
大資料(HDFS原理分析)
HDFS概述
HDFS是什麼?
源自於Google的GFS論文
發表於2003年10月
HDFS是GFS克隆版
Hadoop Distributed File System
易於擴充套件的分散式檔案系統
執行在大量普通廉價機器上,提供容錯機制
為大量使用者提供效能不錯的檔案存取服務
HDFS的優點:
高容錯性
資料自動儲存多個副本
副本丟失後自動恢復
適合批處理
移動計算而非資料
資料位置暴露給計算框架
適合大資料處理
GB、TB、甚至PB級資料
百萬規模以上的檔案數量
10K+節點規模
流式檔案訪問
一次性寫入,多次讀取
保證資料一致性
可構建在廉價機器上
通過多副本提高可靠性
提供了容錯和恢復機制
HDFS的缺點:
低延遲資料訪問
比如毫秒級
低延遲與高吞吐率
小檔案存取
佔用NameNode大量記憶體
尋道時間超過讀取時間
併發寫入、檔案隨機修改
一個檔案只能有一個寫者
僅支援append
分散式檔案系統的一種實現方式:
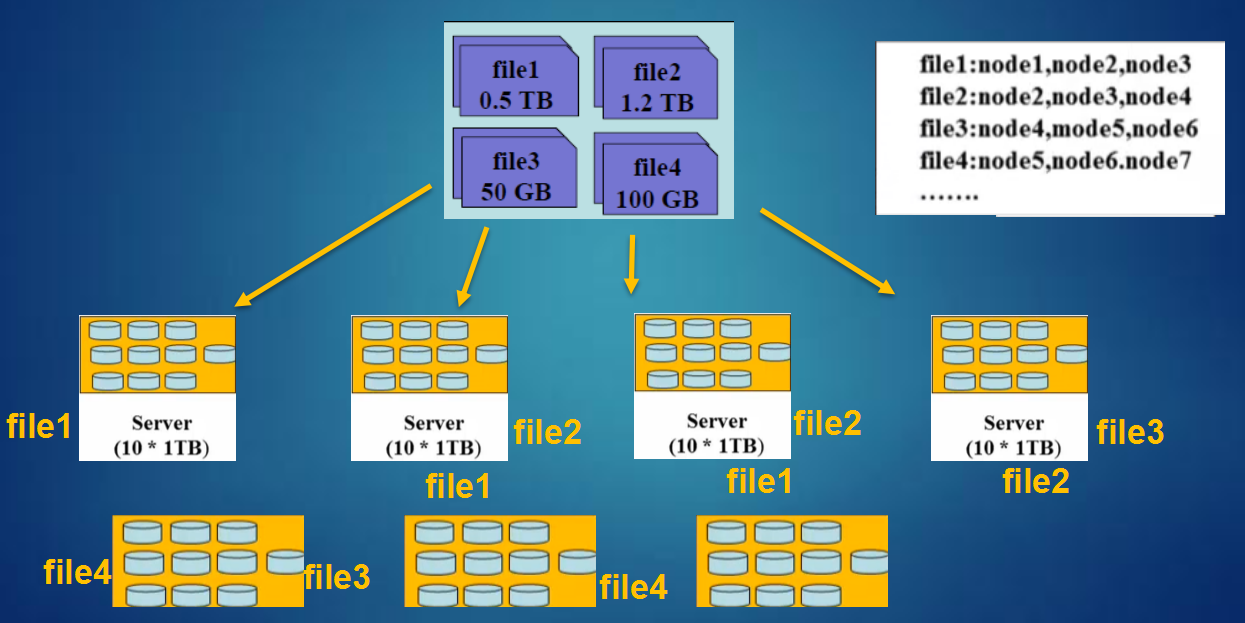
HDFS設計思想:
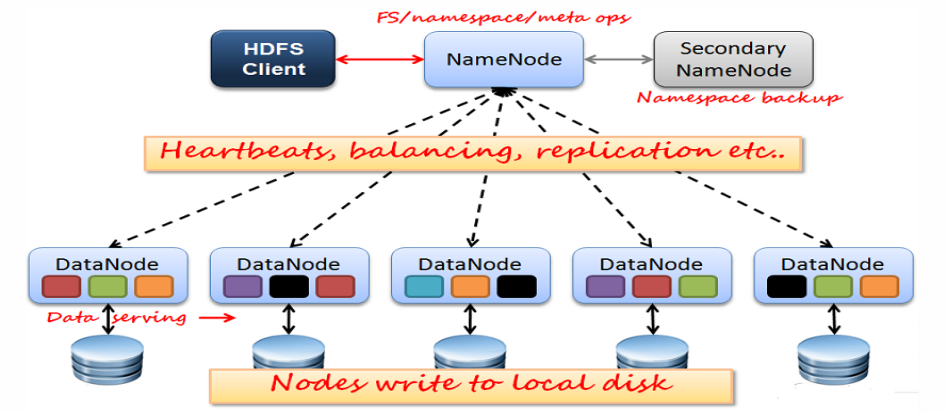
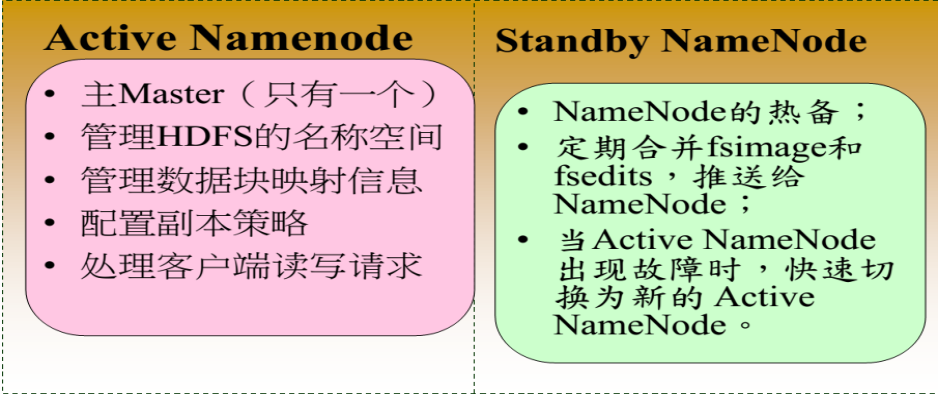
HDFS架構:
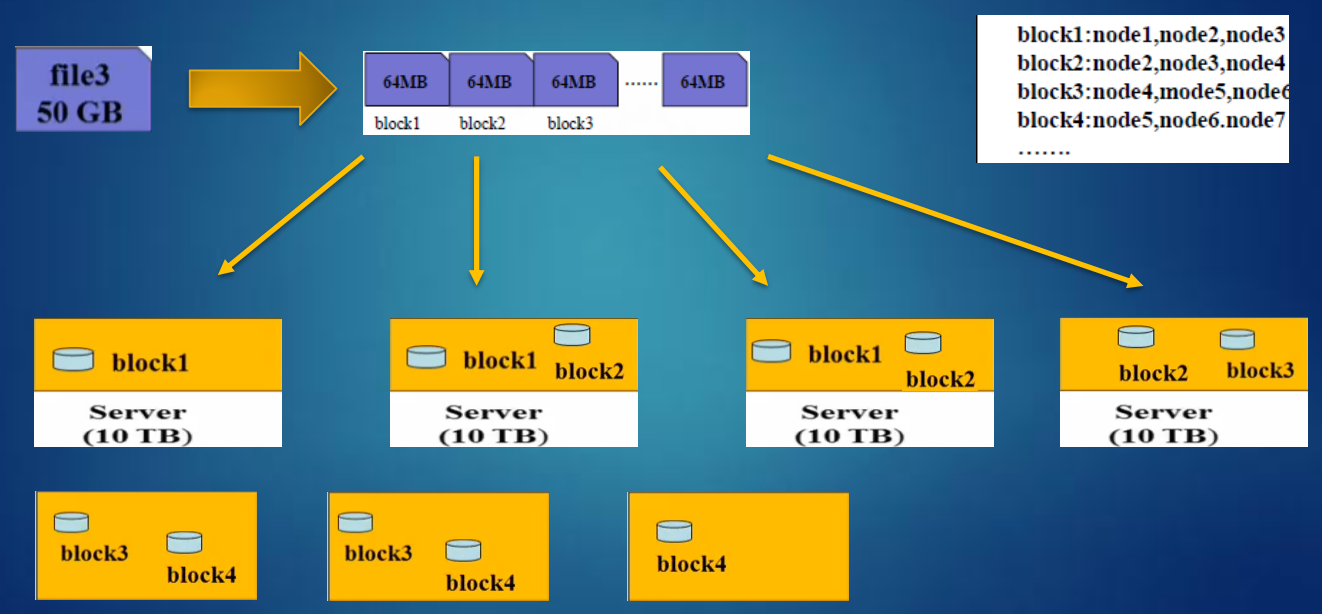
HDFS資料塊(block):
檔案被切分成固定大小的資料塊
預設資料塊大小為128MB,可配置
若檔案大小不到128MB,則單獨存成一個block
為何資料塊如此之大
資料傳輸時間超過尋道時間(高吞吐率)
一個檔案儲存方式
按大小被切分成若干個block,儲存到不同節點上
預設情況下每個block有三個副本
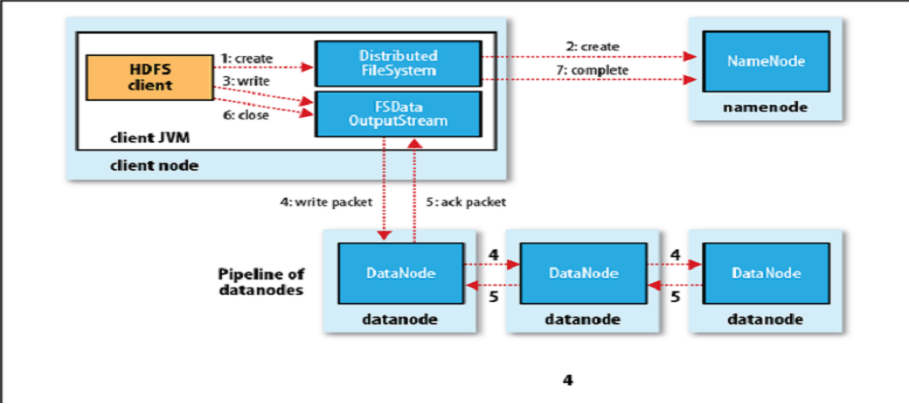
HDFS寫流程:
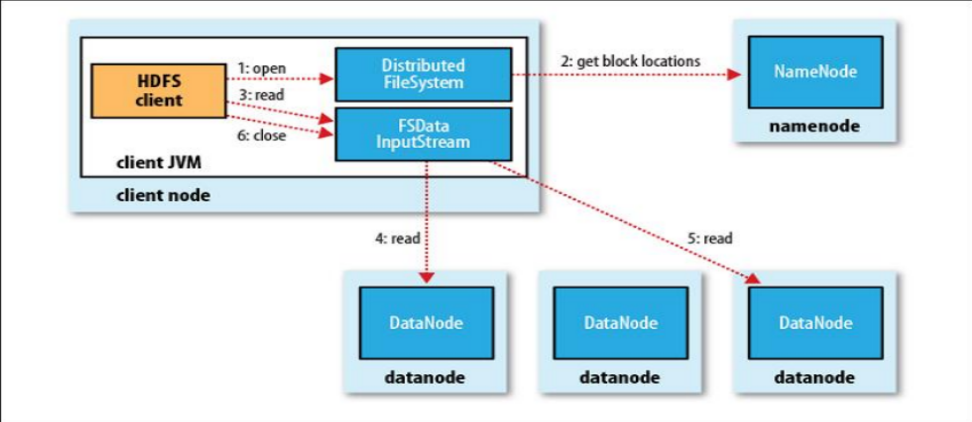
HDFS讀流程:
HDFS典型物理拓撲:
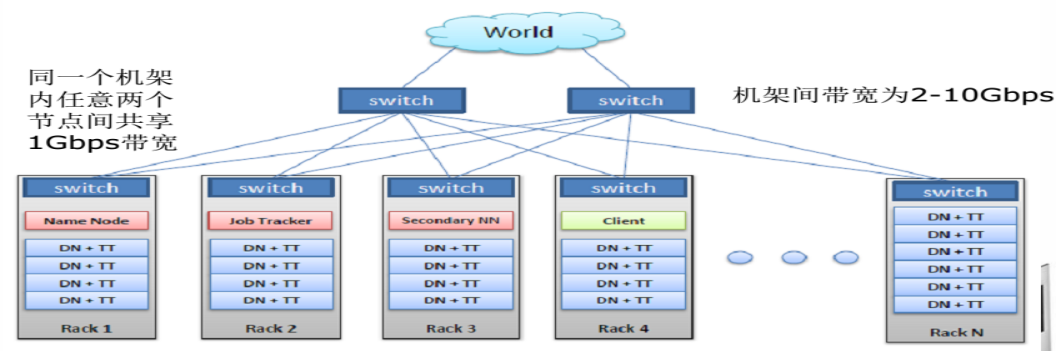
每個機架通常有16-64個節點
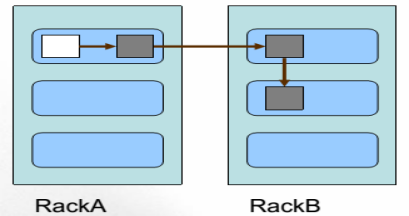
HDFS副本放置策略:
一個檔案劃分成多個block,每個block存多份,如何為每個block選擇節點儲存這幾份資料?
Block副本放置策略:
副本1:同Client的節點上
副本2:不同機架中的節點上
副本3: 與第二個副本同一機架的另一個節點上
其他副本:隨機挑選
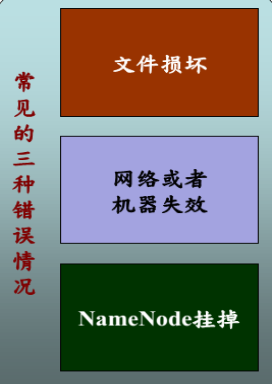
HDFS可靠性策略:
檔案完整性
---CRC32校驗
---用其他副本取代損壞檔案
Heartbeat
---Datanode定期向Namenode發heartbeat
元資料資訊
---FSImage(檔案系統映象)、Editlog(操作 日誌)
---多份儲存
---主備NameNode實時切換
HDFS不適合儲存小檔案:
元資訊儲存在NameNode記憶體中
一個節點的記憶體是有限的
存取大量小檔案消耗大量的尋道時間
類比拷貝大量小檔案與拷貝同等大小的一個大檔案
NameNode儲存block數目是有限的
一個block元資訊消耗大約150byte記憶體
儲存一億個block,大約需要20GB記憶體
如果一個檔案大小為10K,則一億個檔案大小僅為1TB(但要消耗掉NameNode20GB記憶體)
HDFS訪問方式:
HDFS Shell命令
HDFS Java API
HDFS Fuse:實現了fuse協議
HDFS lib hdfs:C/C++訪問介面
HDFS其他語言程式設計API
使用thrift實現
支援C++、Python、php、C#等語言