
jav學習筆記-String原始碼分析
java中用String類表示字串,是lang包裡面使用頻率很高的一個類,今天我們就來深入原始碼解析。事例和特性均基於java8版本。
基礎知識
String內部使用char[]陣列實現,是不可變類。
public final class String implements java.io.Serializable,Comparable<String>,CharSequence private final char value[]; //String的內部表示,不可變
private int hash; // Default to 0 ,String的雜湊值
String實現了Serializable介面,表明其可被序列化。在java中Serializable介面只是一個標記介面,該介面沒有任何方法定義。只要在類定義時標明實現該介面,JVM會自動處理。
String還實現了Comparable比較器介面,我們在TreeMap的排序及比較器問題文章提過,它是一個類的內部比較介面。一般的值類及集合類均實現了此介面。比較規則為等於返回0,大於返回正值而小於返回負值。
在此介面文件中特別強調,此介面的實現需與equals()方法行為一致。即 保證
a.compareTo(b)==0滿足的同時a.equals(b)==true也必須滿足。
該介面實現如下:
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char 程式碼邏輯比較簡單,就是按字元的ASCII碼逐一比較兩字串。
CharSequence介面是所有字元序列的父介面,String、StringBuffer、StringBuilder等字元序列均實現了此介面。該介面定義了對字元序列對基本操作,具體如下:
int length();
char charAt(int index);
CharSequence subSequence(int start, int end);
public String toString();
public default IntStream chars(){}
public default IntStream codePoints() {}前面幾個介面定義獲取長度、隨機讀取字元、獲取子序列的方法,後兩個是java8的default方法,提供關於Stream的操作,這裡暫且不管。
方法彙總
String類有字元操作的各種方法。我們先對其進行分類,再一一分析其用途。
1. 建構函式
public String() :空建構函式
public String(byte[ ] bytes):通過byte陣列構造字串物件。
public String(byte bytes[], String charsetName)
public String(byte byte public String(byte bytes[], int offset, int length)s[], Charset charset)
public String(char[ ] value):通過char陣列構造字串物件。
public String(char value[], int offset, int count)
public String(StringBuffer buffer):通過StringBuffer陣列構造字串物件。
public String(StringBuilder builder): 通過StringBuilder陣列構造字串物件。 關於建構函式大致就這幾類:除了預設建構函式外、還有通過char[]、byte[]、String、StringBuffer、StringBuilder作為引數的建構函式。(這些引數的其他版本沒有全部列出)。
1⃣️ 通過char[]構造字串
字串內部由char[]表示,使用它作為引數構造理所當然。
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}// Arrays.copyOf
public static char[] copyOf(char[] original, int newLength) {
char[] copy = new char[newLength]; //建立了新char[]陣列
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength)); //將資料拷貝到新陣列
return copy; //返回新陣列。
} 可見String(char value[]) 建構函式不會使用傳進來的char[],而是新建一個char[]並返回。這樣即使改變了引數char[],也不會影響String。如以下示例:
//示例1
public class StringTest {
public static void main(String[] args) {
final char[] value = {'a', 'b', 'c'};
String str =new String(value);
value[0]='b'; //傳入陣列改變
System.out.println(str); //abc ,字串不變
}
}System.arraycopy是一個native`方法,基本功能就是複製陣列。暫且不管。
2⃣️通過StringBuffer和StringBuilder構造
String 、StringBuffer、 StringBuilder 同屬CharSequence介面的實現類。內部表示也均使用char[]。StringBuffer和StringBuilder可以理解為可變的字串版本。只是前者同步而後者非同步而已。
public String(StringBuffer buffer) {
synchronized(buffer) {
this.value = Arrays.copyOf(buffer.getValue(), buffer.length());
}
}StringBuilder與此相似,只是沒有synchronized塊。Arrays.copyOf()表明仍然是重新建立char[]後複製返回。
看了以上3種字串的構造方式,你可能會疑問,為什麼它們都要重新複製一份char陣列而不是直接利用引數傳來的呢?比如這樣:
public String(char value[]) {
this.value =value;
}
原因其實就是我們前面說的,保持String的不可變性。如果按上面這樣寫,在外面改變了char[]陣列,String也會跟著改變。那上面的示例1最後String會變成bbc,這樣的String不是我們需要的。
3⃣️用String物件初始化
有一點例外的是,使用String引數構造String時直接使用此String引數,這是利用了String本身的不可變性。
public String(String original) {
//將引數字串的char[]和hash直接賦給目標String
this.value = original.value;
this.hash = original.hash;
}引數original本身不可變,所以這樣寫是安全的。
你可能會以為,這樣構造的話兩個字串豈不共用同一塊char[]陣列?
可以進行測試
public static void main(String[] args) {
String str1 = new String("abc");
String str2 = new String(str1);
System.out.println(str1 == str2);
}輸出結果為false,我當時很奇怪,這是為什麼?
後來瞭解java記憶體模型後才知道:
- 這樣構造的確共用同一塊char陣列。
- new關鍵字表明為物件新建立記憶體空間(準確說是在java堆中建立物件)。
於是上述記憶體模型就像這樣:
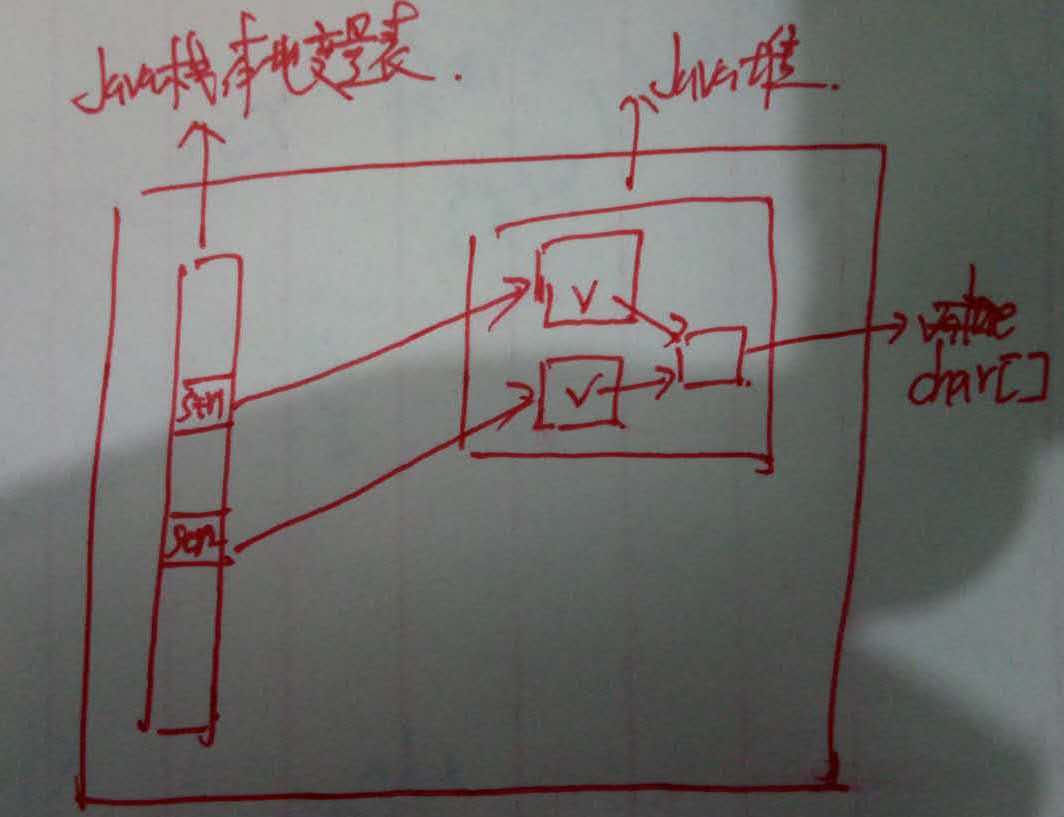
兩個字串引用指向兩塊不同的記憶體空間,str1==str2必定為false。而字串內部的char[] 陣列(圖中的v)指向同一塊char[]陣列。
4⃣️使用byte[]構造String
提到位元組陣列,就不能不提編碼了。事實上,編碼解碼大多是針對byte[]與char[]進行的。這是不做詳細介紹,可以看深入分析 Java 中的中文編碼問題。將char[]按一定規則轉為byte[]為編碼,將byte[]轉為char[]為解碼。編碼解碼必須使用同一套字符集,否則會出現亂碼。
public void test()throws Exception {
String str ="abc";
byte [] bytes = {48,57,65,97}; //用不大於127的數字構造位元組陣列
String str1 = new String(bytes,"ASCII"); // 指定編碼集
System.out.println("str1 = " + str1); // 09Aa
String str3 = "你好,世界!";
byte[] bytes2 = str3.getBytes("UTF-8"); //獲取一句漢字位元組陣列
String str_zh = new String(bytes2,"UTF-8");
String str_zh2 = new String(bytes2,"ISO-8859-1");
System.out.println("str_zh = " + str_zh); //你好,世界!
//編碼解碼不一致,會出現亂碼
System.out.println("str_zh2 = " + str_zh2); //ä½ å¥½ï¼Œä¸–ç•Œï¼
//用不支援中文的字符集編碼,也會有亂碼
byte [] bytes3 = str3.getBytes("ASCII");
String str_zh3 = new String(bytes3,"ASCII");
System.out.println("str_zh3 = " + str_zh3); //??????
}知識點:
1. new String(byte[],String)或new String(byte[]) 等方法將位元組陣列轉為字串。getBytes(String)將字串轉為位元組陣列。
2. 編碼和解碼的字符集要一致,否則會出現亂碼。
2. 重寫的Object方法(equals和hashCode)
String 重寫了equals()方法和hashCode方法。
對於equals() 是逐一比較每個字元,若都相等則為真否則為假。
//String 的equals()原始碼
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}對於hashCode方法,使用公式s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]。使用31作為基數的原因在於31是素數。解釋在stackoverflow
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}3 . indexOf()及lastIndexOf()方法
indexOf系列的公共方法有:
indexOf(int ch)
indexOf(int ch,int fromIndex)
indexOf(String str)
indexOf(String str,int fromIndex)lastIndexOf(int ch)
lastIndexOf(int ch,int fromIndex)
lastIndexOf(String str)
lastIndexOf(String str,int fromIndex)
indexOf()系列功能為根據單個字元或一段字串求出其在整字串第一次的索引位置,若不存在則為-1。
public int indexOf(int ch, int fromIndex) {
final int max = value.length; //字串長度
if (fromIndex < 0) { //fromIndex,從字串哪裡查起
fromIndex = 0;
} else if (fromIndex >= max) {
// Note: fromIndex might be near -1>>>1.
return -1;
}
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) {
// handle most cases here (ch is a BMP code point or a
// negative value (invalid code point))
final char[] value = this.value;
for (int i = fromIndex; i < max; i++) {
if (value[i] == ch) {
return i;
}
}
return -1;
} else {
return indexOfSupplementary(ch, fromIndex);
}
}indexOf(String str)內部實現。
source 表示源字串,sourceOffset源字串起始位置,sourceCount源字串長度, 即可對源字串擷取
target目標字串,targetOffset目標字串起始位置,targetCount目的字串長度。fromIndex從擷取後的源字串的指定索引查詢。
public int indexOf(String str, int fromIndex) {
return indexOf(value, 0, value.length,
str.value, 0, str.value.length, fromIndex);
}static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
if (fromIndex >= sourceCount) {
return (targetCount == 0 ? sourceCount : -1);
}
if (fromIndex < 0) {
fromIndex = 0;
}
if (targetCount == 0) {
return fromIndex;
}
char first = target[targetOffset]; //獲取目標字串第一個字元,以下先查找出第一個字元,若存在則繼續比較
int max = sourceOffset + (sourceCount - targetCount); //max = 源字串長度-目標字串長度
for (int i = sourceOffset + fromIndex; i <= max; i++) {
/* 查詢第一個字元. */
if (source[i] != first) {
while (++i <= max && source[i] != first);
}
/* 匹配到第一個字元,開始試圖匹配目的字串其他字元*/
if (i <= max) {
int j = i + 1; //從第二字元開始
int end = j + targetCount - 1;
//第二次比較
for (int k = targetOffset + 1; j < end && source[j] == target[k]; j++, k++);
if (j == end) { //如果全部比完
/* Found whole string. */
return i - sourceOffset;
}
}
}
return -1;
}上述演算法可普遍應用於從大字串查詢小字串的情景中。基本思路就是先查詢小字串的首字元,若找到則繼續查詢剩下的字元。
lastIndexOf()演算法與此類似,只是從後向前查詢。
後記:本來想一篇寫完的,沒想到廢話有點多(只是想說清楚啊=_=),居然寫這麼長了。只好分2篇了,餘下那篇抽空補上吧。
祝大家雙十一(☆☆)Y(^^)Y……