
深度學習-深度信念(置信)網路(DBN)-從原理到實現(DeepLearnToolBox)
深度信念網路,DBN,Deep Belief Nets,神經網路的一種。既可以用於非監督學習,類似於一個自編碼機;也可以用於監督學習,作為分類器來使用。
從非監督學習來講,其目的是儘可能地保留原始特徵的特點,同時降低特徵的維度。從監督學習來講,其目的在於使得分類錯誤率儘可能地小。而不論是監督學習還是非監督學習,DBN的本質都是Feature Learning的過程,即如何得到更好的特徵表達。
作為神經網路,神經元自然是其必不可少的組成部分。DBN由若干層神經元構成,組成元件是受限玻爾茲曼機(RBM)。
首先來了解一下受限玻爾茲曼機(RBM):
RBM是一種神經感知器,由一個顯層和一個隱層構成,顯層與隱層的神經元之間為雙向全連線。如下圖所示:
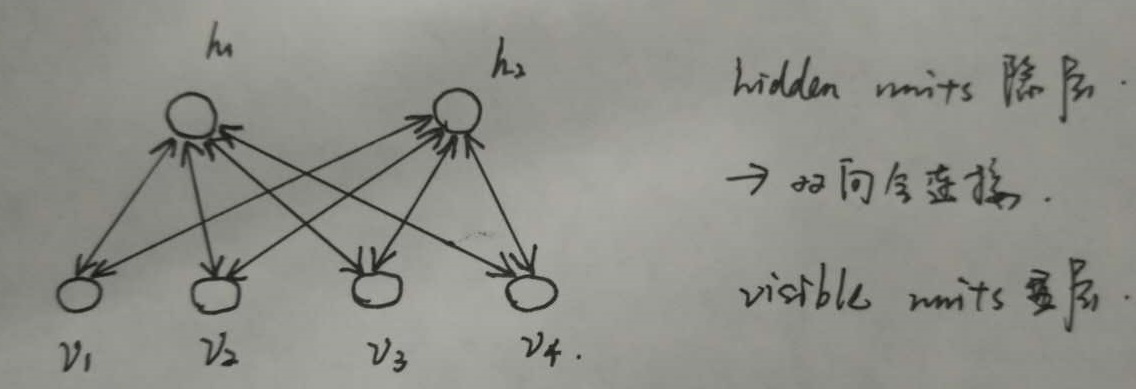
在RBM中,任意兩個相連的神經元之間有一個權值w表示其連線強度,每個神經元自身有一個偏置係數b(對顯層神經元)和c(對隱層神經元)來表示其自身權重。
這樣,就可以用下面函式表示一個RBM的能量:
在一個RBM中,隱層神經元hj被啟用的概率:
P(hj|v)=σ(bj+ΣiWi,jxi)(2)
由於是雙向連線,顯層神經元同樣能被隱層神經元啟用:
P(vi|h)=σ(ci+ΣjWi,jhj)(3)
其中,σ 為 Sigmoid 函式,也可以設定為其他函式。
值得注意的是,當σ 為線性函式時,DBN和PCA(主成分分析)是等價的。
同一層神經元之間具有獨立性,所以概率密度亦然滿足獨立性,故得到下式:
P(h|v)=ΠNhj=1P(hj|v)(4)
P(v|h)=ΠNvi=1P(vi|h)(5)
以上即為受限玻爾茲曼機(RBM)的基本構造。其結構並不複雜。下面來看看它的工作原理:
當一條資料(如向量x)賦給顯層後,RBM根據(3)式計算出每個隱層神經元被開啟的概率P(hj|x),j=1,2,...,Nh,取一個0-1的隨機數μ作為閾值,大於該閾值的神經元則被啟用,否則不被啟用,即:
由此得到隱層的每個神經元是否被啟用。
給定隱層時,顯層的計算方法是一樣的。
瞭解工作原理之後就可以看看RBM是如何通過資料學習的了:
RBM共有五個引數:h、v、b、c、W,其中b、c、W,也就是相應的權重和偏置值,是通過學習得到的。(v是輸入向量,h是輸出向量)
對於一條樣本資料x,採用對比散度演算法對其進行訓練:
- 將x賦給顯層v1,利用(2)式計算出隱層中每個神經元被啟用的概率P(h1|v1)$;
- 從計算的概率分佈中採取Gibbs抽樣抽取一個樣本: h1∼P(h1|v1)
- 用h1重構顯層,即通過隱層反推顯層,利用(3)式計算顯層中每個神經元被啟用的概率P(v2|h1);
- 同樣地,從計算得到的概率分佈中採取Gibbs抽樣抽取一個樣本: v2∼P(v2|h1)
- 通過v2再次計算隱層中每個神經元被啟用的概率,得到概率分佈P(h2|v2)
- 更新權重:
b←b+λ(v1−v2)
c←c+λ(h1−h2)
若干次訓練後,隱層不僅能較為精準地顯示顯層的特徵,同時還能夠還原顯層。當隱層神經元數量小於顯層時,則會產生一種“資料壓縮”的效果,也就類似於自動編碼器。
深度置信網路(DBN):
將若干個RBM“串聯”起來則構成了一個DBN,其中,上一個RBM的隱層即為下一個RBM的顯層,上一個RBM的輸出即為下一個RBM的輸入。訓練過程中,需要充分訓練上一層的RBM後才能訓練當前層的RBM,直至最後一層。
很多的情況下,DBN是作為無監督學習框架來使用的,並且在語音識別中取得了很好的效果。
若想將DBM改為監督學習,方式有很多,比如在每個RBM中加上表示類別的神經元,在最後一層加上softmax分類器。也可以將DBM訓出的W看作是NN的pre-train,即在此基礎上通過BP演算法進行fine-tune。實際上,前向的演算法即為原始的DBN演算法,後項的更新演算法則為BP演算法,這裡,BP演算法可以是最原始的BP演算法,也可以是自己設計的BP演算法。
DBN的實現(DeepLeranToolBox):
這裡是將DBN作為無監督學習框架來使用的,將“學習成果”賦給ANN來完成分類。
訓練集是60000張28*28的手寫數字圖片,測試集是10000張28*28的手寫數字圖片,對應的單幅圖片的特徵維度為28*28=784
% function test_example_DBN
load mnist_uint8;
train_x = double(train_x) / 255;
test_x = double(test_x) / 255;
train_y = double(train_y);
test_y = double(test_y);
%% ex2 train a 100-100 hidden unit DBN and use its weights to initialize a NN
rand('state',0)
%train dbn
%對DBN的初始化
%除了輸入層之外有兩層,每層100個神經元,即為兩個受限玻爾茲曼機
dbn.sizes = [100 100];
%訓練次數
opts.numepochs = 2;
%每次隨機的樣本數量
opts.batchsize = 100;
%更新方向,目前不知道有什麼用
opts.momentum = 0;
%學習速率
opts.alpha = 1;
%建立DBN
dbn = dbnsetup(dbn, train_x, opts);
%訓練DBN
dbn = dbntrain(dbn, train_x, opts);
%至此,已完成了DBN的訓練
%unfold dbn to nn
%將DBN訓練得到的資料轉化為NN的形式
nn = dbnunfoldtonn(dbn, 10);
%設定NN的閾值函式為Sigmoid函式
nn.activation_function = 'sigm';
%train nn
%訓練NN
opts.numepochs = 3;
opts.batchsize = 100;
nn = nntrain(nn, train_x, train_y, opts);
[er, bad] = nntest(nn, test_x, test_y);
assert(er < 0.10, 'Too big error');function dbn = dbnsetup(dbn, x, opts)
%n是單個樣本的特徵維度,784
n = size(x, 2);
%dbn.sizes是rbm的維度,[784 100 100]
dbn.sizes = [n, dbn.sizes];
%numel(dbn.sizes)返回dbn.sizes中的元素個數,對於[784 100 100],則為3
%初始化每個rbm
for u = 1 : numel(dbn.sizes) - 1
%初始化rbm的學習速率
dbn.rbm{u}.alpha = opts.alpha;
%學習方向
dbn.rbm{u}.momentum = opts.momentum;
%第一個rbm是784-100, 第二個rbm是100-100
%對應的連線權重,初始值全為0
dbn.rbm{u}.W = zeros(dbn.sizes(u + 1), dbn.sizes(u));
%用於更新的權重,下同,不再註釋
dbn.rbm{u}.vW = zeros(dbn.sizes(u + 1), dbn.sizes(u));
%第一個rbm是784,第二個rbm是100
%顯層的偏置值,初始值全為0
dbn.rbm{u}.b = zeros(dbn.sizes(u), 1);
dbn.rbm{u}.vb = zeros(dbn.sizes(u), 1);
%第一個rbm是100,第二個rbm是100
%隱層的偏置值,初始值全為0
dbn.rbm{u}.c = zeros(dbn.sizes(u + 1), 1);
dbn.rbm{u}.vc = zeros(dbn.sizes(u + 1), 1);
end
endfunction dbn = dbntrain(dbn, x, opts)
% n = 1;
% x = train_x,60000個樣本,每個維度為784,即60000*784
%n為dbn中有幾個rbm,這裡n=2
n = numel(dbn.rbm);
%充分訓練第一個rbm
dbn.rbm{1} = rbmtrain(dbn.rbm{1}, x, opts);
%通過第一個rbm,依次訓練後續的rbm
for i = 2 : n
%建立rbm
x = rbmup(dbn.rbm{i - 1}, x);
%訓練rbm
dbn.rbm{i} = rbmtrain(dbn.rbm{i}, x, opts);function rbm = rbmtrain(rbm, x, opts)
%矩陣x中的元素必須是浮點數,且取值為[0,1]
assert(isfloat(x), 'x must be a float');
assert(all(x(:)>=0) && all(x(:)<=1), 'all data in x must be in [0:1]');
%m為樣本數量,這裡m = 60000
m = size(x, 1);
%訓練批次,每一批是opts.batchsize個樣本,注意這裡opts.batchsize必須整除m
numbatches = m / opts.batchsize;
%opts.batchsize必須能整除m
assert(rem(numbatches, 1) == 0, 'numbatches not integer');
%opts.numepochs,訓練次數
for i = 1 : opts.numepochs
%隨機打亂1-m的數,也就是1-m的隨機數,kk是1-m的隨機數向量
kk = randperm(m);
%訓練結果的eer
err = 0;
%對每一批資料進行訓練
for l = 1 : numbatches
%取出opts.batchsize個待訓練的樣本
%迴圈結束後所有樣本都進行過訓練,且僅訓練了一次
batch = x(kk((l - 1) * opts.batchsize + 1 : l * opts.batchsize), :);
%賦值給v1
%這裡v1是100*784的矩陣
v1 = batch;
%通過v1計算h1的概率,吉布斯抽樣
h1 = sigmrnd(repmat(rbm.c', opts.batchsize, 1) + v1 * rbm.W');
%通過h1計算v1的概率,吉布斯抽樣
v2 = sigmrnd(repmat(rbm.b', opts.batchsize, 1) + h1 * rbm.W);
%通過v2計算h2的概率,吉布斯抽樣
h2 = sigm(repmat(rbm.c', opts.batchsize, 1) + v2 * rbm.W');
%至此,h1,v1,h2,v2均已計算出來,即完成了對比散度演算法的大半,只剩下相應權重的更新
%權重更新的差值計算
c1 = h1' * v1;
c2 = h2' * v2;
rbm.vW = rbm.momentum * rbm.vW + rbm.alpha * (c1 - c2) / opts.batchsize;
rbm.vb = rbm.momentum * rbm.vb + rbm.alpha * sum(v1 - v2)' / opts.batchsize;
rbm.vc = rbm.momentum * rbm.vc + rbm.alpha * sum(h1 - h2)' / opts.batchsize;
%更新權重
rbm.W = rbm.W + rbm.vW;
rbm.b = rbm.b + rbm.vb;
rbm.c = rbm.c + rbm.vc;
%計算err
err = err + sum(sum((v1 - v2) .^ 2)) / opts.batchsize;
end
%列印結果
disp(['epoch ' num2str(i) '/' num2str(opts.numepochs) '. Average reconstruction error is: ' num2str(err / numbatches)]);
end
endendend
function x = rbmup(rbm, x)
%sigm為sigmoid函式
%通過隱層計算下一層
x = sigm(repmat(rbm.c', size(x, 1), 1) + x * rbm.W');
end對於手寫數字的識別結果還是很好的,即便是最簡單的DBN+NN(如上引數設定),也可以達到95%的正確率。
必備知識來源文章:
DBN文章:
1. A Fast Learning Algorithm for Deep Belief Nets
2. The wake-sleep algorithm for unsupervised neural networks
來源: