
MatLab建模學習筆記6——資料擬合方法
曲線擬合也叫曲線逼近,只要求擬合曲線能合理的反映資料的基本趨勢,並不要求曲線一定通過資料點。曲線擬合有不同的判別準則,包括偏差的絕對值之和最小、偏差的最大絕對值最小和使偏差的平方和最小(即最小二乘法)。
一、多項式的資料擬合:
polyfit(X,Y,N):多項式擬合,返回降冪排列的多項式係數。其中X、Y是資料點的值,N代表最高次冪。
polyval(P,XI):代表返回的多項式係數。其中,P代表多項係數,XI代表要求點的橫座標數值。
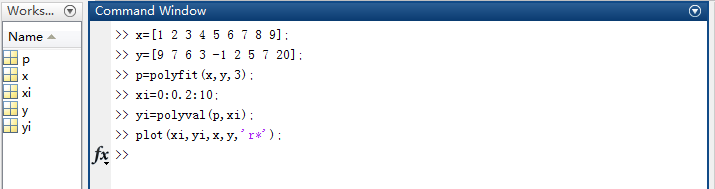
擬合結果如下:
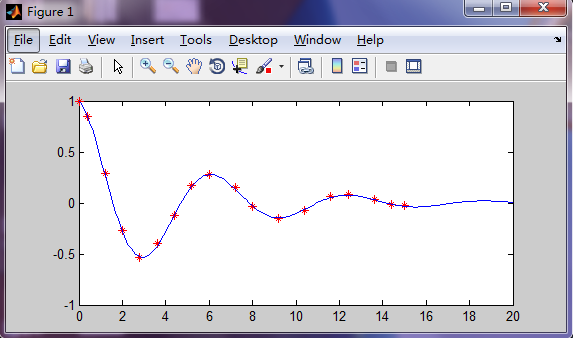
二、圖形視窗中的多項式擬合:
在命令列中輸入:cftool命令可以開啟圖形擬合視窗介面。
左側X和Y分別選中剛剛在命令介面中定義的X和Y資料,在Degree中選擇擬合最高次冪,可在下面觀察到擬合曲線的變化情況。
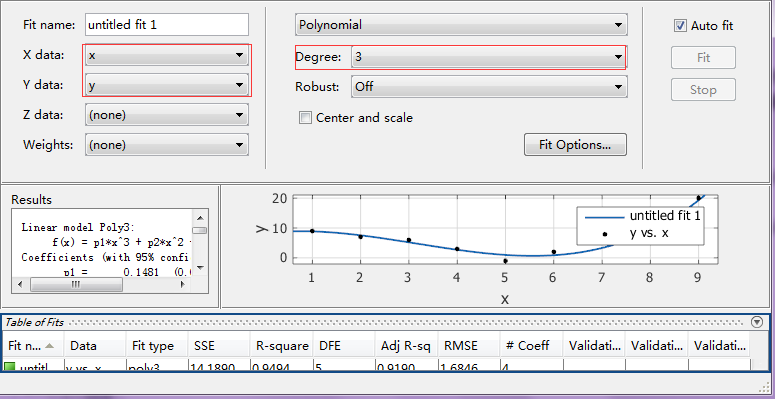
三、指定函式的擬合:
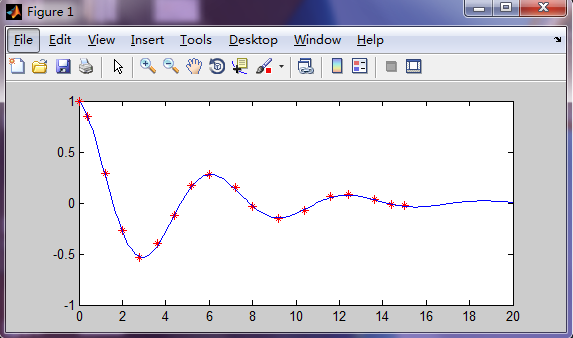
這裡以函式:f(t)=acos(kt)*exp(wt)作為擬合函式
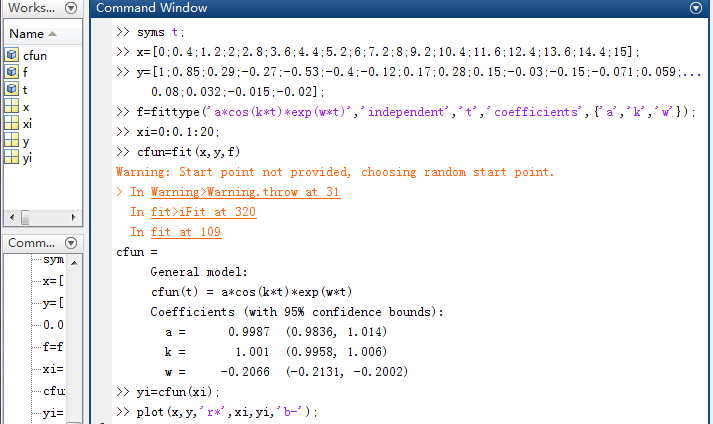
擬合結果如下:
相關推薦
MatLab建模學習筆記6——資料擬合方法
曲線擬合也叫曲線逼近,只要求擬合曲線能合理的反映資料的基本趨勢,並不要求曲線一定通過資料點。曲線擬合有不同的判別準則,包括偏差的絕對值之和最小、偏差的最大絕對值最小和使偏差的平方和最小(即最小二乘法)。 一、多項式的資料擬合: polyfit(X,Y,N):
機器學習筆記2—— 欠擬合與過擬合
區域性加權迴歸 現在思考關於根據實數 x 預測 y 的問題。 上圖中最左側的圖顯示了函式 y=θ0+θ1x 擬合數據集的結果。我們可以看到資料並沒有真的停靠在直線上,所以這種擬合效果並不是非常好。 相反地,如果我們新增額外的特徵 x2,然後用函式擬
MatLab建模學習筆記14——K-Means聚類演算法
網際網路的發展帶動雲端計算、虛擬化、大資料等IT新技術的興起,各行各業的網際網路化日趨明顯。其中大資料的興起和發展壯大成為了IT時代或者說資訊時代最為典型的特徵之一。僅就大資料本身而言,其本身就具有資料體積大、資料多樣性、價值密度低、資料更新快等特點。所以,要想
MatLab建模學習筆記9——二次規劃問題求解
非線性規劃的目標函式自變數為x的二次函式約束條件又全是線性的,則稱之為二次規劃。二次規劃的在Matlab中的數學模型可表述如下: 其中,f和b是列向量,A是相應維數的矩陣,H是實對稱矩陣。Matlab中求解二次規劃的命令是:[X,FVAL]=QUADPRO
神經網路與深度學習 筆記5 過度擬合和正則化
1.過擬合 模型複雜而訓練樣本不足,過度訓練,會導致過度擬合。 訓練資料集上的代價表現是越來越好的,測試集上的代價越來越差。訓練資料上的分類準確率一直在提升接近 100%,而測試準確率僅僅能夠達到 82.27%。 網路幾乎是在單純記憶訓練集合,而沒有對數字本質進行理解能
MatLab建模學習筆記12——Logistic迴歸模型
logistic regression屬於概率型非線性迴歸,它是研究二分類觀察結果與一些影響因素之間關係的一種多變數分析方法。例如,在流行病學研究中,經常需要分析疾病與各危險因素之間的定量關係,為了正確說明這種關係,需要排除一些混雜因素的影響。對於線性迴歸分析,
MatLab建模學習筆記3——MatLab工具箱
1.平面操作工具箱 MATLAB Toolboxes The DSS package for MATLAB DSS Matlab package contains algorithms
機器學習的防止過擬合方法
alt int 變化 http 處理 提高 pro 無法 structure 過擬合 ??我們都知道,在進行數據挖掘或者機器學習模型建立的時候,因為在統計學習中,假設數據滿足獨立同分布(i.i.d,independently and identically distribu
機器學習中防止過擬合方法
從數據 tro 輸出 效果 沒有 imagenet neu 效率 公式 過擬合 ??在進行數據挖掘或者機器學習模型建立的時候,因為在統計學習中,假設數據滿足獨立同分布,即當前已產生的數據可以對未來的數據進行推測與模擬,因此都是使用歷史數據建立模型,即使用已經產生的數據去訓練
MATLAB資料擬合工具在數學建模中的運用
1.問題描述 下表是由中國國家統計局提供的《50個城市主要食品平均價格變動情況》整理得到的2016年1月到5月豆角價格資料表,請建立數學模型解決下來兩個問題: (1)豆角價格有什麼特點? (2)對6月
誰說菜鳥不會資料分析(入門篇)----- 學習筆記6(資料分析報告)
1、資料分析報告:三大作用四項基本原則 定義 是根據資料分析原理和方法,運用資料來反映、研究和分析某項事物的現狀、問題、原因、本質和規律,並得出結論,提出解決辦法的一種分析應用文體。 這種文體是決策者認識事物、瞭解事物、
Android學習筆記6-跨程式共享資料-ContentProvider
1,內容提供器簡介 1,內容提供器(ContentProvider) 主要用於在不同的應用程式之間實現資料共享額功能,它提供了一套完整的機制,允許一個程式訪問另一個程式的資料,同時保證被訪問的資料的安全性。 2,使用內提供器是Android實現跨程式共享資料的標
python學習筆記--6.python中的matlab矩陣
這是在學習Python的時候做的筆記,有些時間了,大概是按照一本挺實用的入門書籍學的,我學習程式設計的思路一般是掌握基礎的變數型別,語法-分支結構 函式呼叫 類建立 結構體定義,記錄一些簡單的例項,剩下的就是需要用什麼百度現學。 對我來說python的優勢是,
Java 8 學習筆記6——用流收集資料
流可以用類似於資料庫的操作幫助你處理集合。你可以把Java 8的流看作花哨又懶惰的資料集迭代器。它們支援兩種型別的操作:中間操作(如filter或map)和終端操作(如count、findFirst、forEach和reduce)。中間操作可以連結起來,將一個流轉換為另一個流。這些操作不會消
caffe學習筆記6--訓練自己的資料集
這一部分記錄下如何用caffe訓練自己的資料集,這裡使用AlexNet的網路結構。 該結構及相應的solver檔案在CAFFE/models/bvlc_alexnet目錄下,使用train_val.prototxt和solver.prototxt兩個檔案 首先,在$CAFF
用Python開始機器學習(3:資料擬合與廣義線性迴歸)
機器學習中的預測問題通常分為2類:迴歸與分類。簡單的說迴歸就是預測數值,而分類是給資料打上標籤歸類。本文講述如何用Python進行基本的資料擬合,以及如何對擬合結果的誤差進行分析。本例中使用一個2次函式加上隨機的擾動來生成500個點,然後嘗試用1、2、100次方的多項式對該資
【資料探勘概念與技術】學習筆記6-挖掘頻繁模式、關聯和相關性:基本概念和方法(編緝中)
頻繁模式是頻繁地出現在資料集中的模式(如項集、子序列或子結構)。頻繁模式挖掘給定資料集中反覆出現的聯絡。“購物籃”例子,想象全域是商店中商品的集合,每種商品有一個布林變數,表示該商品是否出現。則每個購物籃可以用一個布林向量表示。分析布林向量,得到反映商品頻繁關聯或同時購買的購買模式。這些模式可用關聯規則來表示
MATLAB資料擬合
MATLAB中資料擬合 資料擬合的目的是使用一個較為簡單的函式去逼近一個複雜的、未知的函式,在MATLAB中資料擬合的原理是最小擬合的最小二乘原理,其中polyfit與polyval是最基本的擬合方法,除此之外,MATLAB還提供了更為直接簡單的資料擬合工具,
Neural Network Toolbox使用筆記1:資料擬合
Neural Network Toolbox為各種複雜的非線性系統的建模提供多種函式和應用程式。該工具箱提供各種監督學習模型:前向反饋,徑向基核函式和動態網路等模型。同時也提供自組織圖和競爭層結構(competitive layers)的非監督學習模型。該工具箱具有設計、訓
Hinton Neural Networks課程筆記3e:如何利用梯度值訓練網路(學習策略和過擬合抑制)
這裡只是開了個頭,籠統的講了講如何利用梯度值訓練網路,包括優化演算法的部分以及防止過擬合的部分。 1. 優化演算法的部分 這裡只提到了三個部分(具體要到第六節才講):batch相關的抉擇、學習率相關的選擇、優化演算法的選擇。 batch相關的選項有