
目標檢測:RFCN演算法原理
@改進1:RFCN
論文:R-FCN: Object Detection via Region-based Fully Convolutional Networks 【點選下載】
MXNet程式碼:【Github】
一. 背景介紹
RCNN 在目標檢測上取得了很大的成功,比如 SPPnet、Fast R-CNN、Faster R-CNN 等,這些方法的典型特徵都是 一個二分網路,以 ROI Pooling 為界,前面子網路用於特徵提取,後面子網路用於 目標檢測(Per ROI),帶來的問題是 後面的子網路需要對每一個 ROI(Candidate)進行重複計算
這種模式的形成是有原因的:Detection 來自於前期的分類網路(如 AlexNet、VGG),最後一個 Spatial Pooling 層直觀對應到 RoI Pooling,這算是一個歷史問題。
新提出的幾個網路(ResNet、GoogLeNets)原生就是全卷積網路,因此也就將這種結構天然的對應到 Detection 問題上,想在 ResNet 上實現Detection,需要增加一個 ROI Pooling 層,但插入的位置很關鍵(每個 ROI 候選框對應一次計算,對應 後面子網的計算量 x N):
- 越靠近 Input - 對應 ROI-Wise 檢測子網越深,準確度也就越高;
- 越靠近 Output - 對應 ROI-Wise 子網越淺,針對每個 ROI 計算量就越小,效率提高;
PS:減少 Proposal(ROI)的數量也是一個好辦法,這對 Proposal 的要求會比較高(根據得分排序),先不討論這種思路。

通過上面 可選的方案對比,可以看到 R-CNN 直接輸入 Proposal,因此整個網路都用作檢測,Faster 保留了後面10層用於檢測,而作者新提出的方法則是 將 101 層全部用於共享,那麼這種方案的可行性是怎麼來保證的呢?
二. 提出框架
作者首先分析了 分類/檢測 這兩類問題的區別:
● 分類問題 - 具有平移不變性(Translation Invariance);
● 檢測問題 - 在一定程度上具有平移敏感性 (Translation Variance);
通過 RoI pooling 的插入,打破了原卷積網路的平移不變性,但這種做法犧牲了訓練和測試效率(Region-Wise)。
針對上述問題,作者提出了 一種新的卷積層 - Position Sensitive 的 Score Map,Score Map 包含了位置資訊,如下圖所示:
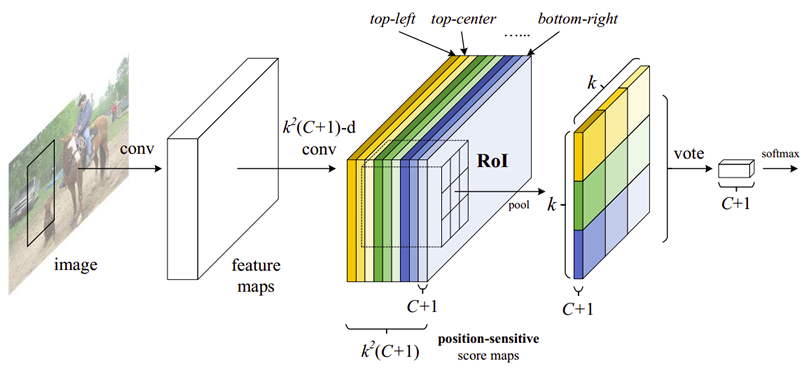
有兩個關鍵層:
1)包含多個 Score Map 的卷積層;
把目標分割成了 k*k 個部分(比如3*3),每個部分對映到一張 Score Map 上,每個 Score Map 對應目標的一部分(如上圖中的 top-left 左上角的 1/9)。
最終得到 k*k 個Score Map,每一個 Map通道數為 分類個數 C+1。
2)一個 ROI Pooling 層;
這個 ROI 層僅針對上面的其中一個 Score Map 執行 Pooling 操作,重新排列成 k*k,通道數為 C+1。
ROI Pooling 層通過 k*k 個 Part 進行投票,得到分類結果。
Score Map 和 ROI Pooling 層的工作方式示意如下:
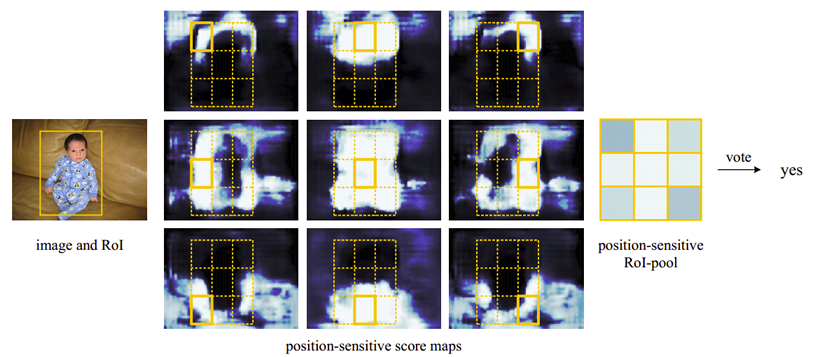
三. 網路結構
R-FCN 沿用了 Faster RCNN 的網路結構,通過 RPN 生成 Proposal,RPN 層與 Detection 共享前面的特徵層:
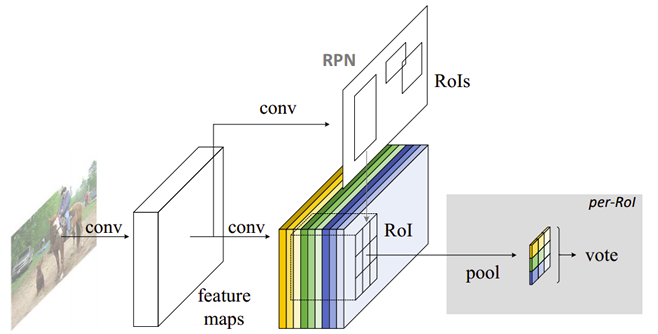
R-FCN 的基礎網路部分是基於 ResNet101 的修改:
1)共享卷積子網
去掉了最後的 average pooling 層和全連線層,並新增了一個卷積層進行降維,共101個卷積層。
2)RPN 子網
與 Faster 一致,沒有變化。
3)檢測分類子網
1個 Score Maps層 + 1個 ROI Pooling層,上一節提到的兩個關鍵層,與 RPN 並聯。
> Scores Map & ROI 具體過程:
Scores Maps 的組合是卷積層的關鍵部分,描述了目標的 Score 資訊,每一個 Score Map 對應目標的一部分,比如 上圖中黃色 Map 始終表示左上角,其 C+1 維通道表示了 分類類別(C個類別+1個背景)。
Pooling 過程:結合 ROI (W‘,H’)來看,bin(Pool之後得到的9個不同的顏色塊) 的尺寸描述為 (W‘/k,H’/k),對於上面的 3*3 的情況,每一個 bin 用公式來描述:
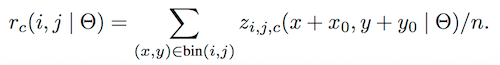
其中 i,j 取值為[0,k),理解為在 ROI 對應的其中一個 Map 上,取樣其中的 1/9,上圖中黃色 Map的取樣範圍始終為左上角,最右側淺藍色始終取樣右下角。
投票過程是(每個類單獨計算)通過多個 bin 求和得到 一個類的 Score,並通過 Softmax 進行分類,Loss 函式定義為:
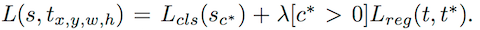
分類 Loss 和 迴歸 Loss 通過一個引數 λ 加權平均,Lreg 同樣採用 L1 Smooth。
四. 實驗結果
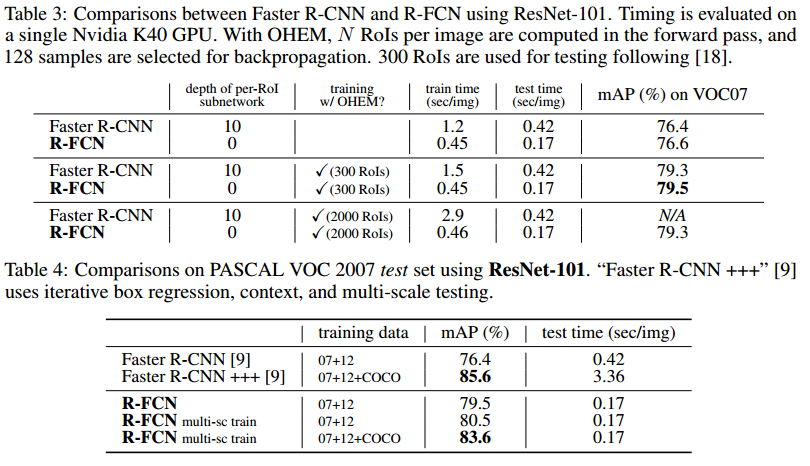
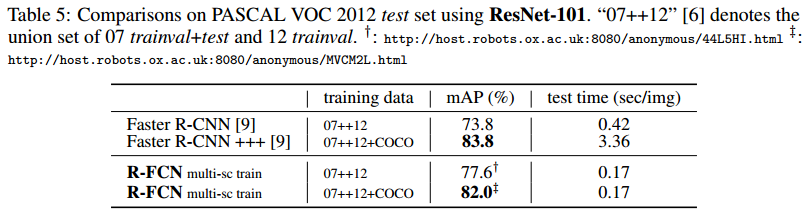
在 VOC07,VOC12,MS COCO 上的測試對比結果,具體的配置和細節可以參考原文,R-FCN 與 Faster R-CNN 的對比,效果幾乎相同,但效率有了成倍的提升。
@改進2:RON
論文:RON: Reverse Connection with Objectness Prior Networks for Object Detection 【點選下載】
Caffe程式碼:【Github】
一. 背景介紹
論文首先闡述了 Region-Based 方法在精確度上的優點,以及 Region-Free 方法在效果上的表現,想結合這兩類方法,提出一種新的方法。
該方法包括三個方面:1)提出一種新的全卷積網路 RON;
第一,通過 Reverse Connection 為前一層 Feature 提供更多語義資訊,第二,Objectness Prior 有效約束了目標搜尋區域,最後,通過多工 Loss 讓整個網路實現 end-to-end 訓練。
2)引入 Negative example mining(副樣本挖掘) 和 data augmentation(資料增強),有效提高檢測效果;
3)有效節約 計算時間 和 計算資源,1.5G視訊記憶體+15fps,比 Faster R-CNN快3倍;
另外,我們還拓展了更多的設計選擇,像不同層的合併,可選的Objectness Prior ,and so on。
這裡面只有 1)算是文章創新,也是本文的核心;
2)頂多算是引入了別人的 Trick,不用考慮;
3)把功能效能搞混了吧,搞學術的童鞋湊數的本領強!
二. 演算法框架
基礎框架為 VGG16,將其中的 FC6,FC7 替換為卷積層,並通過 2*2的卷積核(stride=2)將 FC7 的解析度減半,FC8 未使用。
特徵圖尺寸(基於 input 的縮放比例)分別為:1/8 (conv 4_3), 1/16 (conv 5_3), 1/32 (conv 6) , 1/64 (conv 7)。
Follow 論文組織結構往下看:
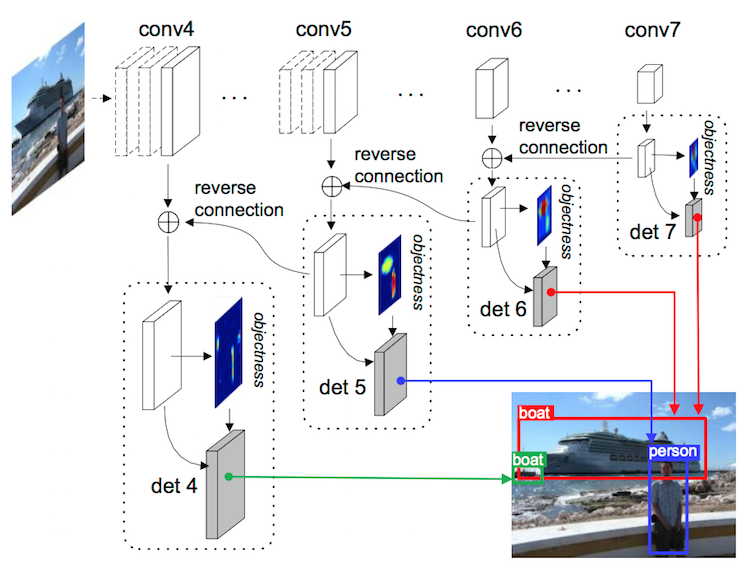
1)Reverse Connection(反向連線)
與作者之前的 HyperNet 一樣,採用 反捲積(Deconv)將當前層的語義資訊反饋到上層,通過一個上取樣與之前層進行 融合。
多尺度資訊能夠對小目標有更好的檢測精度,這一點都有共識了,通過 conv4、5、6、7 各特徵層分別進行檢測。
2)Reference Boxes(參考框)
參考框的提出與 Faster RCNN 裡的 Anchor 類似,這裡採用的是 2個尺度,5種長寬比 {1/3,1/2,1,2,3},對應 10個 Anchor。
尺度公式描述為:
Smin 取值為 Input 尺寸的 1/10,對於 1000*1000的 image,Smin = 100,對應每個特徵圖 k 得到:
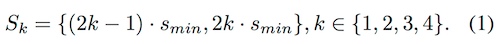
k=1, S1 = (100,200)
k=2, S2 = (300,400)
k=3, S3 = (500,600)
k=4, S4 = (700,800)
3)Objectness Prior(目標先驗)
對應上一節提出的 參考框(default boxes),只有很少一部分框包含目標,其餘大部分都是無效的背景,Region-Based 方法能夠通過預計算來解決這個問題,有效避免每個 Region 帶來的重複計算。作者提出的方法與之不同:
用一個3x3x2的卷積 加 一個 Softmax 來表示每個 Box 裡面是否存在目標。
PS:與 RPN 的區別在於這裡只有一個 2位的 Score(目標Score,背景Score),沒有位置偏移。
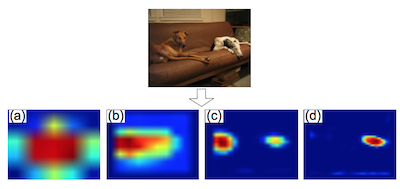
下圖是 Prior 的一個視覺化效果(很明顯地反映有無目標):
圖中對10個目標先驗特徵圖沿通道方向取了平均。
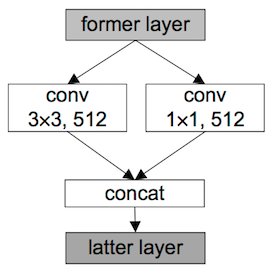
4)Detection and Bounding Box Regression(檢測和邊框迴歸)
與 Objectness Prior 不同,這裡要把目標分為 K+1個類:對應 VOC(20+1) COCO(80+1)。
這裡引入了 inception 模組,看圖說話:
5)Combining Objectness Prior with Detection(結合目標先驗和檢測)
訓練網路時,首先為每個候選區域指定一個二進位制 Label。如果候選區域包含目標,就再指定一個 特定類別 Label。
i)對每一個 Ground Truth Box,找到和它重疊面積最大的候選區域;
ii)對每個候選區域,找到和它重疊面積大於0.5的 Ground Truth;
這種匹配策略保證每一個 Ground Truth 至少有一個候選框與之關聯,重疊比例小於0.3的作為負樣本。
這樣,每一個 Box 有兩個 Label,Objectness(是否為目標) Label,Class Label。訓練的時候網路會根據 Objectness Prior 動態更新 Class Label。
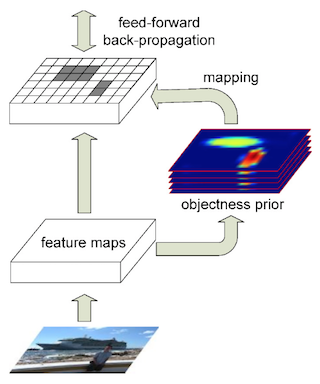
> 前向傳播時,網路首先產生目標先驗,並進行類別檢測。
> 反向傳播時,網路首先會產生目標先驗,然後對於檢測,只會在 Objectness 得分大於某個閾值的區域內進行目標檢測,如下圖所示。
額外的計算僅僅在於為反向傳播選擇訓練樣本。當選擇合適的閾值時(我們選擇閾值為0.03),樣本的數量減少了,這樣反向傳播的時間就縮短了。
三. 訓練及測試結果
● Loss函式:
先來看 Loss 函式定義:
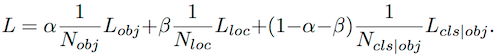
將 目標檢測Loss、定位Loss、分類Loss 組成一個加權 Loss 函式,原文 3個項都為 1/3。
● 訓練過程:
a)對於 Objectness Prior,選擇全部的正樣本,隨機選取負樣本,保證正負樣本的比例為1:3;
b)對於 Detection,首先通過 Objectness Prior Score 減少樣本數量,然後選擇全部的正樣本,隨機選取負樣本,保證正負樣本的比例為1:3;
Faster RCNN 和 RFCN 常常用 Multi Stage 訓練 做聯合優化,相比之下,我們這種端到端的訓練方法更有效率。訓練初期,目標先驗是一片吵雜。隨著訓練的進行,目標先驗圖越來越集中在目標附近。(這一點確實不敢苟同,Multi Stage 的作用保證的是更快收斂)。
● 資料增強:
使用瞭如下策略:
1)使用 原始/翻轉 的Image 做 Input;
2)按照比例 { 0.4, 0.5, 0.6, 0.7, 0.8, 0.9 } 從原圖中 Crop Patch,保證每個 Patch 中包含目標中心;
這些方法可以有效增加大目標數量,對小目標沒有幫助。
針對小目標,通過 Scale 將某個尺度下的大目標變成 較小的尺度下的小目標,這個訓練策略可以避免對特定目標尺寸的過擬合。
● 預測:
每個 Box 的類置信度表示為:
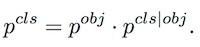
得到目標 Score之後,通過邊框迴歸調整 Box位置,最後用 NMS 得到最終檢測結果。
● 效果對比:
作者分別在 VOC07,VOC12,COCO 資料集上給出了測試結果,我們只貼出來 VOC12 的效果對比:

其他資料集 測試結果都差不多,總體上效果還是不錯的,大家可以跑程式碼之後對比。