
經典的觀點挖掘演算法(文字挖掘系列)
阿新 • • 發佈:2019-01-31
最近閱讀了一篇關於觀點挖掘的KDD論文(Mining and Summarizing Customer Reviews,KDD04),其挖掘演算法很經典,特此做記錄。
該論文要解決的問題是,識別使用者評論的情感(positive or negative),並作歸納,為使用者購買產品提供真實有效的參考。歸納的形式如下(以數碼相機為例):
數碼相機:
特徵: 照片質量
Positive: 253
<使用者評論的句子>
Negative: 8 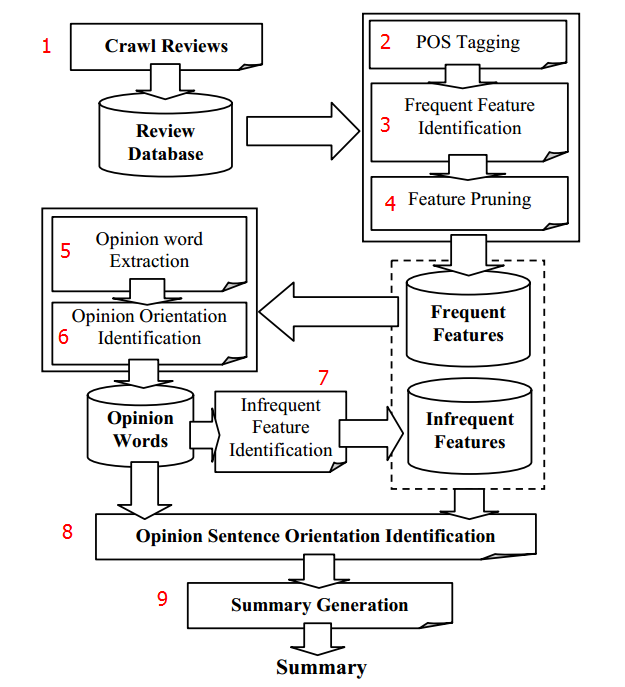 (1) Crawl Reviews:
第一步當然就是爬蟲,從網站上抓取使用者評論並存儲。
(2) POS Tagging:
使用NLProcessor或StanFord Parser(推薦使用)對使用者的每一句評論打POS標籤,POS標籤會給每個詞標註詞性,就像這樣:
I/FW recently/RB purchased/VBD the/DT canon/JJ powershot/NN g3/NN and/CC am/VBP extremely/RB satisfied/VBN
with/IN the/DT purchase/NN ./.
(1) Crawl Reviews:
第一步當然就是爬蟲,從網站上抓取使用者評論並存儲。
(2) POS Tagging:
使用NLProcessor或StanFord Parser(推薦使用)對使用者的每一句評論打POS標籤,POS標籤會給每個詞標註詞性,就像這樣:
I/FW recently/RB purchased/VBD the/DT canon/JJ powershot/NN g3/NN and/CC am/VBP extremely/RB satisfied/VBN
with/IN the/DT purchase/NN ./.
(1) Crawl Reviews:
第一步當然就是爬蟲,從網站上抓取使用者評論並存儲。
(2) POS Tagging:
使用NLProcessor或StanFord Parser(推薦使用)對使用者的每一句評論打POS標籤,POS標籤會給每個詞標註詞性,就像這樣:
I/FW recently/RB purchased/VBD the/DT canon/JJ powershot/NN g3/NN and/CC am/VBP extremely/RB satisfied/VBN
with/IN the/DT purchase/NN ./.