
Keras examples-imdb_cnn[利用卷積網路對文字分類]
1 任務描述
本實驗室利用卷積神經網路對imdb資料進行文字分類
2 實驗過程
(1)引入實驗中所涉及到的包
資料集包、資料預處理包、網路模型包、網路各層結構所對應的包
from __future__ import print_function
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense,Dropout,Activation
from keras.layers import Embedding
from (2)設定網路結構中的一些常數
主要包含了兩方面的常數:一是資料處理過程中,詞向量維度,詞彙表長度等相關的引數;二是網路結構中引數
# 設定詞彙表的長度,在資料預處理過程中,選擇詞彙字典中前max_features索引的詞彙。
max_features=5000
# 將每個句子填充或截斷至maxlen長度
maxlen=400
batch_size=32
# 設定詞向量的維度
embedding_dims=50
filters=250
kernel_size=3 (3)載入資料與資料預處理
print("loading data...")
(x_train,y_train),(x_test,y_test)=imdb.load_data(num_words=max_features)
print(len(x_train),"train sequences")
print(len(x_test),"test sequences")
print("pad sequences (samples*time)")
# 將每一條資料填充至相同的長度
x_train=sequence.pad_sequences(x_train,maxlen=maxlen)
x_test=sequence.pad_sequences(x_test,maxlen=maxlen)
print("x_train.shape:" loading data...
25000 train sequences
25000 test sequences
pad sequences (samples*time)
x_train.shape: (25000, 400)
x_test.shape: (25000, 400)
(4)建立模型
print("Build model...")
# 採用序列模型
model=Sequential()
# 新增詞嵌入層,詞嵌入層只能作為神經網路的第一層
model.add(Embedding(max_features,embedding_dims,input_length=maxlen))
model.add(Dropout(0.2))
model.add(Conv1D(filters,kernel_size,padding="valid",activation='relu',strides=1))
# 使用maxpooling
model.add(GlobalMaxPooling1D())
# 新增全連線層
model.add(Dense(hidden_dims))
model.add(Dropout(0.2))
model.add(Activation('relu'))
# 輸出層
model.add(Dense(1))
model.add(Activation("sigmoid"))
model.compile(loss="binary_crossentropy",optimizer='adam',metrics=['accuracy'])
model.fit(x_train,y_train,batch_size=batch_size,epochs=epochs,validation_data=(x_test,y_test))Build model...
Train on 25000 samples, validate on 25000 samples
Epoch 1/2
25000/25000 [==============================] - 64s 3ms/step - loss: 0.4040 - acc: 0.8005 - val_loss: 0.3088 - val_acc: 0.8657
Epoch 2/2
25000/25000 [==============================] - 63s 3ms/step - loss: 0.2305 - acc: 0.9086 - val_loss: 0.2977 - val_acc: 0.8765
(5)網路結構
from keras.utils import plot_model
plot_model(model,to_file="./imdb_cnn.png")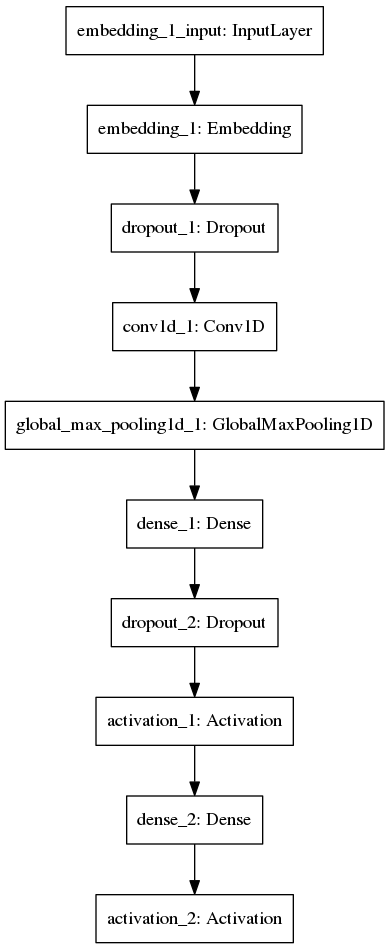
3 小結
這次實驗採用了卷積神經網路來對文字資料進行分類。而不是使用以往的RNN(LSTM/BiLSTM等),這樣實驗下來,對keras中其他結構的使用也進一步熟悉。在本實驗中,主要有以下幾點收穫:
(1)常用層的使用
(2)一維卷積層
一維卷積即為時域卷積,用以在一維輸入訊號上進行鄰域濾波。其原型為keras.layers.convolutional.Conv1D(filters, kernel_size, strides=1, padding=’valid’, dilation_rate=1, activation=None, use_bias=True, kernel_initializer=’glorot_uniform’, bias_initializer=’zeros’, kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
該層生成將輸入訊號與卷積核按照單一的空域(或時域)方向進行卷積。主要引數如下:
①filters:卷積核的數目(即輸出的維度)
②kernel_size:整數或由單個整數構成的list/tuple,卷積核的空域或時域窗長度
③strides:整數或由單個整數構成的list/tuple,為卷積的步長。
④padding:補0策略,為“valid”, “same” 或“causal”,“causal”將產生因果(膨脹的)卷積,即output不依賴於input。
⑤activation:啟用函式,為預定義的啟用函式名。