
深度學習:Keras入門(二)之卷積神經網路(CNN)
說明:這篇文章需要有一些相關的基礎知識,否則看起來可能比較吃力。
1.卷積與神經元
1.1 什麼是卷積?
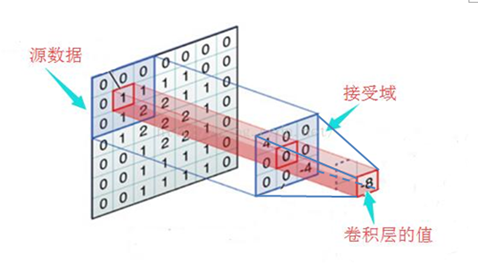
簡單來說,卷積(或內積)就是一種先把對應位置相乘然後再把結果相加的運算。(具體含義或者數學公式可以查閱相關資料)
如下圖就表示卷積的運算過程:
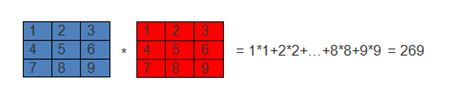
(圖1)
卷積運算一個重要的特點就是,通過卷積運算,可以使原訊號特徵增強,並且降低噪音.
1.2 啟用函式
這裡以常用的啟用函式sigmoid為例:
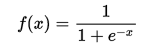
把上述的計算結果269帶入此公式,得出f(x)=1
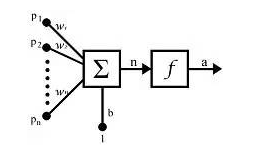
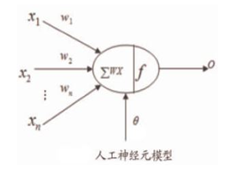
1.3 神經元
如圖是一個人工神經元的模型:

(圖2)
對於每一個神經元,都包含以下幾部分:
x:表示輸入
w:表示權重
θ:表示偏置
∑wx:表示卷積(內積)
f :表示啟用函式
o:表示輸出
1.4 影象的濾波操作
對於一個灰度圖片(圖3) 用sobel運算元(圖4)進行過濾,將得到如圖5所示的圖片。

1.5小結
上面的內容主要是為了統一一下概念上的認識:
圖1的藍色部分、圖2中的xn、圖3的影象都是神經元的輸入部分;圖1的紅色部分數值值、圖2的wn值、圖4的矩陣值都可以叫做權重(或者濾波器或者卷積核,下文統稱權重)。而權重(或卷積核)的大小(如圖4的3×3)叫做接受域(也叫感知野或者資料視窗,下文統稱接受域)
2.卷積神經網路
在介紹卷積神經網路定義之前,先說幾種比較流行的卷積神經網路的結構圖。
2.1 常見的幾種卷積神經網路結構圖
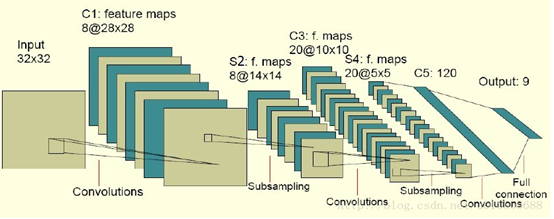
(圖6)
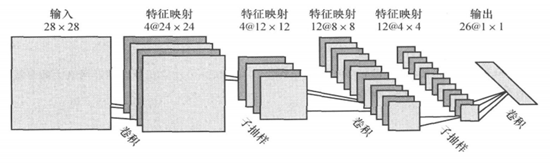
(圖7)
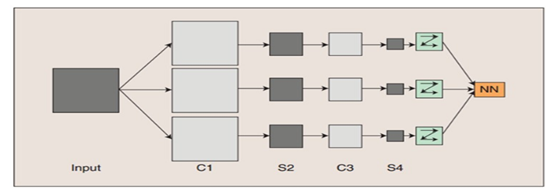
(圖8)
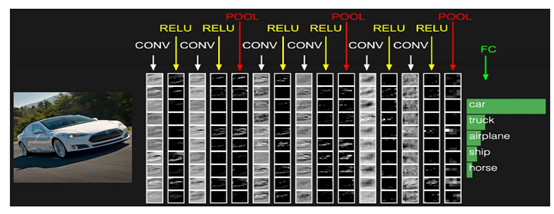
(圖9)
圖8中的C-層、S-層是6中的Convolutions層和subsampling層的簡寫,C-層是卷積層,S-層是子抽樣和區域性平均層。在圖6和圖7中C-層、S-層不是指具體的某 一個層,而是指輸入層和特徵對映層、特徵對映層和特徵對映層之間的計算過程,而特徵對映層則保持的是卷積、子抽樣(或下采樣)和區域性平均的輸出結果。而圖 6和圖7的區別在於最終結果輸出之前是否有全連線層,而有沒有全連線層會影響到是否還需要一個扁平層(扁平層在卷積層和全連線層之間,作用是多維資料一維化)。
圖9中CONV層是卷積層(即C-層),但是新出現的RELU層和POOL層是什麼呢?RELU層其實是啟用層(relu只是啟用函式的一種,sigmoid/tanh比較常見於全連線層,relu常見於卷積層),為什麼會多出來一個啟用層呢?請看下圖:
(圖10) (圖2,方便對比複製了過來)
神經元的完整的數學建模應該是圖10所示,與圖2相比,把原來在一起的操作拆成了兩個獨立的操作:∑wx(卷積)和f(啟用),因此多出了一個啟用層。所以,在Keras中組建卷積神經網路的話,即可以採用如圖2的方式(啟用函式作為卷積函式的一個引數)也可採用圖10所示的方式(卷積層和啟用層分開)。啟用層不需要引數。
Pool層,即池化層,其作用和S-層一樣:進行子抽樣然後再進行區域性平均。它沒有引數,起到降維的作用。將輸入切分成不重疊的一些 n×n 區域。每一個區域就包含個值。從這個值計算出一個值。計算方法可以是求平均、取最大 max 等等。假設 n=2,那麼4個輸入變成一個輸出。輸出影象就是輸入影象的1/4大小。若把2維的層展平成一維向量,後面可再連線一個全連線前向神經網路。
從圖7可以看出,無論是卷積層還是池化層都可以叫做特徵對映層,而兩層之間的計算過程叫做卷積或者池化,但是這麼表述容易在概念上產生混淆,所以本文不採用這種表述方式,只是拿來作為對比理解使用。
下面對上面的內容做一下總結:
卷積層(C-層或Convolutions層或CONV層或特徵提取層,下文統稱卷積層):主要作用就是進行特徵提取。
池化層(S-層或子抽樣區域性平均層或下采樣區域性平均層或POOL層,下文統稱池化層):主要作用是減小特徵圖,起到降維的作用。常用的方法是選取區域性區域的最大值或者平均值。如下圖所示:
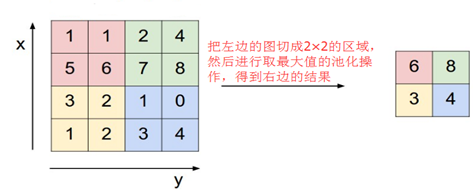
(圖11)
對於第一個卷積層來說(圖6的C1-層),一個特徵對應一個通道(或叫feature map或特徵對映或者叫濾波器,下文統稱特徵對映),例如三原色(RGB)的影象就需要三個特徵對映層。但是經過第一個池化層(圖6的S2-層,PS:圖中錯標成了S1-層)之後,下一個特徵提取層 (圖6的C3-層)的特徵對映 (feature map)個數並不一定與開始的相同了(圖6中從8特徵變成了20特徵),一般情況下會比初始的特徵對映個數多,因為根據視覺系統原理----底層的結構構成上層更抽象的結構,所以當前層的特徵對映是上一層的特徵對映的組合,也就是一個特徵對映會對應上一層的一個或多個特徵對映。
2.2 接受域和步長
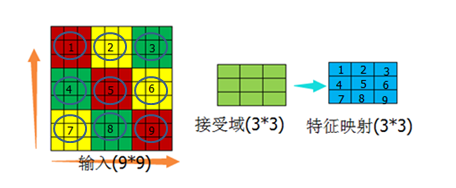
2.2.1 接受域
(圖12)
如圖所示,中間的正方形都表示接受域,其大小為5*5。這裡再重複一下:權重(卷積核)指的是數字,接受域指的是權重(卷積核)的大小。
2.2.2 步長
(圖13)
接受域的對應範圍從輸入的區域1移到區域2的過程,或者從區域3移動到區域4都涉及到一個引數:步長,即每次移動的幅度。在此例中的步長可以表示成3或 者(3,3),單個3表示橫縱座標方向都移動3個座標點,如果(3,2)則表示橫向移動3個座標點,縱向移動2個座標點。每次移動是按一個方向移動,不是兩個方向都移 動(圖13中,從區域1移動到區域2、區域3,然後才移動到區域4,如果兩個方向都移動三個座標點則從區域1到了區域5,是不對的)。
2.3卷積神經網路
2.3.1卷積神經網路定義
卷積神經網路是一個多層的神經網路,每層由多個二維平面(特徵對映)組成,而每個平面由多個獨立神經元組成。
2.3.2卷積神經網路特點
卷積神經網路是為識別二維形狀而特殊設計的一個多層感知器,這種網路結構對二維形狀的平移、比例縮放、傾斜或者共他形式的變形具有高度不變性。
卷積神經網路是前饋型網路。
2.3.3 卷積神經網路的形式的約束
2.3.3.1 特徵提取
每一個神經元從上一層的區域性接受域得到突觸輸人,因而迫使它提取區域性特徵。一旦一個特徵被提取出來,只要它相對於其他特徵的位置被近似地保留下來,它的精確位置就變得沒有那麼重要了。
下圖兩個X雖然有點稍微變形,但是還是可以識別出來都是X。

(圖14)
2.3.3.2 特徵對映
網路的每一個計算層都是由多個特徵對映組成的,每個特徵對映都是平面形式的。平面中單獨的神經元在約束下共享相同的突觸權值集(權重),這種結構形式具有如下的有益效果:
a.平移不變性(圖14的兩個X)
b.自由引數數量的縮減(通過權值共享實現)
這裡重點說下共享權值,以及卷積層神經單元個數的確定問題。
以圖12的結構為基礎,做以下假設:
假設一:輸入範圍在橫縱方向與接受域正好是倍數關係
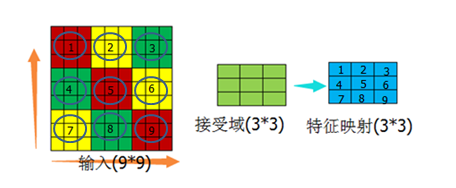
(圖15)
先說沒有接受域的情況,如果特徵對映有9個神經元,這9個神經元與9*9的輸入做全連線,那麼需要的權重個數為9*9*9=729個。添加了接受域後,9個神經元 分別與接受域做連結,這種情況下如果一個神經元對應一組權重,則有9*9=81個權重值,再假如這一組權重的值是固定的(可參考圖12的接受域值,這組值不變,而不是每個值相等),那麼就只剩下了9個權重值。從729個權重值減少到9個權重值,這個過程就是權值共享的過程。也許從729減少到9個,差別不是特別大,如果輸入是1000*1000,神經元個數是1000萬呢?這樣的話由權值共享導致的減少的計算量就很客觀了。
假設二:輸入範圍在橫縱方向與接受域不是是倍數關係
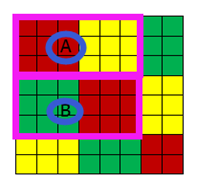
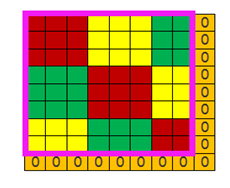
(圖16 ) (圖17)
以圖15為參考,只是把輸入域變成圖16所示的8*8的情況,若步長還是(3,3),那麼橫縱向各移動一次後就無法移動了,即接受域的可視範圍為粉色邊框內的6*6的區域(圖16的粉紅框A區域和B區域),外側的2行2列的資料是讀不到的。這種情況有兩種處理方式,一是直接放棄,但是這種方式幾乎不用,另外一種方式在周圍補0(圖17所示),使輸入域變成(3,3)的倍數。
通過上述內容,可以知道每個特徵對映的神經元的個數是由輸入域大小、接受域、步長共同決定的。如圖15,9*9的輸入域、3*3的接受域、(3,3)的步長,可 以計算出特徵對映的神經元個數為9個。
2.3.3.3 子抽樣
每個卷積層後面跟著一個實現區域性平均和子抽樣的計算層(池化層),由此特徵對映的解析度降低。這種操作具有使特徵對映的輸出對平移和其他形式的變形 的敏感度下降的作用。
3.用Keras構建一個卷積神經網路
3.1 卷積神經網路結構圖
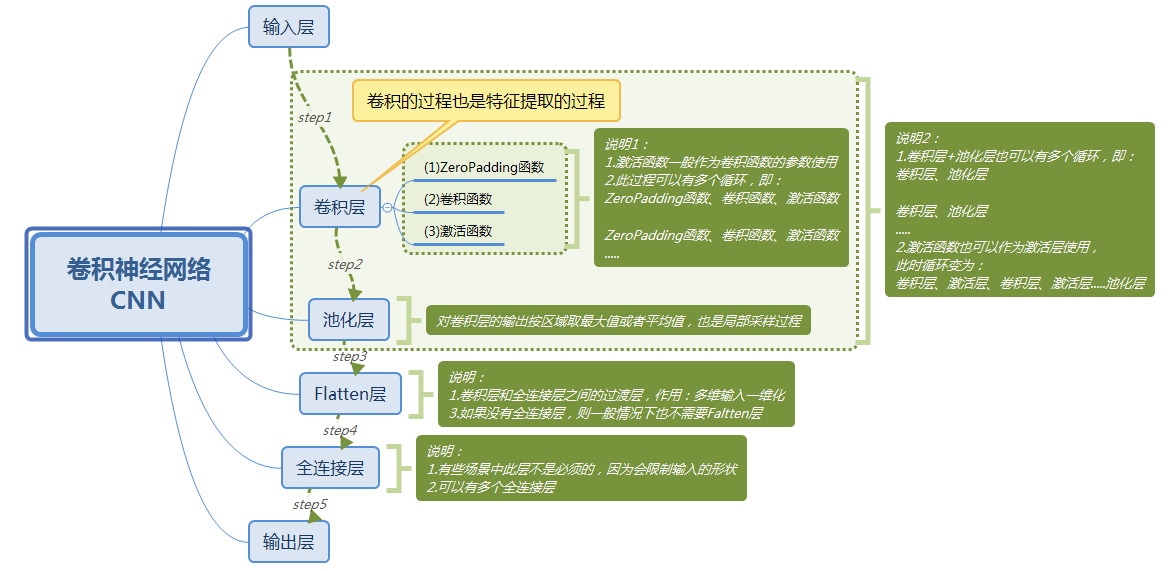
(圖18)
3.2 Keras中的輸入及權重
3.2.1 示例程式碼(小數字方便列印驗證)
PS:Convolution2D 前最好加ZeroPadding2D,否則需要自己計算輸入、kernel_size、strides三者之間的關係,如果不是倍數關係,會直接報錯。

model = Sequential() model.add(ZeroPadding2D((1, 1), batch_input_shape=(1, 4, 4, 1))) model.add(Convolution2D(filters=1,kernel_size=(3,3),strides=(3,3), activation='relu', name='conv1_1')) model.layers[1].get_weights() model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(filters=1,kernel_size=(2,3),strides=(2,3), activation='relu', name='conv1_2')) model.layers[3].get_weights()
3.2.2 程式碼解釋
1) batch_input_shape=(1, 4, 4, 1)
表示:輸入1張1通道(或特徵對映)的4*4的資料.因為我採用的是用Tensorflow做後端,所以採用“channels_last”資料格式。
2) filters = 1
表示:有1個通道(或特徵對映)
3) kernel_size = (2,3)
表示:權重是2*3的矩陣
4) striders = (2,3)
表示:步長是(2,3)
3.2.3 權重(預設會初始化權重)
3.2.3.1 第一個model.layers[1].get_weights()輸出(格式整理後)

(圖19)
3.2.3.2 第二個model.layers[1].get_weights()輸出
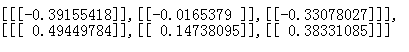
(圖20)
3.2.3.3 另外兩個輸出(沒有寫的引數值同上)
1)batch_input_shape=(1, 4, 4, 3),filters = 1, kernel_size = (3,3)

(圖21)
2) batch_input_shape=(1, 4, 4, 3),filters = 3, kernel_size = (2,3)

(圖22)
3.2.4 小結
圖19到圖22的內容是為了說明在Keras中權重的表示方式,為下面的實驗做準備。
通過以上引數得出的權重對比,當權重是二維矩陣(n*n)時:
1) [[[…]]]:表示橫軸數目
2) [[…]]:表示縱軸數目
3) […]:表示通道的個數。圖21和圖22的區別:因為圖22是3通道3filter,所以每個通道對應一個filter(圖20),而圖22相當於把3個圖20合一起了。
4) […]內逗號隔開的數:filter的個數
5) [[[[…]]]]:這個可能代表層數(前面幾個引數是平面的,這個引數是立體的。在下面的實驗中沒有得到具體驗證,只是根據最外層是5個方括號推測的)
3.3 sobel運算元轉化成權重
由3.2.4的結論,可以把圖4的sobel運算元轉換成Keras中的權重:
weights = [[[[[-1]],[[0]],[[1]]],[[[-2]],[[0]],[[2]]],[[[-1]],[[0]],[[1]]]]]
weights =np.array(weights)
PS:注意最外圍是5個方括號
3.4 實驗程式碼
from PIL import Image
import numpy as np
from keras.models import Sequential
from keras.layers import Convolution2D, ZeroPadding2D, MaxPooling2D
from keras.optimizers import SGD
'''
第一步:讀取圖片資料
說明:這個過程需要安裝pillow模組:pip install pillow
'''
##1張1通道的256*256的灰度圖片
##data[0,0,0,0]:表示第一張圖片的第一個通道的座標為(0,0)的畫素值
img_width, img_height = 256, 256
data = np.empty((1,1,img_width,img_height),dtype="float32")
##開啟圖片
img = Image.open("D:\\keras\\lena.jpg")
##把圖片轉換成陣列形式
arr = np.asarray(img,dtype="float32")
data[0,:,:,:] = arr
'''
第二步:設定權重
說明:注意最外圍是5個方括號
'''
weights = [[[[[-1]],[[0]],[[1]]],[[[-2]],[[0]],[[2]]],[[[-1]],[[0]],[[1]]]]]
weights =np.array(weights)
'''
第三步:組織卷積神經網路
說明:
1.因為實驗採用的是預設的tensorflow後端,而輸入影象是channels_first模式,所以注意data_format引數的設定
2.為了實驗的效果,所以strides、pool_size等引數設定成了1
'''
##第一次卷積
model = Sequential()
model.add(ZeroPadding2D(padding=(2, 2), data_format='channels_first', batch_input_shape=(1, 1,img_width, img_height)))
model.add(Convolution2D(filters=1,kernel_size=(3,3),strides=(1,1), activation='relu', name='conv1_1', data_format='channels_first'))
model.set_weights(weights)
##第二次卷積
model.add(ZeroPadding2D((1, 1)))
model.add(Convolution2D(filters=1,kernel_size=(3,3),strides=(1,1), activation='relu', name='conv1_2',data_format='channels_first'))
model.set_weights(weights)
##池化操作
model.add(ZeroPadding2D((0, 0)))
model.add(MaxPooling2D(pool_size=1, strides=None,data_format='channels_first'))
'''
第四步: 設定優化引數並編譯網路
'''
# 優化函式,設定學習率(lr)等引數
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
# 使用mse作為loss函式
model.compile(loss='mse', optimizer=sgd, class_mode='categorical')
'''
第五步:預測結果
'''
result = model.predict(data,batch_size=1,verbose=0)
'''
第六步:儲存結果到圖片
'''
img_new=Image.fromarray(result[0][0]).convert('L')
img_new.save("D:\\keras\\tt123.jpg")
3.5 實驗效果


(圖23) (圖24)
圖24是池化層引數改為pool_size=2時的效果。