
吳恩達Coursera深度學習(4-2)深度卷積模型
Class 4:卷積神經網路
Week 2:深度卷積模型
1. 經典的卷積網路
介紹幾種經典的卷積神經網路結構,分別是LeNet、AlexNet、VGGNet。
LeNet-5:
LeNet-5主要是針對灰度設計的,所以其輸入較小,為32×32×1,其結構如下:
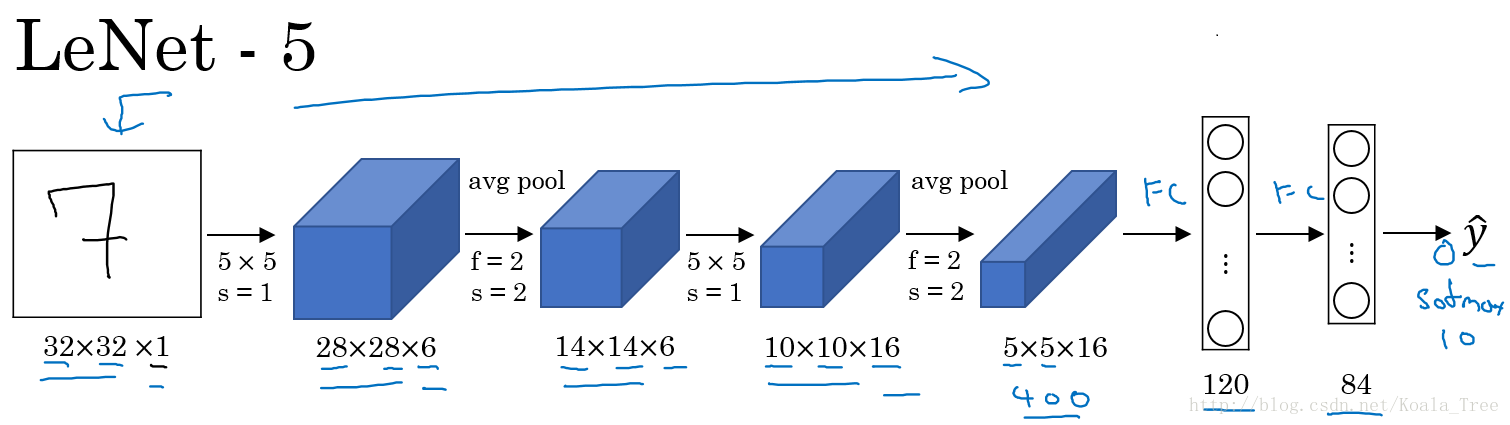
在LetNet中,存在的經典模式:
- 隨著網路的深度增加,影象的大小在縮小,與此同時,通道的數量卻在增加;
- 每個卷積層後面接一個池化層。
AlexNet:
AlexNet直接對彩色的大圖片進行處理,其結構如下:
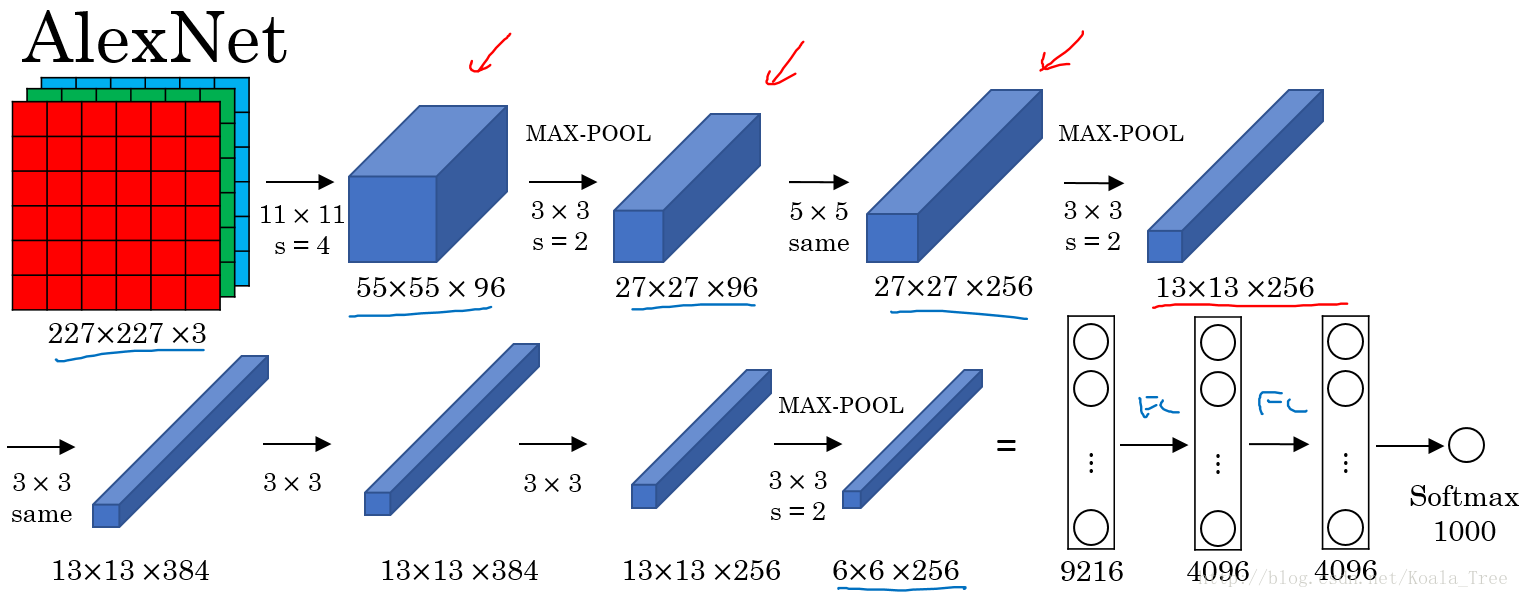
- 與LeNet相似,但網路結構更大,引數更多,表現更加出色;
- 使用了Relu;
- 使用了多個GPUs;
- LRN(後來發現用處不大,丟棄了)
AlexNet使得深度學習在計算機視覺方面受到極大的重視。
VGG-16:
VGG卷積層和池化層均具有相同的卷積核大小,都使用3×3,stride=1,SAME 的池化。其結構如下:
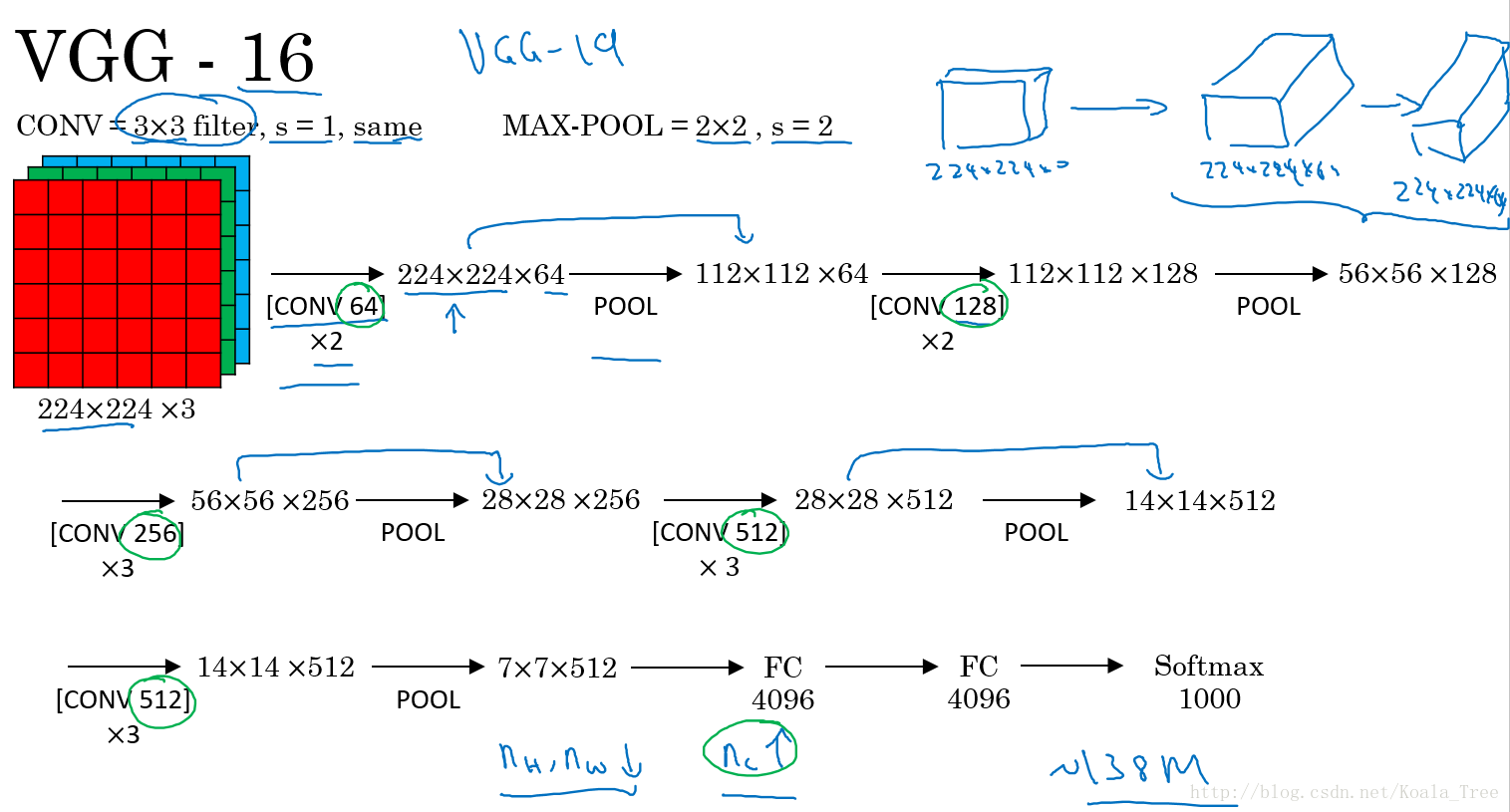
2. ResNet
ResNet是由殘差塊所構建。
殘差塊:
下面是一個普通的神經網路塊的傳輸:
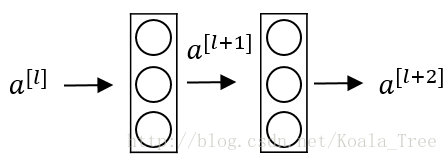
其前向傳播的計算步驟為:
- Linear:z[l+1]=W[l+1]a[l]+b[l+1]
- Relu:a[l+1]=g(z[l+1])
- Linear:z[l+2]=W[l+2]a[l+1]+b[l+2]
- Relu:a[l+2]=g(z[l+2])
而ResNet塊則將其傳播過程增加了一個從a
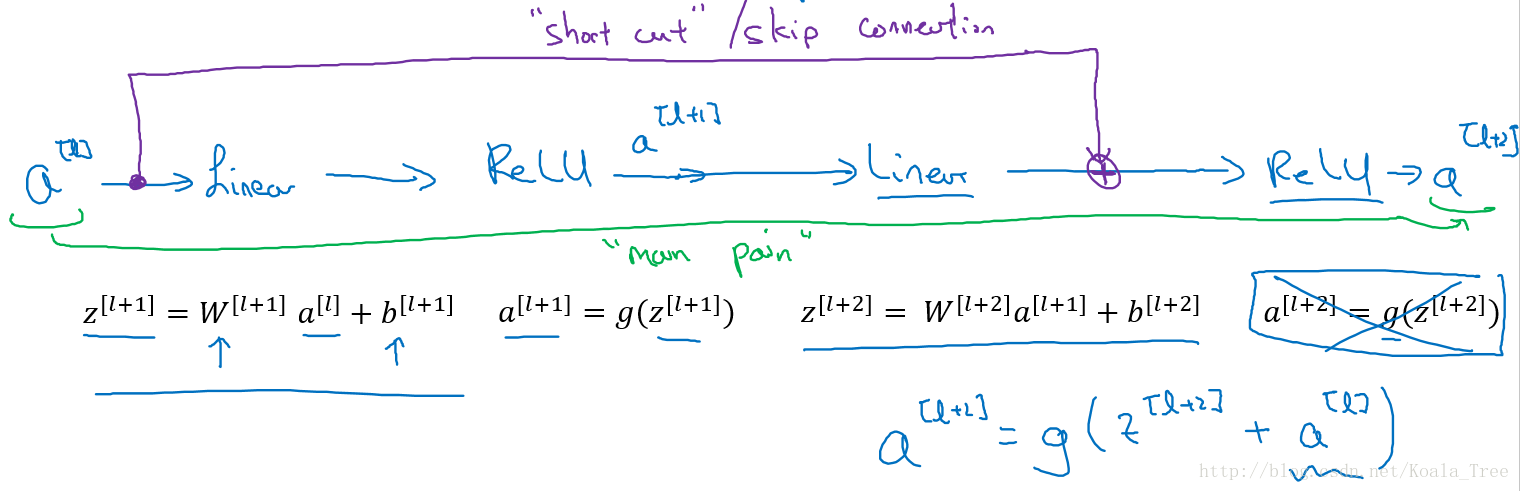
也就是前向傳播公式的最後一個步驟變為:a[l+2]=g(z[l+2]+a[l])
增加“short cut”後,成為殘差塊的網路結構:
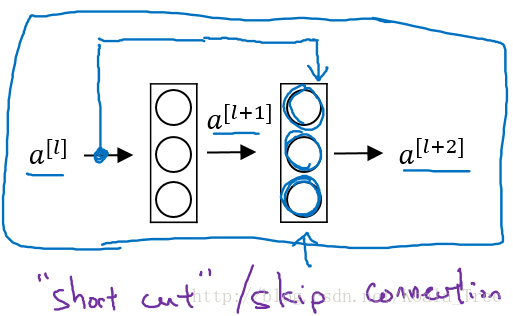
注意這裡是連線在Relu啟用函式之前。
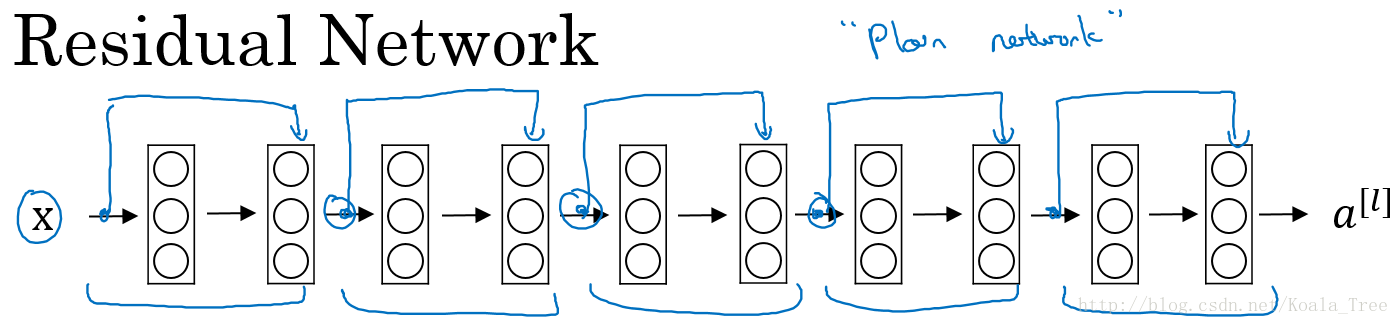
Residual Network:
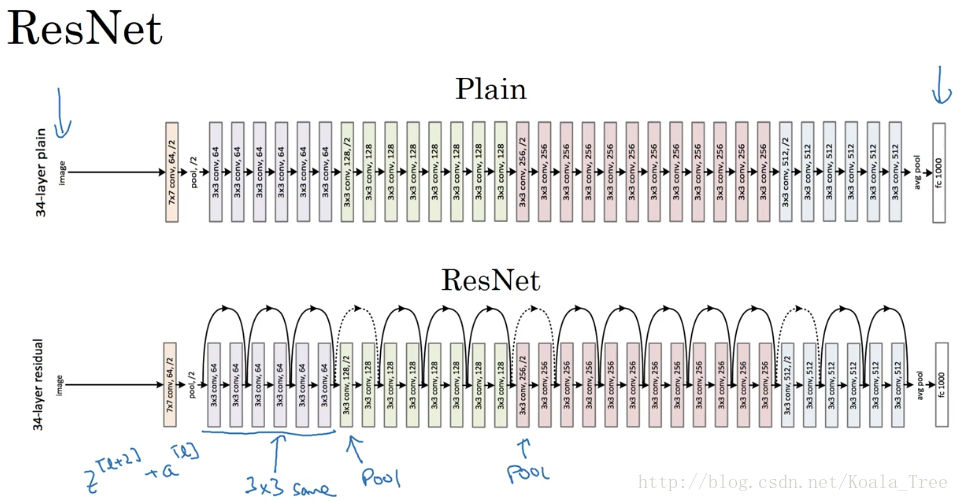
多個殘差塊堆積起來構成ResNet網路結構,其結構如下:
沒有“short cut”的普通神經網路和ResNet的誤差曲線:
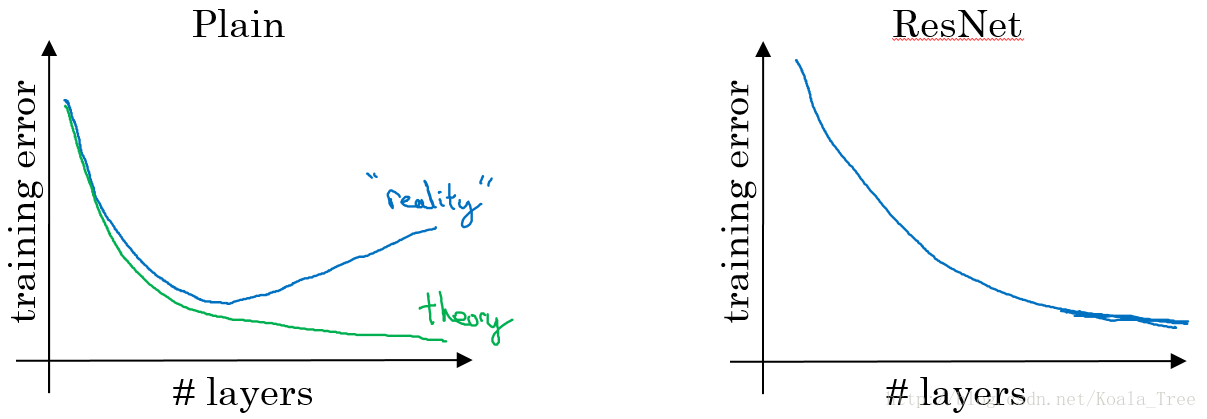
- 在沒有殘差的普通神經網路中,訓練的誤差實際上是隨著網路層數的加深,先減小再增加;
- 在有殘差的ResNet中,即使網路再深,訓練誤差都會隨著網路層數的加深逐漸減小。
ResNet對於中間的啟用函式來說,有助於能夠達到更深的網路,解決梯度消失和梯度爆炸的問題。
3. ResNet表現好的原因
假設有個比較大的神經網路,輸入為x。如果我們想增加網路的深度,這裡再給網路增加一個殘差塊:
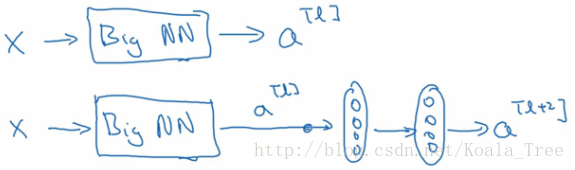
假設網路中均使用Relu啟用函式,所以最後的輸出a⩾0的值:
a[l+2]=g(z[l+2]+a[l])=g(W[l+2]a[l+1]+b[l+2]+a[l])如果使用L2正則化或者權重衰減,會壓縮W和b的值,如果W[l+2]=0,那麼上式就變成:
a[l+2]=g(z[l+2]+a[l])=g(a[l])=relu(a[l])=a[l]所以從上面的結果我們可以看出,對於殘差塊來學習上面這個恆等函式是很容易的。所以在增加了殘差塊後更深的網路的效能也並不遜色於沒有增加殘差塊簡單的網路。所以儘管增加了網路的深度,但是並不會影響網路的效能。同時如果增加的網路結構能夠學習到一些有用的資訊,那麼就會提升網路的效能。
同時由於結構a[l+2]=g(z[l+2]+a[l])的維度相同。
將普通深度神經網路變為ResNet:
在兩個相同的卷積層之間增加“skip connection”。
4. 1x1卷積
1x1卷積:
在二維上的卷積相當於圖片的每個元素和一個卷積核數字相乘。
但是在三維上,與1×1×nC個點乘以卷積數值權重,通過Relu函式後,輸出對應的結果。而不同的卷積核則相當於不同的隱層神經元結點與切片上的點進行一一連線。
所以根本上1×1個單元都應用了一個全連線的神經網路。

最終三維的圖形應用1×1的卷積核得到一個相同長寬但第三維度變為卷積核個數的圖片。
1x1卷積應用:
- 維度壓縮:使用目標維度的1×1的卷積核個數。
- 增加非線性:保持與原維度相同的1×1的卷積核個數。

5. Inception Network
Inception Network 的作用就是使我們無需去考慮在構建深度卷積神經網路時,使用多大的卷積核以及是否新增池化層等問題。
Inception主要結構:

在上面的Inception結構中,應用了不同的卷積核,以及帶padding的池化層。在保持輸入圖片大小不變的情況下,通過不同運算結果的疊加,增加了通道的數量。
計算成本的問題:
對於上面的5×5大小卷積核的計算成本:

- 1 filters:5×5×192;
- 32 個 filters;
- 總的計算成本:28×28×32×5×5×192=120M
對於1×1大小卷積核用作過渡的計算成本,也將下面的中間的層叫做“bottleneck layer”:

- 1×1
- 5×5
- 總的計算成本:2.4M+10.0M=12.4M
所以1×1卷積核作為bottleneck layer”的過渡層能夠有效減小卷積神經網的計算成本。事實證明,只要合理地設定“bottleneck layer”,既可以顯著減小上層的規模,同時又能降低計算成本,從而不會影響網路的效能。
Inception 模組:
將上面說介紹的兩種主要思想和模式結合到一起構成 Inception 模組,如下:

Inception Network:
多個Inception 模組的堆疊構成Inception Network,下面是GoogleNet的結構:

6. 遷移學習
小資料集:
如今在深度學習領域,許多研究者都會將他們的工作共享到網路上。在我們實施自己的工作的時候,比如說做某種物體的識別分類,但是隻有少量的資料集,對於從頭開始訓練一個深度網路結構是遠遠不夠的。
但是我們可以應用遷移學習,應用其他研究者建立的模型和引數,用少量的資料僅訓練最後自定義的softmax網路。從而能夠在小資料集上達到很好的效果。

大資料集:
如果我們在自己的問題上也擁有大量的資料集,我們可以多訓練後面的幾層。總之隨著資料集的增加,我們需要“ freeze”的層數越來越少。最後如果我們有十分龐大的資料集,那麼我們可以訓練網路模型的所有引數,將其他研究者訓練的模型引數作為引數的初始化來替代隨機初始化,來加速我們模型的訓練。

7. 資料擴充
與其他機器學習問題相比,在計算機視覺領域當下最主要的問題是沒有辦法得到充足的資料。所以在我們訓練計算機資料模型的時候,資料的擴充就是會非常有用。
資料擴充的方法:
- 映象翻轉(Mirroring);
- 隨機剪裁(Random Cropping);
- 色彩轉換(Color shifting):
為圖片的RGB三個色彩通道進行增減值,如(R:+20,G:-20,B:+20);PCA顏色增強:對圖片的主色的變化較大,圖片的次色變化較小,使總體的顏色保持一致。
訓練過程中的資料擴充:

為了節省時間,資料擴充的過程和訓練過程可以多CPU多執行緒來並行的實現。
8. 計算機視覺現狀
資料和手工工程:
不同問題當前的資料集大小:

在有大量資料的時候,我們更傾向於使用簡單的演算法和更少的手工工程。因為此時有大量的資料,我們不需要為這個問題來精心設計特徵,我們使用一個大的網路結果或者更簡單的模型就能夠解決。
相反,在有少量資料的時候,我們從事更多的是手工工程。因為資料量太少,較大的網路結構或者模型很難從這些少量的資料中獲取足夠的特徵,而手工工程實際上是獲得良好表現的最佳方式。
對於機器學習應用:
- 標記資料,(x,y);
- 手工特徵工程/網路結構/其他構建。
Tips for doing well:
在基準研究和比賽中,下面的tips可能會有較好的表現:
- Ensembling:獨立地訓練多個網路模型,輸出平均結果或加權平均結果;
- 測試時的 Multi-crop:在測試圖片的多種版本上執行分類器,輸出平均結果。