
卡爾曼濾波 -- 從推導到應用(一) 到 (二)
/*************************************************************************************************************************************轉載自:http://blog.csdn.net/heyijia0327,部落格寫的很不錯
/*************************************************************************************************************************************/
前言
卡爾曼濾波器是在估計線性系統狀態的過程中,以最小均方差為目的而推匯出的幾個遞推數學等式,也可以從貝葉斯推斷的角度來推導。
本文將分為兩部分:
第一部分,結合例子,從最小均方差的角度,直觀地介紹卡爾曼濾波的原理,並給出較為詳細的數學推導。
第二部分,通過兩個例子給出卡爾曼濾波的實際應用。其中將詳細介紹一個勻加速模型,並直觀的對比系統狀態模型的建立對濾波的影響。
第一部分
先看一個對理解卡爾曼濾波能起到作用的的笑話:
一片綠油油的草地上有一條曲折的小徑,通向一棵大樹.一個要求被提出:從起點沿著小徑走到樹下.
“很簡單.” A說,於是他絲毫不差地沿著小徑走到了樹下.
現在,難度被增加了:蒙上眼。
“也不難,我當過特種兵。” B說,於是他歪歪扭扭地走到了樹旁。“唉,好久不練,生疏了。” (只憑自己的預測能力)
“看我的,我有 DIY 的 GPS!” C說,於是他像個醉漢似地歪歪扭扭的走到了樹旁。“唉,這個 GPS 沒做好,漂移太大。”(只依靠外界有很大噪聲的測量)
“我來試試。” 旁邊一也當過特種兵的拿過 GPS, 蒙上眼,居然沿著小徑很順滑的走到了樹下。(自己能預測+測量結果的反饋)
“這麼厲害!你是什麼人?”“卡爾曼 ! ”
“卡爾曼?!你就是卡爾曼?”眾人大吃一驚。
“我是說這個 GPS 卡而慢。”
這個小笑話很有意思的指出了卡爾曼濾波的核心,預測+測量反饋,記住這種思想。
-----------------------------------------------------------分割線-----------------------------------------------------------------------
在介紹卡爾曼濾波前,簡單說明幾個在學卡爾曼過程中要用到的概念。即什麼是協方差,它有什麼含義,以及什麼叫最小均方差估計,什麼是多元高斯分佈。如果對這些有了瞭解,可以跳過,直接到下面的分割線。
均方差:它是"誤差"的平方的期望值(誤差就是每個估計值與真實值的差),也就是多個樣本的時候,均方差等於每個樣本的誤差平方再乘以該樣本出現的概率的和。
方差:方差是描述隨機變數的離散程度,是變數離期望值的距離。
注意兩者概念上稍有差別,當你的樣本期望值就是真實值時,兩者又完全相同。最小均方差估計就是指估計引數時要使得估計出來的模型和真實值之間的誤差平方期望值最小。
兩個實變數之間的協方差:
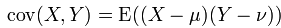
它表示的兩個變數之間的總體誤差,當Y=X的時候就是方差。下面說說我對協方差的通俗理解,先拋去公式中的期望不談,即假設樣本X,Y發生的概率就是1,那麼協方差的公式就變成了:
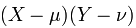
這就是兩個東西相乘,馬上聯想到數值影象裡的相關計算。如果兩個變數的變化趨勢一致,也就是說如果其中一個大於自身的期望值,另外一個也大於自身的期望值,那麼兩個變數之間的協方差就是正值。如果兩個變數的變化趨勢相反,即其中一個大於自身的期望值,另外一個卻小於自身的期望值,那麼兩個變數之間的協方差就是負值。協方差矩陣只不過就是元素多了組成了矩陣,其中協方差矩陣的對角線就是方差,具體公式形式請見wiki。
其實,這種相乘的形式也有點類似於向量投影,即兩個向量的內積。再遠一點,聯想到傅立葉變換裡頻譜系數的確定,要確定一個函式f(x)在某個頻率w上的頻譜,就是<f(x),cos(wt)>,< ,>表示向量內積,通俗的講是將f(x)投影到cos(wt)上,要講清傅立葉的本質需要另寫一篇博文,這裡提到這些只是覺得有益於對知識的相互理解。
高斯分佈:概率密度函式影象如下圖,四條曲線的方差各不相同,方差決定了曲線的胖瘦高矮。(圖片來源:維基百科)
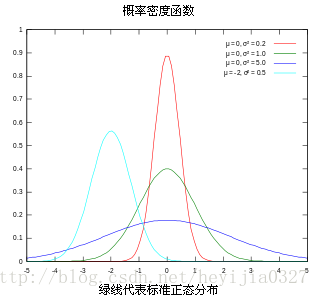
多元高斯分佈:就是高斯分佈的低維向高維的擴充套件,影象如下。
對應多元高斯分佈的公式也請自行谷歌,以前高斯公式中的方差也變成了協方差,對應上面三張圖的協方差矩陣分別如下:
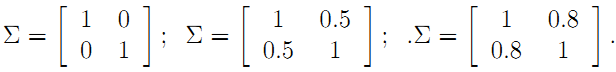
注意協方差矩陣的主對角線就是方差,反對角線上的就是兩個變數間的協方差。就上面的二元高斯分佈而言,協方差越大,影象越扁,也就是說兩個維度之間越有聯絡。
-----------------------------------------------------------分割線---------------------------------------------------------------------
這部分每講一個數學性的東西,接著就會有相應的例子和直觀的分析幫助理解。
首先假設我們知道一個線性系統的狀態差分方程為
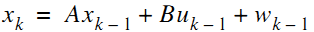
其中x是系統的狀態向量,大小為n*1列。A為轉換矩陣,大小為n*n。u為系統輸入,大小為k*1。B是將輸入轉換為狀態的矩陣,大小為n*k。隨機變數w為系統噪聲。注意這些矩陣的大小,它們與你實際程式設計密切相關。
看一個具體的勻加速運動的例項。
有一個勻加速運動的小車,它受到的合力為 ft , 由勻加速運動的位移和速度公式,能得到由 t-1 到 t 時刻的位移和速度變化公式:
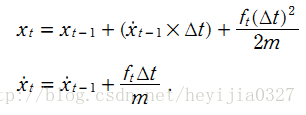
該系統系統的狀態向量包括位移和速度,分別用 xt 和 xt的導數 表示。控制輸入變數為u,也就是加速度,於是有如下形式:

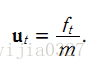
所以這個系統的狀態的方程為:
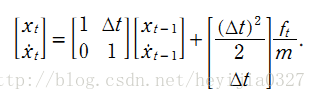
這裡對應的的矩陣A大小為 2*2 ,矩陣B大小為 2*1。
貌似有了這個模型就能完全估計系統狀態了,速度能計算出,位移也能計算出。那還要卡爾曼幹嘛,問題是很多實際系統複雜到根本就建不了模。並且,即使你建立了較為準確的模型,只要你在某一步有誤差,由遞推公式,很可能不斷將你的誤差放大A倍(A就是那個狀態轉換矩陣),以至於最後得到的估計結果完全不能用了。回到最開始的那個笑話,如果那個完全憑預測的特種兵在某一步偏離了正確的路徑,當他站在錯誤的路徑上(而他自己以為是正確的)做下一步預測時,肯定走的路徑也會錯了,到最後越走越偏。
既然如此,我們就引進反饋。從概率論貝葉斯模型的觀點來看前面預測的結果就是先驗,測量出的結果就是後驗。
測量值當然是由系統狀態變數映射出來的,方程形式如下:
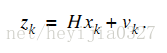
注意Z是測量值,大小為m*1(不是n*1,也不是1*1,後面將說明),H也是狀態變數到測量的轉換矩陣。大小為m*n。隨機變數v是測量噪聲。
同時對於勻加速模型,假設下車是勻加速遠離我們,我們站在原點用超聲波儀器測量小車離我們的距離。
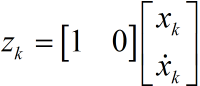
也就是測量值直接等於位移。可能又會問,為什麼不直接用測量值呢?測量值噪聲太大了,根本不能直接用它來進行計算。試想一個本來是朝著一個方向做勻加速運動的小車,你測出來的位移確是前後移動(噪聲影響),只根據測量的結果,你就以為車子一會往前開一會往後開。
對於狀態方程中的系統噪聲w和測量噪聲v,假設服從如下多元高斯分佈,並且w,v是相互獨立的。其中Q,R為噪聲變數的協方差矩陣。
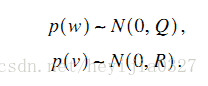
看到這裡自然要提個問題,為什麼噪聲模型就得服從高斯分佈呢?請繼續往下看。
對於小車勻加速運動的的模型,假設系統的噪聲向量只存在速度分量上,且速度噪聲的方差是一個常量0.01,位移分量上的系統噪聲為0。測量值只有位移,它的協方差矩陣大小是1*1,就是測量噪聲的方差本身。
那麼:
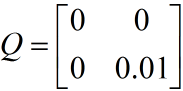
Q中,疊加在速度上系統噪聲方差為0.01,位移上的為0,它們間協方差為0,即噪聲間沒有關聯。
理論預測(先驗)有了,測量值(後驗)也有了,那怎麼根據這兩者得到最優的估計值呢?首先想到的就是加權,或者稱之為反饋。
我們認定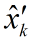
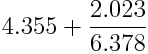

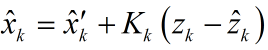
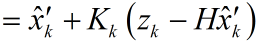
其中,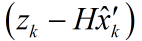
現在的關鍵就是求取這個K。這時最小均方差就起到了作用,順便在這裡回答為什麼噪聲必須服從高斯分佈,在進行引數估計的時候,估計的一種標準叫最大似然估計,它的核心思想就是你手裡的這些相互間獨立的樣本既然出現了,那就說明這些樣本概率的乘積應該最大(概率大才出現嘛)。如果樣本服從概率高斯分佈,對他們的概率乘積取對數ln後,你會發現函式形式將會變成一個常數加上樣本最小均方差的形式。因此,看似直觀上很容易理解的最小均方差理論上來源就出於那裡(詳細過程還請自行谷歌,請原諒,什麼都講的話就顯得這邊文章沒有主次了)。
先看估計值和真實值間誤差的協方差矩陣,提醒一下協方差矩陣的對角線元素就是方差,求這個協方差矩陣,就是為了利用他的對角線元素的和計算得到均方差.
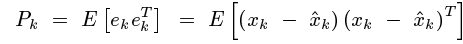
這裡請注意ek是向量,它由各個系統狀態變數的誤差組成。如勻加速運動模型裡,ek便是由位移誤差和速度誤差,他們組成的協方差矩陣。表示如下:
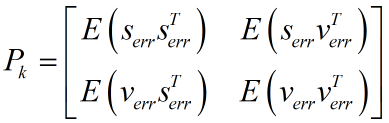
其中,Serr代表位移誤差,Verr代表速度誤差,對角線上就是各自的方差。
把前面得到的估計值代入這裡能夠化簡得:
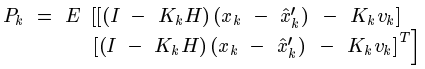
同理,能夠得到預測值和真實值之間誤差的協方差矩陣:
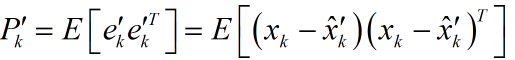
注意到系統狀態x變數和測量噪聲之間是相互獨立的。於是展開(1)式可得:
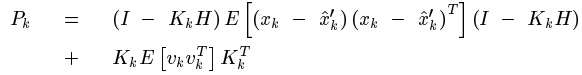
最後得到:
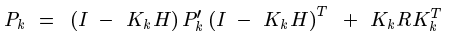
繼續展開:
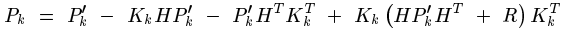
接下來最小均方差開始正式登場了,回憶之前提到的,協方差矩陣的對角線元素就是方差。這樣一來,把矩陣P的對角線元素求和,用字母T來表示這種運算元,他的學名叫矩陣的跡。
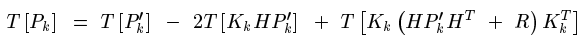
最小均方差就是使得上式最小,對未知量K求導,令導函式等於0,就能找到K的值。
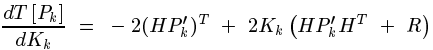
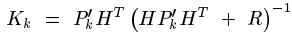
注意這個計算式K,轉換矩陣H式常數,測量噪聲協方差R也是常數。因此K的大小將與預測值的誤差協方差有關。不妨進一步假設,上面式子中的矩陣維數都是1*1大小的,並假設H=1,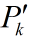
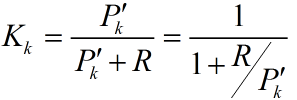
所以
將計算出的這個K反代入Pk中,就能簡化Pk,估計協方差矩陣Pk的:
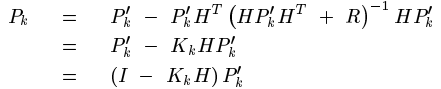
因此遞推公式中每一步的K就計算出來了,同時每一步的估計協方差也能計算出來。但K的公式中好像又多了一個我們還未曾計算出來的東西
請先注意到預測值的遞推形式是:
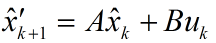
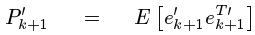
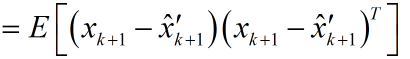
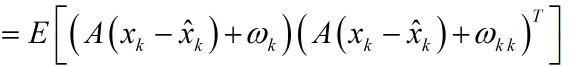
由於系統狀態變數和噪聲之間是獨立,故可以寫成:
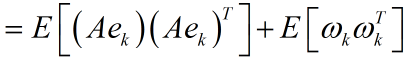
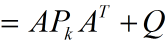
由此也得到了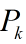
這裡總結下遞推的過程,理一下思路:
首先要計算預測值、預測值和真實值之間誤差協方差矩陣。
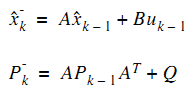
有了這兩個就能計算卡爾曼增益K,再然後得到估計值,
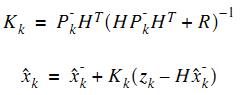
最後還要計算估計值和真實值之間的誤差協方差矩陣,為下次遞推做準備。
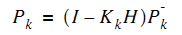
至此,卡爾曼濾波的理論推導到此結束。還有一些如實際應用中狀態方程建立不正確,預測結果會怎樣等這樣的細節問題,以及一些總結留到第二部分討論。
reference:
1.Greg Welch & Gary Bishop. << An Introduction to the Kalman Filter >>
2.Tony Lacey. << Tutorial:The Kalman Filter >>.
3.Ramsey Faragher. << Understanding the Basis of the Kalman Filter Via a Simple and Intuitive Derivation >>
5.很多概念定義來自維基百科
該文是自我總結性文章,有紕漏,請指出,謝謝。 --白巧克力
這部分主要是通過對第一部分中提到的勻加速小車模型進行位移預測。
先來看看狀態方程能建立準確的時候,狀態方程見第一部分分割線以後內容,小車做勻加速運動的位移的預測模擬如下。
- clc
- clear all
- close all
- % 初始化引數
- delta_t=0.1; %取樣時間
- t=0:delta_t:5;
- N = length(t); % 序列的長度
- sz = [2,N]; % 訊號需開闢的記憶體空間大小 2行*N列 2:為狀態向量的維數n
- g=10; %加速度值
- x=1/2*g*t.^2; %實際真實位置
- z = x + sqrt(10).*randn(1,N); % 測量時加入測量白噪聲
- Q =[0 0;0 9e-1]; %假設建立的模型 噪聲方差疊加在速度上 大小為n*n方陣 n=狀態向量的維數
- R = 10; % 位置測量方差估計,可以改變它來看不同效果 m*m m=z(i)的維數
- A=[1 delta_t;0 1]; % n*n
- B=[1/2*delta_t^2;delta_t];
- H=[1,0]; % m*n
- n=size(Q); %n為一個1*2的向量 Q為方陣
- m=size(R);
- % 分配空間
- xhat=zeros(sz); % x的後驗估計
- P=zeros(n); % 後驗方差估計 n*n
- xhatminus=zeros(sz); % x的先驗估計
- Pminus=zeros(n); % n*n
- K=zeros(n(1),m(1)); % Kalman增益 n*m
- I=eye(n);
- % 估計的初始值都為預設的0,即P=[0 0;0 0],xhat=0
- for k = 9:N %假設車子已經運動9個delta_T了,我們才開始估計
- % 時間更新過程
- xhatminus(:,k) = A*xhat(:,k-1)+B*g;
- Pminus= A*P*A'+Q;
- % 測量更新過程
- K = Pminus*H'*inv( H*Pminus*H'+R );
- xhat(:,k) = xhatminus(:,k)+K*(z(k)-H*xhatminus(:,k));
- P = (I-K*H)*Pminus;
- end
- figure
- plot(t,z);
- hold on
- plot(t,xhat(1,:),'r-')
- plot(t,x(1,:),'g-');
- legend('含有噪聲的測量', '後驗估計', '真值');
- xlabel('Iteration');
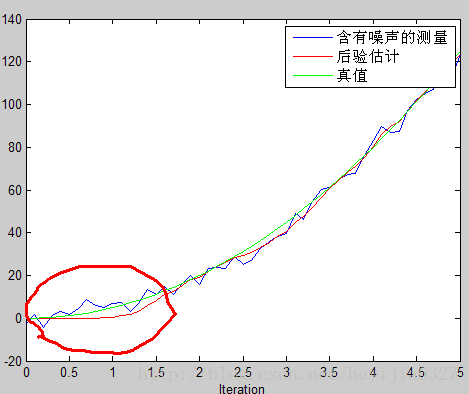
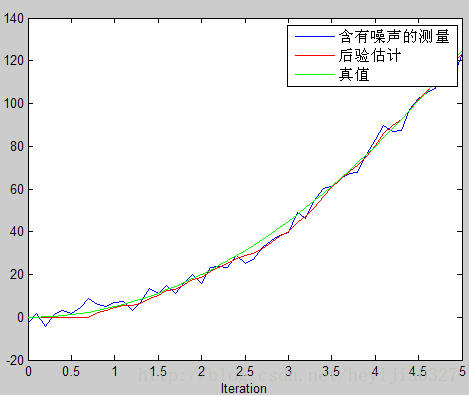
綠線為真實值,藍色的為噪聲很大的測量值,紅線為估計值。由此可以看出卡爾曼濾波確實相當犀利,提供了一個順滑的最優的估計。並請注意程式碼中,特地使得估計是從第9個
但這裡請注意影象中畫紅圈部分,由於一開始你預測值為0,而實際上不是(它已經運動9個時間間隔了),所以估計出的效果不好。在這裡回憶前面討論過的K值大小和估計的關係,既然預測不準,那麼一開始我就先相信測量唄。這就涉及估計值誤差協方差
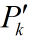
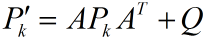
它又和估計誤差協方差矩陣
修改初值P=[2 0;0 2],估計影象如下,可以看到初始估計明顯改進了。(兩幅圖中,測量值相同,只改變了P)。這幅圖中紅色水平線那部分是前9個時間段,你還沒開始雷達追蹤,所以是水平的為0。
好了,到第二個問題,當狀態方程建立不正確的又會怎樣呢?實際應用中很多時候我們不能建立正確的狀態方程。
我們假設建立的狀態方程如下:
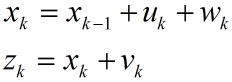
轉換矩陣A,B,H都等於1.這個模型明顯是不正確的。
注意這個時候的系統噪聲,就不單單只是系統內部產生的,還包括你建立狀態方程的不正確性。你建立的越不正確,根據你模型進行的預測就不正確,從這個角度來說,相當於你的噪聲增大了。所以這個時候系統噪聲W的方差應該增大。理解這一點,對改進實際估計效果有好處。接下來通過對比不同的W方差值設定給出對比,貼出這部分模擬如下。
- clc
- clear
- close all
- % 初始化引數
- delta_t=0.1;
- t=0:delta_t:5;
- g=10;%加速度值
- n_iter = length(t); % 序列的長度
- sz = [n_iter, 1]; % 訊號需開闢的記憶體空間大小
- x=1/2*g*t.^2;
- x=x';
- z = x + sqrt(10).*randn(sz); % 測量時加入測量白噪聲
- Q = 0.9; % 過程激勵噪聲方差
- %注意Q值得改變 待會增大到2,看看效果。對比看效果時,修改程式碼不要改變z的值
- R = 10; % 測量方差估計,可以改變它來看不同效果
- % 分配空間
- xhat=zeros(sz); % x的後驗估計
- P=zeros(sz); % 後驗方差估計
- xhatminus=zeros(sz); % x的先驗估計
- Pminus=zeros(sz); % 先驗方差估計
-
相關推薦
卡爾曼濾波 -- 從推導到應用(一) 到 (二)
/************************************************************************************************************************************
卡爾曼濾波 -- 從推導到應用(一)
前言 卡爾曼濾波器是在估計線性系統狀態的過程中,以最小均方誤差為目的而推匯出的幾個遞推數學等式,也可以從貝葉斯推斷的角度來推導。 本文將分為兩部分:第一部分,結合例子
卡爾曼濾波原理及應用(一)
出於科研需要,打算開始學習卡爾曼濾波(Kalmam Filter)。很早之前就聽說過卡爾曼濾波,但一直沒能深入學習,這次終於有機會了,哈哈。 1.卡爾曼濾波的發展過程 卡爾曼濾波的本質屬於"估計"範疇.先介紹下估計,所謂“估計”問題,就是對收到隨機干擾和隨機測量誤差作用的物理系統,按照某種效
卡爾曼濾波的理解以及推導過程
針對的系統為: 狀態方程 X(k)=AX(k-1)+Bu(k-1)+W(k-1) 測量方程 Z(k)=HX(k)+V(k) &
卡爾曼濾波(Kalman Filter)原理與公式推導
公式推導 領域 公式 不一定 技術 精度 原理 應用 定性 一、背景---卡爾曼濾波的意義 隨著傳感技術、機器人、自動駕駛以及航空航天等技術的不斷發展,對控制系統的精度及穩定性的要求也越來越高。卡爾曼濾波作為一種狀態最優估計的方法,其應用也越來越普遍,如在無人機、機器人等領
卡爾曼濾波基本原理及公式推導
一、卡爾曼濾波基本原理 既然是濾波,那肯定就是一種提純資料的東西。怎麼理解呢,如果現在有一個任務,需要知道家裡橘子樹今年長了多少個橘子。你想到去年、前年、大前年這三年你把橘子吃到過年,按每天吃3個來算,大概知道每年橘子樹產了多少橘子,今年的情況應該也差不多。這叫數學模型預測法;不過你懶得去想去年
023卡爾曼濾波方程的推導
博主參考嚴恭敏老師的講義進行學習卡爾曼濾波,在講義的基礎上加以詳細推導與說明。 首先給出隨機系統狀態空間模型(注意該模型沒有給出控制部分): (1){Xk=Φk/k−1Xk−1+Γk/k−1Wk−1Zk=HkXk+Vk \tag{1} \begin{ca
卡爾曼濾波(一)
舉個例子,上一時刻房間溫度最優值為26度,由於溫度變化緩慢,則可以根據經驗估計本次溫度也為26度,即四式右邊第一項,而此時溫度計讀數為28度,那麼本時刻溫度應該是多少?不知道溫度計精度的情況下,可以對兩個資料求平均,為27度,即T=26+0.5*(28-26)=27。這裡0.5就是本例子中的修正係數,那麼假如
無人駕駛汽車系統入門(一)——卡爾曼濾波與目標追蹤
前言:隨著深度學習近幾年來的突破性進展,無人駕駛汽車也在這些年開始不斷向商用化推進。很顯然,無人駕駛汽車已經不是遙不可及的“未來技術”了,未來10年
基於卡爾曼濾波演算法在三維球軌跡中跟蹤應用
關於卡爾曼濾波跟蹤演算法的理解文章實在太多,絕大多數都在敘述演算法原理和一些理解,而且一般舉例都限於一維直線運動或者二維平面運動,故在此不做過多的重複表述,有關原理理解性的文章請參考本部落格後的refe
卡爾曼濾波初探(一)
卡爾曼濾波初探 基於時域的線性模型預測 這裡先給出幾個概念(初看的時候很多部落格都沒有這方面說明,若你看到下面懵逼的時候,不妨上來再看看?) 預測:就是根據已有的①經驗、②公式、③以及上一個時間()下檢測物件的狀態的最優估計等資訊,從而得到一個對下一個
卡爾曼濾波原理及工具箱應用
在學習卡爾曼濾波器之前,首先看看為什麼叫“卡爾曼”。跟其他著名的理論(例如傅立葉變換,泰勒級數等等)一樣,卡爾曼也是一個人的名字,而跟他們不同的是,他是個現代人!卡爾曼全名Rudolf Emil Kalman,匈牙利數學家,1930年出生於匈牙利首都布達佩斯。1953,1954年於麻省理工學院分別獲
一個應用例項詳解卡爾曼濾波及其演算法實現
為了可以更加容易的理解卡爾曼濾波器,這裡會應用形象的描述方法來講解,而不是像大多數參考書那樣羅列一大堆的數學公式和數學符號。但是,他的5條公式是其核心內容。結合現代的計算機,其實卡爾曼的程式相當的簡單,只要你理解了他的那5條公式。在介紹他的5條公式之前,先讓我們來根據下面的例子一步一步的探索。假設我們要研究的
初學者的卡爾曼濾波——擴充套件卡爾曼濾波(一)
簡介 已經歷經了半個世紀的卡爾曼濾波至今仍然是研究的熱點,相關的文章不斷被髮表。其中許多文章是關於卡爾曼濾波器的新應用,但也不乏改善和擴充套件濾波器演算法的研究。而對演算法的研究多著重於將卡爾曼濾波應用於非線性系統。 為什麼學界要這麼熱衷於將卡爾曼濾波器用於非線性系統呢?因為卡爾曼濾波器從一開
MPU6050 + 一階互補濾波+二階互補濾波+卡爾曼濾波 +波形比較
1、卡爾曼濾波函式 void Kalman_Filter_X(float Accel, float Gyro) { Angle_X_Final += (Gyro - Q_bias_x) * dt; //先驗估計 Pdot[0] = Q_angle -
慣性導航——擴充套件卡爾曼濾波(一)
對於無人機的慣性導航系統,系統的狀態方程是非線性的,根據擴充套件卡爾曼濾波方程: Predict x^k|k−1Pk|k−1=f(x^k−1|k−1,uk−1)=Fk−1Pk−1|k−1FT
一階互補濾波,二階互補濾波,卡爾曼濾波
一階互補 // a=tau / (tau + loop time) // newAngle = angle measured with atan2 using the accelerometer //加速度感測器輸出值 // newRate = angle measured
卡爾曼濾波實現多項式擬合Matlab
nom and kalman ffi 樣本 矩陣 協方差 數組 fontsize %%%%%%%%%%%%%Q3:多項式系數估計%%%%%%%%%%%%%%%% %%%%%%%%%%2016/07/21%%%%%%%%%%%%%%%%%%% clc;clear;
卡爾曼濾波的一個簡單demo: 恒定加速度模型
obi vtt efk rtp end atp cee cdn bs4 p { margin-bottom: 0.1in; direction: ltr; color: rgb(0, 0, 10); line-height: 120%; text-align: left }