解碼H264檔案的一些基礎知識
這段時間一直在進行編寫H264檔案的解析類,因此對於H264檔案的格式有了初步的瞭解,官方文件也看了個大概。這篇文章主要是總結了一些為解碼H264檔案而需要的一些前期知識,話不多說,下面是乾貨,有些是自己在wiki上翻譯過來的,有些是看官方文件後發現的一些關鍵部分。
首先了解一下視訊檔案中的一些知識:
Video compression picture types(視訊壓縮影象型別)
1. 視訊幀的壓縮使用了不同的演算法,這些應用於視訊幀的不同演算法被稱為影象型別或者幀型別。 a. I - 該幀可壓縮程度最低,也不需要通過其他視訊幀解碼。 b. P - 該幀可以引用前面的幀的資料來解壓縮並且相對於I幀來說,該幀可以壓縮程度更高。 c. B - 該幀可以引用前面的幀和後面的幀的資料,從而壓縮程度最高。

(圖為一段視訊幀,由2個關鍵幀(I-frame),1個向前預測幀(P-frame)和1個雙向預測幀(B-frame)構成)
這裡共有三種類型的幀被用在視訊壓縮技術中:I-幀,P-幀 和 B-幀。
I-幀是一種“內編碼圖片”,實際上是一種資訊十分詳細的圖片,跟傳統的靜態圖片檔案相似。P-幀 和 B-幀 只儲存了部分的圖片資訊,因此相比於I-幀來說,他們需要更少的儲存空間,也因此而提高了壓縮速率。
P-幀(“預測圖片”)只儲存圖片中與前一幀的不同的地方。比如,在一個場景中,汽車行駛在靜止的背景中,只有汽車的運動需要被編碼。編碼器無需儲存未改變的背景畫素資訊到P-幀中,因此而節省了空間,P-幀 也同樣被稱為 delta-幀。
B-幀(“雙向預測圖片”)通過比較現在的幀和前後的幀的不同來指定具體儲存的內容,從而節省了更多的空間。
Slices(條帶)
一個條帶是一個幀中比較獨特的區域,不同於該幀中的其他區域。在最新的國際標準中,這裡已經存在 I-slices(I-條帶),P-slices(P-條帶)和 B-slices(B-條帶)。
Macroblocks(巨集塊)
普遍來說,圖片(幀)被分割成許多巨集塊和個體預測型別能夠在巨集塊層被挑選出來,並且整個圖片(幀)中的巨集塊與巨集塊並不相同,如下:
1. I-幀 只能包含內部巨集塊
2. P-幀 既能包含內部巨集塊,也能包含預測巨集塊
3. B-幀 能包含內部巨集塊,預測巨集塊和雙向預測巨集塊
進一步說,在視訊編解碼H.264中,幀能夠被分割成巨集塊序列,該巨集塊序列被稱為條帶(slices)。編解碼過程不是使用I,B和P 幀型別作為選集,而是通過每個條帶明確無誤的選擇出預測型別。在H.264檔案中也能找到幾個額外的 幀/條帶 型別:
1. SI-幀/條帶(Switching I);使編碼流之間的轉換變得更加容易;包含了 SI-巨集塊(一種內部編碼巨集塊的特殊型別)
2. SP-幀/條帶(Switching P);使編碼流之間的轉換變得更加容易;包含了 P-巨集塊 和/或 I-巨集塊。
3. muti-幀 動態預測(包括16個引用幀,或32個引用域)
Intra coded frames/slices(I-frames/slices or Key frames)(內編碼幀/條帶(I幀/條帶 或者 關鍵幀))
1. I-幀 編碼不依賴於其他幀
2. 可能被編碼器生成並創建於一個隨機訪問點(來允許解碼器在圖片的該位置開始解碼)
3. 當區分圖片細節時也可能為了避免產生有效的 P-幀 或 B-幀 而生成
4. 普遍來說比其他型別的幀需要更多的位數來編碼
通常,I-幀 被用來隨機訪問和作為其他圖片(幀)解碼時的引用。內部重新整理週期通常為半秒(在數字電視廣播和DVD儲存介質中很常見)。在一些環境下,也可能需要更長的時間週期。比如,在視訊會議系統中,通常會間歇的傳送I-幀(不頻繁的傳送)。
Predicted frames/slices(P-frames/slices)(預測幀/條帶(P-幀/條帶))
1. 為了解碼的需要,要優先解碼一些其他圖片(幀)
2. 可能包含影象資料或運動向量偏移量或者兩者的組合
3. 能夠按照解碼順序引用前面的圖片
4. 舊的設計標準在解碼時只使用一張前面的解碼圖片作為引用,並且需要該圖片也要在P-幀圖片之前顯示。
5. 在H.264檔案中,在解碼過程中能夠使用多個先前解碼的圖片作為引用,並且相對於被用來做預測的圖片幀,該幀能夠以任意順序顯示。
6. 通常,相對於編碼I-幀來說,編碼預測幀需要更少的位元位數。
Bi-directional predicted frames/slices(B-frames/slices)(雙向預測幀/條帶(B-幀/條帶))
1. 為了解碼的需要,要優先解碼一些其他圖片(幀)
2. 可能包含影象資料或運動向量偏移量或者兩者的組合
a. 舊的標準有一個關於整個幀的全域性運動補償向量
b. 一些標準關於每個巨集塊都有一個運動補償向量
3. 一些標準允許每個巨集塊使用兩個運動補償向量(雙向預測)
4. 在舊的設計標準中(比如MPEG-2),B-幀從不用來作為其他圖片(幀)的預測引用。因此,B-幀可以用一個稍低質量的編碼(編碼量少的)來完成,因為一些細節的丟失不會對預測後續圖片(幀)的質量帶來影響。
5. 在H.264檔案中,有可能被作為解碼其他圖片(幀)的引用(由編碼器決定)
6. 在舊的設計標準中(比如MPEG-2),在解碼過程中會使用前面的2幀解碼圖片作為引用,並且需要其中一幀在B-幀之前顯示,另外一幀在B-幀之後顯示。
7. 在H.264檔案中,能夠使用1,2或者更多先前解碼的圖片(幀)作為解碼過程中的引用,並且相對於被用來做預測的圖片幀,該幀能夠以任意順序顯示。
8. 通常,相對於編碼I-幀 和 P-幀來說,編碼該幀需要更少的位元位數。
有了已上的基本知識以後,我們已經瞭解到I-幀是關鍵幀,並且是佔空間最多的幀,因為很多資料都是內編碼的,而P-幀是預測幀,需要藉助前面的幀來作為引用,從而得到完整的資料,而B-幀是雙向預測幀,需要藉助前面和後面的幀來作為引用。因此一般來說佔用空間排序:I-幀 > P-幀 > B-幀 (I-幀佔用空間最多)。
對於如何解析幀型別(I,P還是B幀等等),需要用到nal_unit_type這一欄位,在Nalu中它佔據第一個位元組的3~8位,Nalu的第一個位元組(忽略起始碼startcode:0x000001 or 0x00000001)如下:
forbidden_zero_bit: 1 bit
nal_ref_idc: 2 bit
nal_unit_type: 5 bit
官方文件也給出了語義解析,以虛擬碼的形式給出的:

後面的f(1),u(2),u(5)是代表要使用的解析方法,前面加深的粗體forbidden_zero_bit,nal_ref_idc,nal_unit_type稱為syntax_element,語法元素,即:解析這些語法元素要用到後面的f(1),u(2),u(5)方法,下面是官方文件中給出的解析方法:


這裡面的解析方法,個人感覺只有Exp-Golomb-coded的解析有些麻煩(解析具體是什麼幀需要用到該方法),其他的用簡單的幾個位操作就能輕鬆應對了吧,下面講講指數哥倫布編碼的相關資訊:
Exponential-Golomb(universal code):指數哥倫布編碼
以下是wiki上給出的解釋(給翻譯過來的,英文水平不好,請輕噴,thanks)
1. (預設k=0的形式)
a. 將原數加1寫成二進位制形式
b. 將1中的二進位制的位數減一併記下,新增這麼多個0到1中二進位制位數的前面
例子:
0 ⇒ 1 ⇒ 1
1 ⇒ 10 ⇒ 010
2 ⇒ 11 ⇒ 011
3 ⇒ 100 ⇒ 00100
4 ⇒ 101 ⇒ 00101
5 ⇒ 110 ⇒ 00110
6 ⇒ 111 ⇒ 00111
7 ⇒ 1000 ⇒ 0001000
8 ⇒ 1001 ⇒ 0001001
將其推廣到負數範圍表示,方法如下:
(1) 非負整數x≤0對映到偶數-2x上
(2) 正整數x>0對映到奇數2x - 1上
例子:
0 ⇒ 0 ⇒ 1 ⇒ 1
1 ⇒ 1 ⇒ 10 ⇒ 010
−1 ⇒ 2 ⇒ 11 ⇒ 011
2 ⇒ 3 ⇒ 100 ⇒ 00100
−2 ⇒ 4 ⇒ 101 ⇒ 00101
3 ⇒ 5 ⇒ 110 ⇒ 00110
−3 ⇒ 6 ⇒ 111 ⇒ 00111
4 ⇒ 7 ⇒ 1000 ⇒ 0001000
−4 ⇒ 8 ⇒ 1001 ⇒ 0001001
2. 衍生到k階(k≥0)形式
a. 用於編碼更大的數,編碼後形成更少的二進位制位(編碼比較小的數需要使用更多的二進位制位數)
b. 要以k階形式編碼一個非負整數x,方法如下:
i. 以0階方式編碼⌊x/2^k ⌋
ii. 將x取模2^k
等價方式:
i. 使用0階exp-Golomb編碼方式編碼x+2k−1
ii. 從編碼結構中刪除前面的k個0位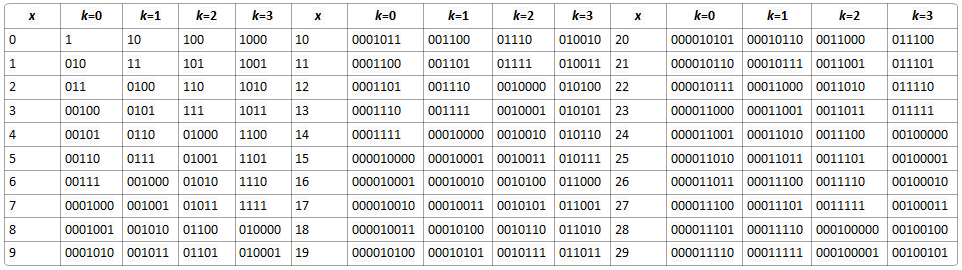
官方文件有關於解析哥倫布指數編碼的方法,of course,仍然是以虛擬碼的形式給出: )

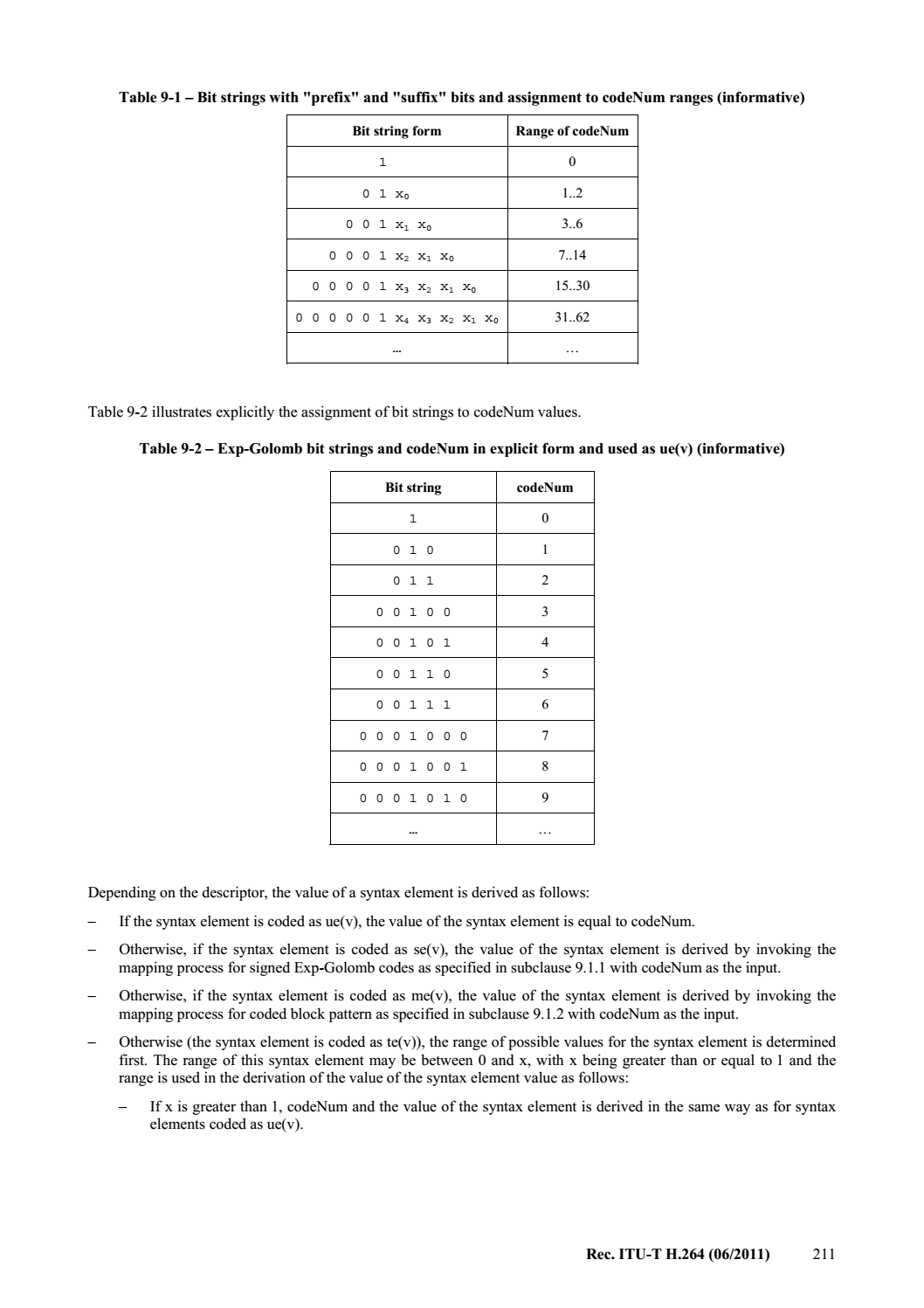

再繼續說解析幀型別的方法…
依然是官方文件….
發現了這麼一個東東
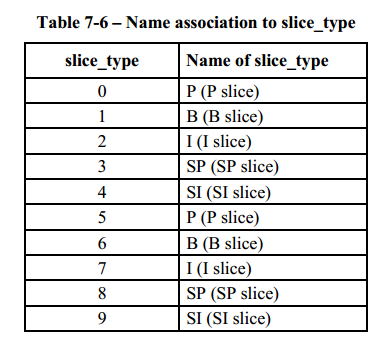
這應該就是我們要分析該Nalu是什麼幀型別的關鍵吧!於是找找它在哪裡出現過

很明顯,第3行出現了,再找找slice_header出現的地方



然後再繼續逆向查詢它們分別出現在哪裡,結果最後都在一張表中找到了
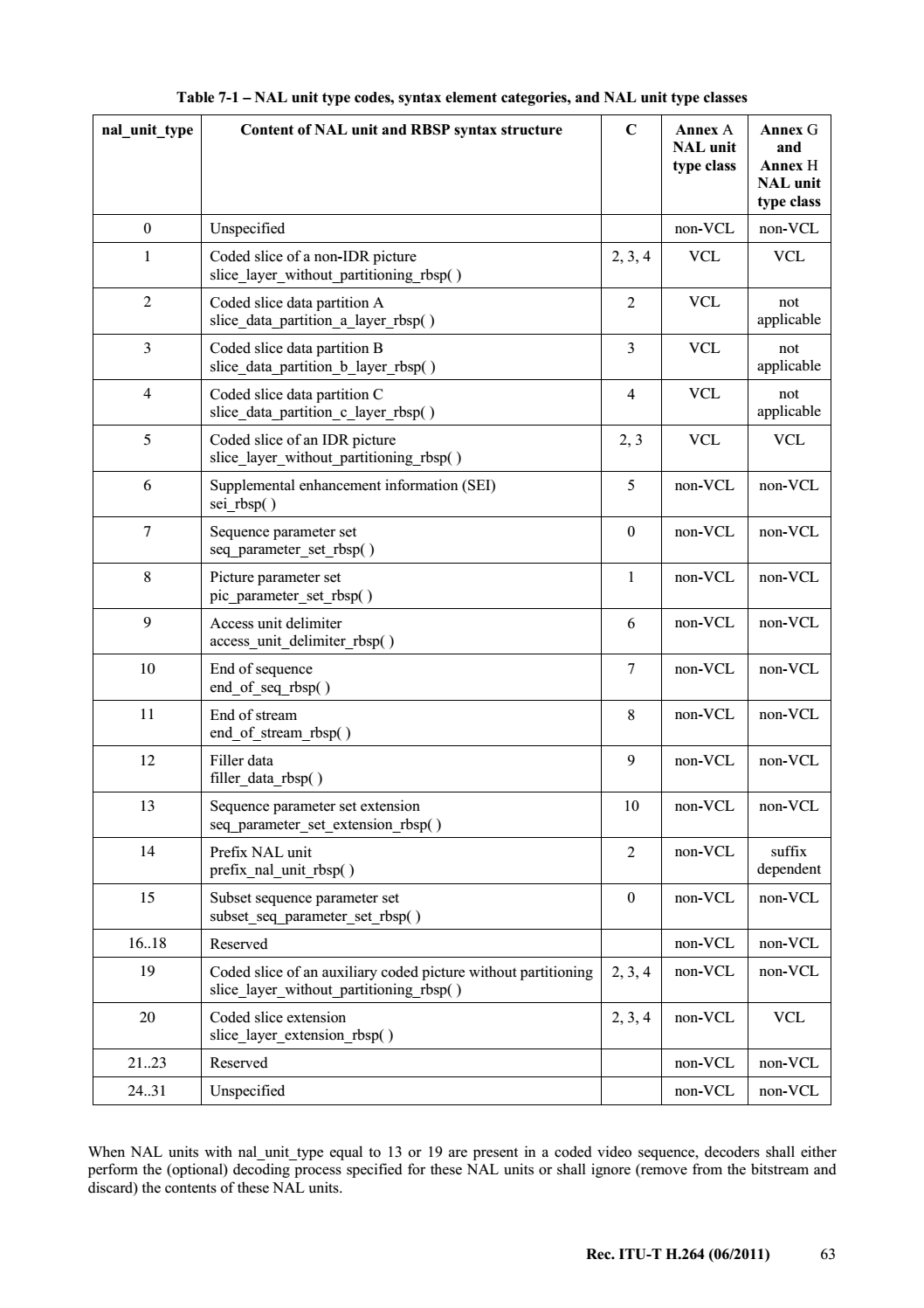
於是開始分析:
- 對於slice_layer_without_partitioning_rbsp:
- nal_unit_type = 1,5,19
- 對於slice_data_partition_a_layer_rbsp:
- nal_unit_type = 2
- 對於slice_layer_extension_rbsp:
- nal_unit_type = 20
於是下面就是具體分析nal_unit_type的值來進行相應處理的過程:
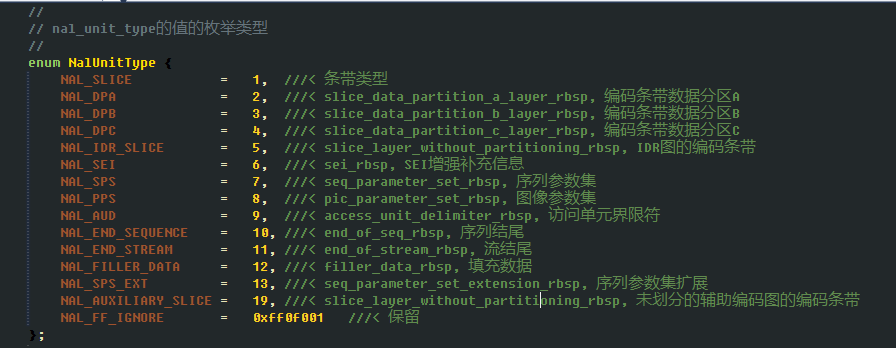
首先,在程式碼中列舉如下NAL單元型別(參考了下ffmpeg)
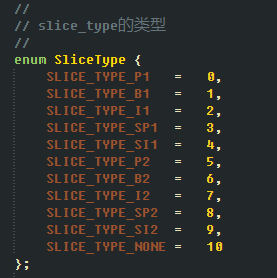
相應的,列舉如下Slice型別,根據Slice型別即能得出幀型別
(具體為什麼要都定義2種,因為根據官方文件來寫的,其實每個第二種型別數值-5即為第一種型別,沒有仔細研究)
具體的解析程式碼在我的GitHub上,歡迎參觀:yijiazhen的GitHub
剛剛接觸H264檔案解析不久,如有分析錯誤或是不到位的地方,懇請各路好漢批評指正,希望可以互相交流,共同提高。
- nal_unit_type = 20