
HDFS架構原理分析
HDFS優點:
| 高容錯性 |
數據自動儲存多個副本 副本丟失後,自動恢復 |
| 適合批處理 |
移動計算而非資料 資料位置暴露給計算框架 |
| 適合大資料處理 |
GB、TB、甚至PB級別資料 百萬規模以上的檔案數量 10K+節點 |
| 可構建在廉價機器上 | 可構建在廉價機器上 |
HDFS缺點:
| 低延遲資料訪問 |
比如毫秒級 低延遲與高吞吐率 |
| 小檔案存取 |
佔用NameNode大量記憶體 尋道時間超過讀取時間 |
| 併發寫入、檔案隨機修改 |
一個檔案只能有一個寫者 僅支援append |
HDFS架構:
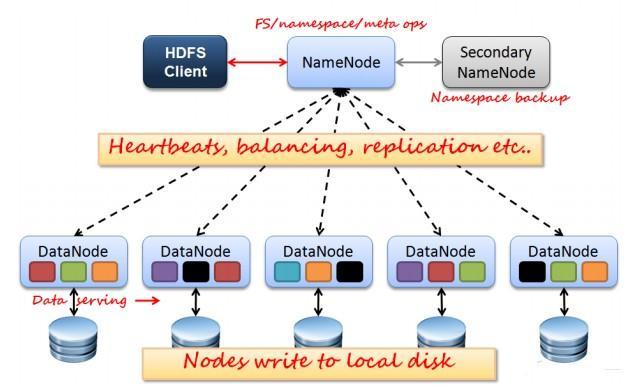
HDFS架構圖
主節點:NameNode
從節點:DataNode
Secondary NameNode節點:輔助NameNode完成一些工作。
HDFS資料儲存單元(black):
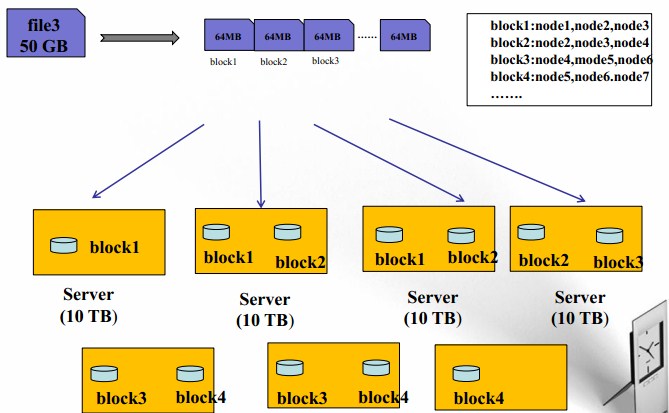
- 檔案被切分成固定大小的資料塊
預設資料塊大小為64MB(hadoop1.x),可配置
若檔案大小不到64MB,則單獨存成一個block
- 一個檔案儲存方式
按大小被切分成若干個block,儲存到不同節點上
預設情況下每個block都有三個副本
- Block大小和副本數通過Client端上傳檔案時設定,檔案上傳成功後副本數可以變更,Block Size不可變更。
HDFS設計思想
NameNode(NN):
- NameNode主要功能:接受客戶端的讀寫服務
- NameNode儲存metaData資訊,包括:
檔案owership和permissions
檔案包含哪些Block
Block儲存在哪個DataNode(由DataNode啟動時上報)
- NameNode的medadata資訊在啟動後會載入到記憶體
metadata儲存到磁碟檔名為"fsimage"
Block的位置資訊不會儲存到fsimage(其是儲存在記憶體中)
edits記錄對medadata的操作日誌
SecondNameNode(SNN):
- 它不是NN的備份(但可以備份),它的主要工作是幫助NN合併edits log,減少NN啟動時間。
- SNN執行合併時機
根據配置檔案設定的時間間隔fs.checkpoint.period 預設為3600秒
根據配置檔案設定edits log大小fs.checkpoing.size規定edits檔案的最大值預設是64MB
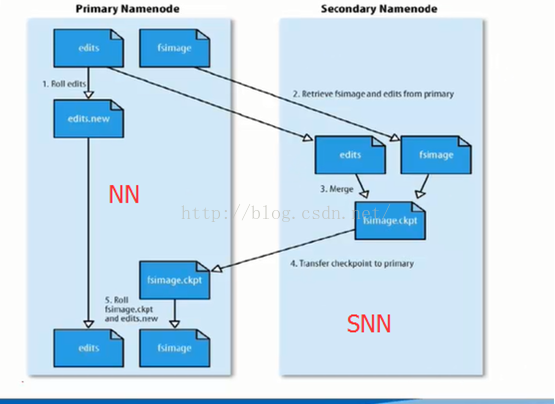
SNN合併流程
DataNode(DN):
- 儲存資料(Block)
- 啟動DN執行緒的時候會向NN彙報block資訊
- 通過向NN傳送心跳保持與其聯絡(3秒一次),如果NN 10分鐘沒有收到DN的心跳,則認為其已經lost,並copy其上的block到其他 DN
HDFS寫入流程:
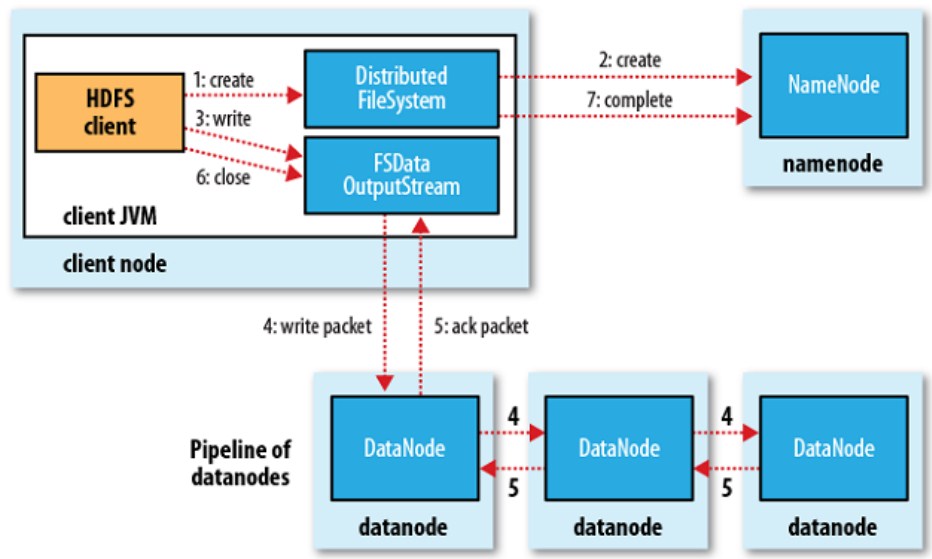
HDFS寫入流程圖
HDFS讀流程:
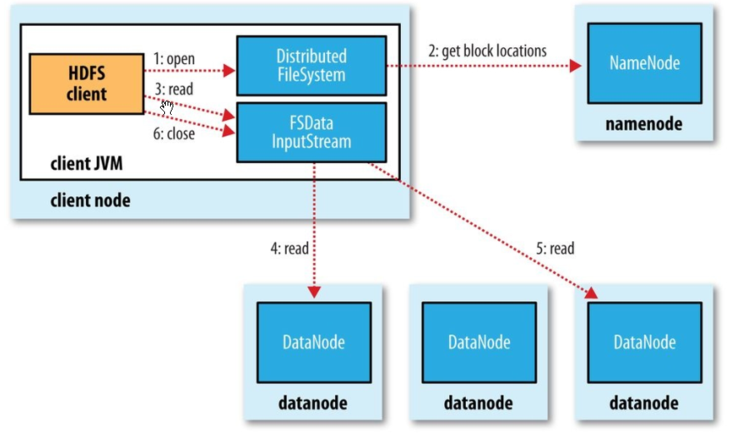
HDFS讀流程圖
HDFS檔案許可權:
- 與Linux檔案許可權類似
r:read, w:write, x:execute,許可權x對於檔案忽略,對於資料夾表示是否允許訪問其內容
- 如果Linux系統使用者zhangsan使用hadoop命令建立一個檔案,那麼這個檔案在HDFS中owner就只zhangsan
HDFS安全模式:
- NameNode啟動的時候,首先將fsimage載入記憶體,並執行編輯日誌(edits)中的各項操作。
- 一旦在記憶體中成功建立檔案系統元資料的對映,則建立一個新的fsimage檔案(這個操作不需要SecondaryNameNode)和一個空的編輯日誌。
- 此刻NameNode執行在安全模式。即NameNode的檔案系統對於客戶端來說是隻讀的。
- 在此階段NameNode收集各個DataNode的報告,當資料塊到最小副本數以上時,會被認為是安全的,在一定比例(可設定)的資料塊被確定為安全後,再過若干時間,安全模式結束。
- 當檢測到副本數不足的資料塊,該塊會被複制達到最小副本數,系統中資料塊的位置並不是由NameNode維護的,而是以塊列表形式儲存在DataNode中。