
zero-shot learning 論文三篇小結
what is zero-shot learning
zero-shot learning 是為了能夠識別在測試中出現,而在訓練中未遇到過的資料類別。例如識別一張貓的圖片,但在訓練時沒有訓練到貓的圖片和對應貓的標籤。那麼我們可以通過比較這張貓的圖片和我們訓練過程中的那些圖片相近,進而找到這些相近圖片的標籤,再通過這些相近標籤去找到貓的標籤。(個人認為zero-shot learning應該屬於遷移學習的一種。)
論文一 《DeViSE: A Deep Visual-Semantic Embedding Model》
該論文要解決的問題是如何將已有的影象分類模型應用到訓練中未涉及到的影象分類中。例如在模型訓練中,只訓練了老虎,狗,飛機類別的影象,現需要將模型去識別貓的影象,該如何去做呢?
主要思想:該論文將影象的feature vector和NLP的semantic vector結合,進行zero-shot learning,具體看下圖:
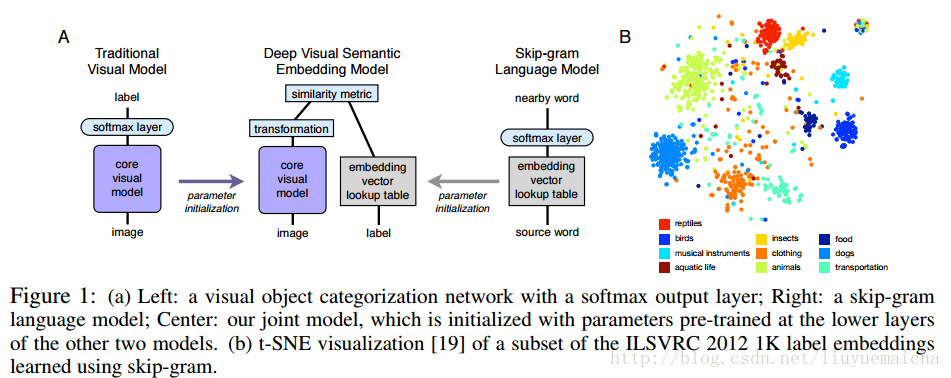
該結構圖是論文的主要特色,author使用word2vec做NLP的vector,將CNN的最後一層softmax 替換為transformation(這裡為linear transformation)做影象的feature vector, 這裡要保證feature vector 和 label vector(word2vec)的dimension一致,最後做feature vector 和label vector的相似度計算。
論文的特色二是使用了hinge rank loss作為loss得計算,公式如下:
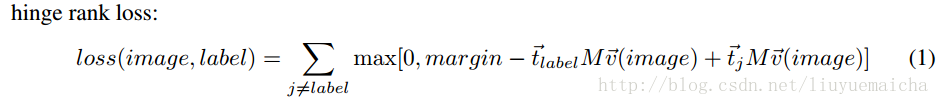
t_label表示label的vector(word2vec計算),v_image表示image的vector(去除softmax layer的cnn計算),M表示linear transformation,margin為超引數。
論文二《Zero-Shot Learning by Convex Combination of Semantic Embeddings》
論文二繼承了論文一的主要思想(CNN+word2vec),但使用了更簡單的方法,從而保留了整個CNN結構,且不需要linear transformation。
公式一:
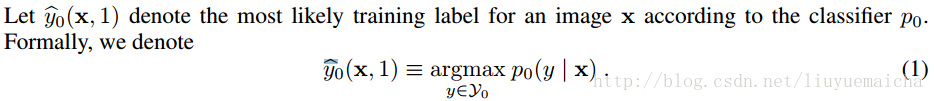
其中x表示image,y表示image的類別,該公式表示image x在模型P_0(即CNN)下預測類別為y的概率。這裡我們可以得到Top N的label y和對應的概率值,作為下面的計算。
公式二:
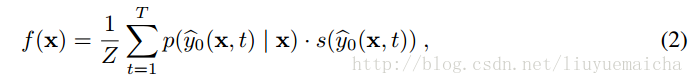
其中T表示Top N,p表示x分類為y的概率,s則為對應y的semantic vector 。Z為正規化因子,公式為
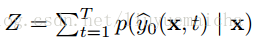
公式三:
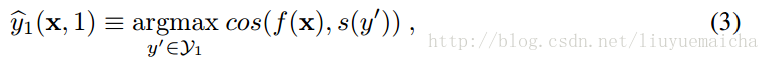
其中f(x)為公式2,s(y’)表示y’的semantic vector,cos表示計算餘弦相似度。
該論文的最大亮點是通過標準CNN求得image x最接近的類別權重(概率),並通過 word2vec獲得類別vector,進行疊加處理,再和測試類別進行相似度計算,進而預測image x的label。
論文三 《Objects2action: Classifying and localizing actions without any video example》
東京時間:0:22:18.77,明天再續……
繼續:
已知在Zero-shot learning中訓練類集合Y與測試類集合Z是沒有交集的,即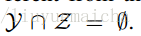
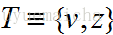
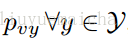
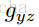
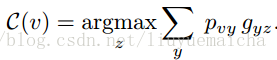
本paper是通過訓練影象來對視訊分類,所以對於視訊測試集,需要將視訊抽樣取幀(10幀一抽樣)。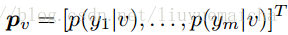
對於semantic embedding的計算,paper試驗了兩種方案:Average Word Vectors 和 Fisher Word Vectors.實驗發現FWV要比AWV效果好。
整體架構:
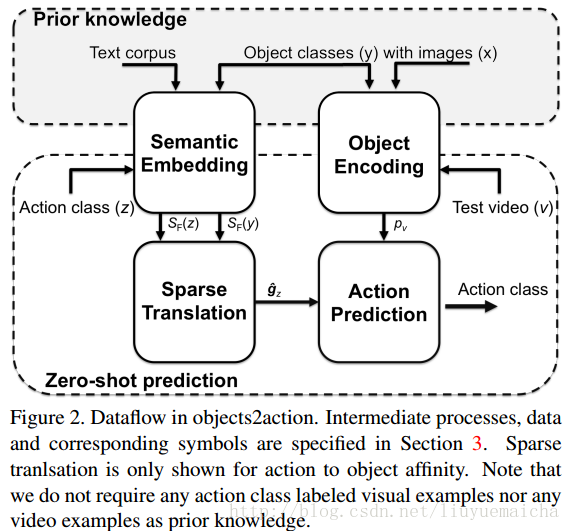
總結:
任何高大上的東西,深諳此道後,都是簡潔清晰。初識Zero-shot learning時,本以為是多麼的高大上,熟悉後原來是用了現有的理論,完成了一件不可思議的事情。