
影象檢索中BOW和LSH的一點理解
去年年底的時候在一篇部落格中,用ANN的框架解釋了BOW模型[1],並與LSH[2]等雜湊方法做了比較,當時得出了結論,BOW就是一種經過學習的Hash函式。去年再早些時候,又簡單介紹過LLC[3]等稀疏的表示模型,當時的相關論文幾乎一致地得出結論,這些稀疏表示的方法在影象識別方面的效能一致地好於BOW的效果。後來我就逐漸產生兩個疑問:
1)BOW在檢索時好於LSH,那麼為什麼不在任何時候都用BOW代替LSH呢?
2)既然ScSPM,LLC等新提出的方法一致地好於BOW,那能否直接用這些稀疏模型代替BOW來表示影象的特徵?
粗略想了一下,心中逐漸對這兩個問題有了答案。這篇博文我就試圖在檢索問題上,談一談Bag-of-words模型與LSH存在的必要性。
LSH方法本身已經在很多文章中有過介紹,大家可以參考這裡和這裡。其主要思想就是在特徵空間中對所有點進行多次隨機投影(相當於對特徵空間的隨機劃分),越相近的點,隨機投影后的值就越有可能相同。通常投影后的值是個binary
code(0或者1),那麼點xi經過N次隨機投影后就可以得到一個N維的二值向量qi,qi就是xi經過LSH編碼後的值。
問題是LSH是一種隨機投影(見圖1),上篇部落格中也提到這樣隨機其實沒有充分利用到樣本的實際分佈資訊,因此N需要取一個十分大的數才能取得好的效果。因此,[2]中作者理所當然地就想到對LSH的投影函式進行學習(用BoostSSC和RBM來做學習),效果可以見圖3。經過學習的LSH就可以通過更少的投影函式取得更好的區分性。這就和BOW的作用有點像了(都是通過學習對原始的特徵空間進行劃分),只不過BOW對特徵空間的劃分是非線性的(見圖2),而LSH則是線性的。
圖1

圖2
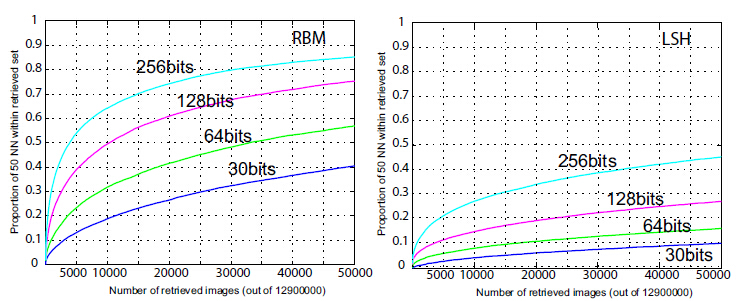
圖3
二、LSH VS BOW:檢索的時候對什麼特徵做編碼?( 以下對LSH的介紹將不區分是否利用BoostSSC和RBM來做學習)。LSH一般是對影象的全域性特徵做LSH。比如影象的GIST,HOG,HSV等全域性的特徵。可以說,LSH是將一個特徵編碼成另外一個特徵。這有一點降維的味道。經過N次隨機投影后,特徵被降維為一個長度為N的二值特徵了。
BOW一般是對影象的區域性特徵做編碼,比如SIFT,MSER等。BOW是將一組特徵(區域性特徵)編碼成一個特徵(全域性特徵),帶有一種aggregation的性質。這是它與LSH最大的不同之處。 三、LSH VS BOW:檢索和排序的過程有何不同?
先來說說LSH。假設兩個樣本x1和y1經過LSH編碼後得到q1和q2,那麼兩個樣本之間的相似度可以這麼計算:
 (1)
(1)
這就是LSH編碼後兩個樣本之間的漢明距離。假設我們有一個dataset,把dataset裡面的圖片記做di。有一個查詢圖片query,記做q。假設已經對dataset和query的所有圖片經過LSH編碼了,會有兩種方式進行圖片檢索:
a) 建立一張雜湊表,di編碼後的code做為雜湊值(鍵值)。每個di都有唯一的一個鍵值。query編碼後,在這張雜湊表上進行查詢,凡是與query不超過D個bits不同的codes,就認為是與query近鄰的,也就把這些鍵值下的圖片檢索出來。這種做法十分快速(幾乎不用做任何計算),缺點在於Hash table將會非常大,大小是。
b) 如果N大於30(這時(a)中的hash table太大了),通常採用exhaustive search,即按照(1)式計算q到di的hamming距離,並做排序。因為是binary code,所以速度會非常快(12M圖片不用1秒鐘就能得到結果)。
再來說說BOW如何做檢索(這個大家都很熟悉了)。假設已經通過BOW得到了影象的全域性特徵向量,通常通過計算兩個向量的直方圖距離確定兩個向量的相似度,然後進行排序。因為BOW特徵是比較稀疏的,所以可以利用倒排索引提高檢索速度。
四、BOW能否代替LSHBOW是從一組特徵到一個特徵之間的對映。你可能會說,當“一組特徵”就是一個特徵(也就是全域性特徵)的時候,BOW不也能用來對全域性特徵做編碼麼?這樣做是不好的,因為這時BOW並不和LSH等效。為什麼呢?一幅影象只能提取出一個GIST向量,經過BOW編碼後,整個向量將會只有在1個bin上的取值為1,而在其他bin上的取值為0。於是乎,兩幅影象之間的相似度要麼為0,要麼為1。想像在一個真實的影象檢索系統中,dataset中的相似度要麼是0要麼是1,相似的圖片相似度都是1,被兩級化了,幾乎無法衡量相似的程度了。所以說BOW還是比較適合和區域性特徵搭配起來用。其實LSH的索引a)方法也很類似,Hash值(codes)一樣的影象之間是比較不出相似程度的。確實也如此,但是LSH和BOW相比仍然有處不同,便是經過LSH編碼後不會像BOW那樣極端(整個向量只有1個值為1,其它值為0)。所以通過1)式計算出的相似度依然能夠反映兩特徵原始的相似度。所以在比較全域性特徵的時候,還是LSH比較好用些。
五、LSH能否代替BOWBOW在處理區域性特徵的時候,相當於兩幅影象之間做點點匹配。如果把LSH編碼的所有可能級聯成一維向量的話,我覺得在一定程度上是起到了BOW相似的作用的。
六、LLC能否代替BOW不完全可以吧。儘管在識別問題上,LLC效能是比BOW好,但是由於HKM[4]和AKM[5]的提出,BOW的碼書可以訓練到非常大(可以達到1000000維)。而LLC之類的學習方法就沒那麼幸運了,說到天上去也就幾萬維吧。儘管相同維數下BOW效能不那麼好,但是放到100萬維上,優勢就體現出來了。所以在檢索問題上,BOW依然如此流行。
[email protected]/7/23
講了好多廢話,最主要的區別是想說,BOW不是一種distributed representation,而LSH卻是一種distributed representation。
----------------------------
參考文獻:
[1]Video Google: A Text Retrieval Approach to Object Matching in Videos
[2]Small Codes and Large Image Databases for Recognition
[3]Locality-constrained Linear Coding for Image Classification
[4]Scalable Recognition with a Vocabulary Tree
[5]Object retrieval with large vocabularies and fast spatial matching
-----------------
jiang1st2010
轉載請註明出處:http://blog.csdn.net/jwh_bupt/article/details/27713453
相關推薦
影象檢索中BOW和LSH的一點理解
去年年底的時候在一篇部落格中,用ANN的框架解釋了BOW模型[1],並與LSH[2]等雜湊方法做了比較,當時得出了結論,BOW就是一種經過學習的Hash函式。去年再早些時候,又簡單介紹過LLC[3]等稀疏的表示模型,當時的相關論文幾乎一致地得出結論,這些稀疏表示的方法在影
ESP8266 中 cache 和 iram 一點理解
前提閱讀 ESP8266 基礎篇:記憶體分佈 ESP8266 基礎篇:段的概念 指令載入方式 一. iram 方式(0x4010…, 需 load) 使用者可通過 ld 檔案中 iram1_0_seg 指定某個lib/某個段, 或者通過下面方式指定某個
影象檢索中為什麼仍用BOW和LSH
去年年底的時候在一篇部落格中,用ANN的框架解釋了BOW模型[1],並與LSH[2]等雜湊方法做了比較,當時得出了結論,BOW就是一種經過學習的Hash函式。去年再早些時候,又簡單介紹過LLC[3]等稀疏的表示模型,當時的相關論文幾乎一致地得出結論,這些稀疏表示的方法在影
對Spring中IOC和AOP的理解
ted program 條件 ogr class spring配置 所有 com 語法 IOC:控制反轉也叫依賴註入。利用了工廠模式。 為了方便理解,分解成每條以便記憶。 1.將對象交給容器管理,你只需要在spring配置文件總配置相應的bean,以及設置相關的屬性,讓
Java中InputStream和Reader的理解
java.io下面有兩個抽象類:InputStream和Reader InputStream是表示位元組輸入流的所有類的超類 Reader是用於讀取字元流的抽象類 InputStream提供的是位元組流的讀取,而非文字讀取,這是和Reader類的根本區別。 即用Reader讀取出來的是char陣列或
pointnet中stn和mlp的理解錯誤的方式。
一開始以為文章中的程式碼是這樣的意思: self.inputTransform=nn.Sequential( nn.Linear(point_num*3,64), nn.BatchNorm1d(64), nn.ReLU(inplace=True), nn.L
對設計領域中Tile和Card的理解
前端工程師離不開設計, 談到設計就要想到大名鼎鼎的material design主題, 而material是以card為經典單元的, card即卡片, 是層次化模型的最小模組, 用於提供扁平化的資訊, 想必大家都不陌生, 但是近幾年出現了新的設計元素, Tile, 翻譯過啦叫'瓦塊', 初
【轉載】關於C#中Thread.Join()的一點理解
今天是第一次在C#中接觸Thread,自己研究了一下其中Thread.Join()這個方法,下面談談自己的理解。 Thread.Join()在MSDN中的解釋很模糊:Blocks the calling thread until a thread terminates 有兩個主
檔案系統中目錄和檔案的理解
在最開始的開始,讓我們瞭解一下兩個事實: 1、目錄檔案和普通檔案都是檔案 2、作業系統想要管理這些檔案,就需要得到兩個東西,目錄項(有時候也叫FCB)和檔案內容 其中目錄項存放三個主要的內容:檔案的名字,ID號,檔案內容在物理裝置的儲存地址。 那作業系統裡的檔案系統是
對於spring中IOC和AOP的理解及程式碼簡單實現
IoC(Inversion of Control): 在傳統的java程式編寫中如果呼叫方法或類者,必須要對被呼叫者進行例項化,即必須要通過new 被呼叫者類,才能對被呼叫者類中的方法、成員進行操作。在開發某一個專案時必然會出現很多類來完善專案的需求,並且類與類
【轉】C++中堆和棧的理解
一、預備知識—程式的記憶體分配 一個由c/C++編譯的程式佔用的記憶體分為以下幾個部分 1、棧區(stack)— 由編譯器自動分配釋放 ,存放函式的引數值,區域性變數的值等。其操作方式類似於資料結構中的棧。 2、堆區(heap) — 一般由程式設計師分配釋放, 若程式設計
我對Java中extends和implements的理解
第一點: extends 是繼承另一個類,而且是但繼承。 implements是實現一個介面,但是可以同時實現多個介面。 第二點: extends繼承另一個類,那個被整合的類可以使抽象類,也可以不是抽象類。如果是抽象類並且擁有抽象方法,那麼子類中必須重寫所有的抽象方法,選擇性的重
iOS中 KVC和KVO的理解和用途
KVC(Key-Value Coding) KVC,即是指 NSKeyValueCoding,一個非正式的 Protocol,提供一種機制來間接訪問物件的屬性。 一個物件擁有某些屬性。比如說,一個 Man 物件有一個 name 和一個 age 屬性。以 KVC 說法,這個Man&n
Kotlin 中 object 和 companion 的理解
首先, 這兩個東東最終都會是 java 中的靜態內部類, 然後說下不同的地方: 首先看看 kotlin 的程式碼: class Test { companion object C { val cachePool: ExecutorService = Ex
淺談JAVA中類和物件的理解
我們知道程式語言是一個幫助我們和計算機“對話”的工具,我們可以通過它去讓計算機做一些事。而JAVA語言又是其中的高階語言,那麼什麼是高階?機器語言和人類語言之間有著巨大的鴻溝,人們不斷的想要跨過這個鴻溝,在這個過程中出現了一些“工具”,就是所謂的程式語言。通過這些語言
攝像機標定外參矩陣中R和t的理解
1、R的第i行 表示攝像機座標系中的第i個座標軸方向的單位向量在世界座標系裡的座標 2、R的第i列 表示世界座標系中的第i個座標軸方向的單位向量在攝像機座標系裡的座標 3、t 表示世界座標系的原點在
對C++中類和封裝的理解
封裝是將相對獨立,能夠廣泛使用的程式功能提煉出來,編寫成函式或類等形式的可重用程式碼。可重用的程式碼的特點是“一次開發,長期使用”。C++的封裝的語法格式用一個簡單的例子來看下class Rectangle //長方形類:宣告成員{public:double a,b;
對PHP5中__set和__get的理解
引用一個偷學來的概念: 成員變數是一個“內”概念,反映類的結構構成。屬性是一個“外”概念,反映的是類的邏輯意義。成員變數沒有讀寫許可權的控制,而屬性可以指定只讀只寫,或可讀或可寫。成員變數不對讀出做任何後處理,不對寫入做任預處理,而屬性可以。public成員變數可以視作沒有
C,C++巨集中#、##和__VA_ARGS__的理解
巨集中的#的功能是將其後面的巨集引數進行字串化操作(Stringizing operator),簡單說就是在它引用的巨集變數的左右各加上一個雙引號。 如定義好#define STRING(x) #x之後,下面二條語句就等價。 char *pChar = "h
關於多執行緒中同步和非同步的理解
執行緒同步:就是多個執行緒同時訪問同一資源,必須等一個執行緒訪問結束,才能訪問其它資源,比較浪費時間,效率低 執行緒非同步:訪問資源時在空閒等待時可以同時訪問其他資源,實現多執行緒機制 說起來比較抽象,我用程式碼嘗試了一下 //以非同步的方式提交佇列 -(