3.5 Normal equation(標準方程)
回到最初的問題,我們的目的是尋找使J()最小時的
值,如圖6所示。

圖6 J()和
的關係
如果我們令J()=a*
^2+b*
+c,找到使J(
)最小,即當
時的
值,而對於J(
)=
,令
(for every j),去找到
0,
1,...,
n。
下面用一個實際的例子來向大家介紹的求法,如圖7所示。

圖7 當m=4時,每個y所對應的不同x
,至於關於這個式子的數學推到,大家可以只做瞭解,不需要深入地探究。
J()=
J(
)=
=
,再對J(
)關於
求導並令其為0,即可求出對應的
,值得注意的是(
)必須是可逆矩陣,即每個特徵都是相互獨立的,沒有多餘的特徵。
以上就是關於的另一個求法,注意X矩陣的寫法,增加了第一列都是1,這是為了對後面做運算相匹配。那麼問題就來了,對於前面我們介紹了通過迭代來求出
,現在又有這個公式可以一步求出
,那到底哪一個對於求
比較好了,或者哪種情況該用哪一個?
答:關於這個的計算比較方便容易的,不需要選擇(learning rate)
,而而前面所介紹的Gradient Descent需要選擇
,而這個
是不好掌控的,但是不是任何時候選擇Normal Equation都是最好的了?答案是否定的,因為當資料量很大時,關於求(
)的逆是很消耗計算機的時間的,所以我們大致有一個評判標準,當n=10000多時,我們就選擇Gradient Descent而當n小於這個值時,我們就果斷地選擇Normal Equation。
在以上的討論中,我們所得到的公式是:,而上面也提到了使用這個公式時的前提就是(
)要求可逆,但如果不可逆,則怎麼辦了?而前面也說了,不可逆即存在多餘的特徵,我們要做的就是去除多餘的特徵,使特徵都是相互獨立的再進行計算。
最後想跟大家說一下如何用matlab來計算這個式子,直接輸入=inv(X'X)*(X')*y即可,注意X'即求X的轉置。