
影象檢索中為什麼仍用BOW和LSH
去年年底的時候在一篇部落格中,用ANN的框架解釋了BOW模型[1],並與LSH[2]等雜湊方法做了比較,當時得出了結論,BOW就是一種經過學習的Hash函式。去年再早些時候,又簡單介紹過LLC[3]等稀疏的表示模型,當時的相關論文幾乎一致地得出結論,這些稀疏表示的方法在影象識別方面的效能一致地好於BOW的效果。後來我就逐漸產生兩個疑問:
1)BOW在檢索時好於LSH,那麼為什麼不在任何時候都用BOW代替LSH呢?
2)既然ScSPM,LLC等新提出的方法一致地好於BOW,那能否直接用這些稀疏模型代替BOW來表示影象的特徵?
粗略想了一下,心中逐漸對這兩個問題有了答案。這篇博文我就試圖在檢索問題上,談一談Bag-of-words模型與LSH存在的必要性。
LSH方法本身已經在很多文章中有過介紹,大家可以參考這裡和這裡。其主要思想就是在特徵空間中對所有點進行多次隨機投影(相當於對特徵空間的隨機劃分),越相近的點,隨機投影后的值就越有可能相同。通常投影后的值是個binary
code(0或者1),那麼點xi經過N次隨機投影后就可以得到一個N維的二值向量qi,qi就是xi經過LSH編碼後的值。
問題是LSH是一種隨機投影(見圖1),上篇部落格中也提到這樣隨機其實沒有充分利用到樣本的實際分佈資訊,因此N需要取一個十分大的數才能取得好的效果。因此,[2]中作者理所當然地就想到對LSH的投影函式進行學習(用BoostSSC和RBM來做學習),效果可以見圖3。經過學習的LSH就可以通過更少的投影函式取得更好的區分性。這就和BOW的作用有點像了(都是通過學習對原始的特徵空間進行劃分),只不過BOW對特徵空間的劃分是非線性的(見圖2),而LSH則是線性的。
圖1

圖2
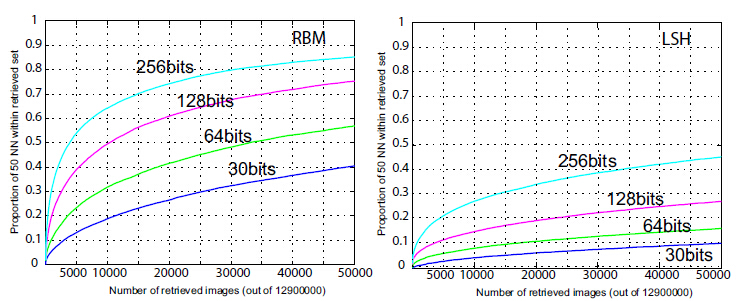
圖3
二、LSH VS BOW:檢索的時候對什麼特徵做編碼?( 以下對LSH的介紹將不區分是否利用BoostSSC和RBM來做學習)。LSH一般是對影象的全域性特徵做LSH。比如影象的GIST,HOG,HSV等全域性的特徵。可以說,LSH是將一個特徵編碼成另外一個特徵。這有一點降維的味道。經過N次隨機投影后,特徵被降維為一個長度為N的二值特徵了。
BOW一般是對影象的區域性特徵做編碼,比如SIFT,MSER等。BOW是將一組特徵(區域性特徵)編碼成一個特徵(全域性特徵),帶有一種aggregation的性質。這是它與LSH最大的不同之處。 三、LSH VS BOW:檢索和排序的過程有何不同?
先來說說LSH。假設兩個樣本x1和y1經過LSH編碼後得到q1和q2,那麼兩個樣本之間的相似度可以這麼計算:
 (1)
(1)
這就是LSH編碼後兩個樣本之間的漢明距離。假設我們有一個dataset,把dataset裡面的圖片記做di。有一個查詢圖片query,記做q。假設已經對dataset和query的所有圖片經過LSH編碼了,會有兩種方式進行圖片檢索:
a) 建立一張雜湊表,di編碼後的code做為雜湊值(鍵值)。每個di都有唯一的一個鍵值。query編碼後,在這張雜湊表上進行查詢,凡是與query不超過D個bits不同的codes,就認為是與query近鄰的,也就把這些鍵值下的圖片檢索出來。這種做法十分快速(幾乎不用做任何計算),缺點在於Hash table將會非常大,大小是。
b) 如果N大於30(這時(a)中的hash table太大了),通常採用exhaustive search,即按照(1)式計算q到di的hamming距離,並做排序。因為是binary code,所以速度會非常快(12M圖片不用1秒鐘就能得到結果)。
再來說說BOW如何做檢索(這個大家都很熟悉了)。假設已經通過BOW得到了影象的全域性特徵向量,通常通過計算兩個向量的直方圖距離確定兩個向量的相似度,然後進行排序。因為BOW特徵是比較稀疏的,所以可以利用倒排索引提高檢索速度。
四、BOW能否代替LSHBOW是從一組特徵到一個特徵之間的對映。你可能會說,當“一組特徵”就是一個特徵(也就是全域性特徵)的時候,BOW不也能用來對全域性特徵做編碼麼?這樣做是不好的,因為這時BOW並不和LSH等效。為什麼呢?一幅影象只能提取出一個GIST向量,經過BOW編碼後,整個向量將會只有在1個bin上的取值為1,而在其他bin上的取值為0。於是乎,兩幅影象之間的相似度要麼為0,要麼為1。想像在一個真實的影象檢索系統中,dataset中的相似度要麼是0要麼是1,相似的圖片相似度都是1,被兩級化了,幾乎無法衡量相似的程度了。所以說BOW還是比較適合和區域性特徵搭配起來用。其實LSH的索引a)方法也很類似,Hash值(codes)一樣的影象之間是比較不出相似程度的。確實也如此,但是LSH和BOW相比仍然有處不同,便是經過LSH編碼後不會像BOW那樣極端(整個向量只有1個值為1,其它值為0)。所以通過1)式計算出的相似度依然能夠反映兩特徵原始的相似度。所以在比較全域性特徵的時候,還是LSH比較好用些。
五、LSH能否代替BOWBOW在處理區域性特徵的時候,相當於兩幅影象之間做點點匹配。如果把LSH編碼的所有可能級聯成一維向量的話,我覺得在一定程度上是起到了BOW相似的作用的。
六、LLC能否代替BOW不完全可以吧。儘管在識別問題上,LLC效能是比BOW好,但是由於HKM[4]和AKM[5]的提出,BOW的碼書可以訓練到非常大(可以達到1000000維)。而LLC之類的學習方法就沒那麼幸運了,說到天上去也就幾萬維吧。儘管相同維數下BOW效能不那麼好,但是放到100萬維上,優勢就體現出來了。所以在檢索問題上,BOW依然如此流行。
----------------------------
參考文獻:
[1]Video Google: A Text Retrieval Approach to Object Matching in Videos
[2]Small Codes and Large Image Databases for Recognition
[3]Locality-constrained Linear Coding for Image Classification
[4]Scalable Recognition with a Vocabulary Tree
[5]Object retrieval with large vocabularies and fast spatial matching